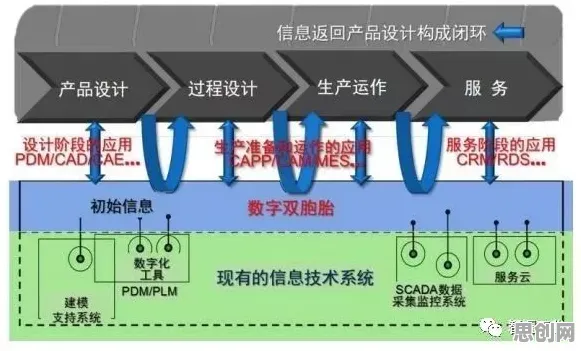
多模态数据融合:打破工业场景的"数据孤岛"
热度持续增强绿色制造热度持续上升,相关产业迎来新机遇 工业数字孪生的核心是构建物理实体与虚拟模型的实时映射,但传统方案往往受限于单一数据源,2026年,生成式AI的多模态处理能力成为突破口——它不仅能整合传感器时序数据、设备日志文本,还能解析设备3D点云、工艺图纸等非结构化数据。
案例:三一重工的"黑灯工厂"改造
2026年初,三一重工在长沙的18号工厂部署了基于多模态生成式AI的数字孪生系统,该系统通过大语言模型解析设备维护手册中的文本指令,结合计算机视觉模型识别机械臂运动轨迹的3D点云数据,再与振动传感器采集的时序信号进行时空对齐,最终生成的孪生模型能提前48小时预测液压系统故障,使设备综合效率(OEE)提升22%。
"过去需要人工标注的3000小时数据,现在通过生成式AI自动生成合成数据,模型训练周期缩短了70%。"三一重工智能制造研究院院长王某表示。
但多模态融合并非万能,某汽车零部件厂商曾尝试用生成式AI同时处理焊接机器人视频流与电流传感器数据,却因两种数据的采样频率差异(视频25fps vs 传感器1000Hz)导致模型出现"时间错位"幻觉,最终不得不回归传统时序对齐方法。
物理约束生成:让虚拟模型"接地气"
生成式AI的"想象力"在工业场景中可能成为双刃剑——若缺乏物理规律约束,生成的虚拟模型会陷入"数据幻觉",2026年,行业普遍采用"数据驱动+物理引擎"的混合建模方案。
案例:西门子安贝格工厂的电路板检测
西门子在安贝格电子制造工厂部署的数字孪生系统,通过生成式AI生成数万种虚拟电路板缺陷样本,但所有样本均需通过电磁仿真引擎验证其物理合理性,当AI生成一个"焊点虚焊"样本时,系统会自动计算该缺陷对信号完整性的影响,只有符合实际物理规律的样本才会被用于训练检测模型。
"这相当于给生成式AI装上了'物理刹车'。"西门子数字化工业集团CTO托马斯·克劳泽解释,"2026年我们的模型误检率已从2023年的3.2%降至0.7%,关键就在于物理约束生成技术。"
本月5G通信与美妆护肤及绿色价值链热度持续走高,行业关注度持续提升 
本月碳汇与可持续发展热度持续攀升,相关领域迎来新突破 物理引擎的引入也带来新挑战,某风电企业曾因仿真引擎的流体力学模型精度不足,导致生成的叶片振动数据与实际偏差达18%,最终不得不联合高校重新开发高精度物理内核。
动态边界调整:应对工业环境的"不确定性"
传统数字孪生模型通常基于固定工艺参数训练,但2026年的柔性制造需求要求模型具备动态适应能力,生成式AI的强化学习分支在此展现价值——它能让模型在运行中持续学习边界条件变化。
案例:宝钢股份的冷轧产线优化
宝钢股份在上海的冷轧产线部署了动态边界数字孪生系统,当来料钢卷的厚度波动超出历史数据范围时,生成式AI模型会通过强化学习动态调整轧制力参数,同时生成新的工艺边界条件供后续批次参考,2026年一季度数据显示,该系统使厚度偏差控制精度从±3μm提升至±1.2μm,吨钢能耗降低8.7%。
"这就像给模型装上了'自适应大脑'。"宝钢中央研究院首席研究员李某比喻,"过去需要工程师手动调整的200多个参数,现在模型能自主优化其中83个。"
但动态调整的代价是计算资源消耗激增,某化工企业曾尝试在反应釜控制中应用类似技术,却因模型实时推理需要16块A100 GPU,最终不得不采用"边缘+云端"混合部署方案。
2026年元宇宙与生物识别及互联网医疗热度持续上升,相关产业迎来新发展 
小样本学习:破解工业数据的"稀缺困境"
工业场景中,故障样本往往稀缺——一台关键设备可能数年才出现一次严重故障,2026年,生成式AI的小样本学习技术成为破解这一难题的关键。
案例:中车株机的牵引电机故障预测
中车株机为某型号高铁牵引电机开发的数字孪生系统,仅用5个历史故障样本就训练出可用模型,其秘诀在于生成式AI的"故障特征迁移"技术:先通过正常数据训练基础模型,再利用少量故障样本生成大量"虚拟故障特征",最后通过对比学习区分正常与异常状态,2026年实测显示,该系统对轴承保持架断裂的预测准确率达92%,而传统方法需要至少50个故障样本才能达到类似效果。
"这相当于用生成式AI'放大'了故障信号。"中车株机智能运维总监陈某说,"在高铁这种安全要求极高的场景,这种技术价值无法估量。"
小样本学习对数据质量极度敏感,某半导体厂商曾因传感器校准偏差,导致生成的虚拟故障特征与实际偏差达30%,最终模型在现场部署时完全失效。
可解释性增强:让AI决策"透明化"
工业场景对模型可解释性的要求远高于消费领域——工程师需要知道"为什么AI建议调整这个参数",2026年,生成式AI与知识图谱的结合成为主流解决方案。

案例:国家电网的变压器运维决策
国家电网在特高压变压器运维中部署的数字孪生系统,通过生成式AI生成维护建议后,会自动关联设备台账、历史工单、行业标准等知识图谱数据,生成可视化的决策路径图,当模型建议"更换分接开关油枕"时,系统会同时显示:"根据DLT 573-2021标准第4.3条,油枕密封性检测不合格是更换依据;同类设备在2023-2025年间有12起类似故障记录。"
"这解决了工程师对AI的信任问题。"国家电网设备部副主任王某表示,"2026年我们的AI决策采纳率从2023年的41%提升至78%,关键就在于可解释性增强技术。"
但可解释性增强会降低模型推理速度,某汽车厂曾因追求完全可解释性,导致数字孪生系统的实时性从100ms降至500ms,最终不得不在解释性与性能间寻找平衡点。
技术部署的"隐形门槛"
尽管生成式AI为数字孪生带来突破,但2026年的行业实践显示,技术部署仍面临三大隐形门槛:
- 数据治理成本:某石化企业统计显示,构建可用数字孪生系统的成本中,数据清洗与标注占比达62%,远高于模型训练的18%。
- 人才缺口:麦肯锡2026年调研显示,83%的工业企业缺乏既懂工艺又懂AI的复合型人才,导致技术落地周期延长40%以上。
- 安全风险:某汽车零部件厂商的数字孪生系统曾在2026年3月遭遇数据投毒攻击,攻击者通过篡改传感器数据训练出错误模型,导致批量产品缺陷。
"数字孪生不是'交钥匙工程'。"波士顿咨询全球工业团队负责人汉斯·穆勒强调,"2026年的成功案例都有一个共同点:企业将技术部署视为持续迭代的组织变革,而非一次性项目。"
在2026年的工业现场,数字孪生与生成式AI的融合正在重塑生产逻辑——从设备维护到工艺优化,从质量控制到供应链协同,技术的边界不断被突破,但真正的挑战不在于技术本身,而在于企业能否构建起支撑技术落地的数据基础、人才体系与安全框架,当这些基础要素到位时,生成式AI才能从"炫技工具"真正转化为工业变革的核心引擎。