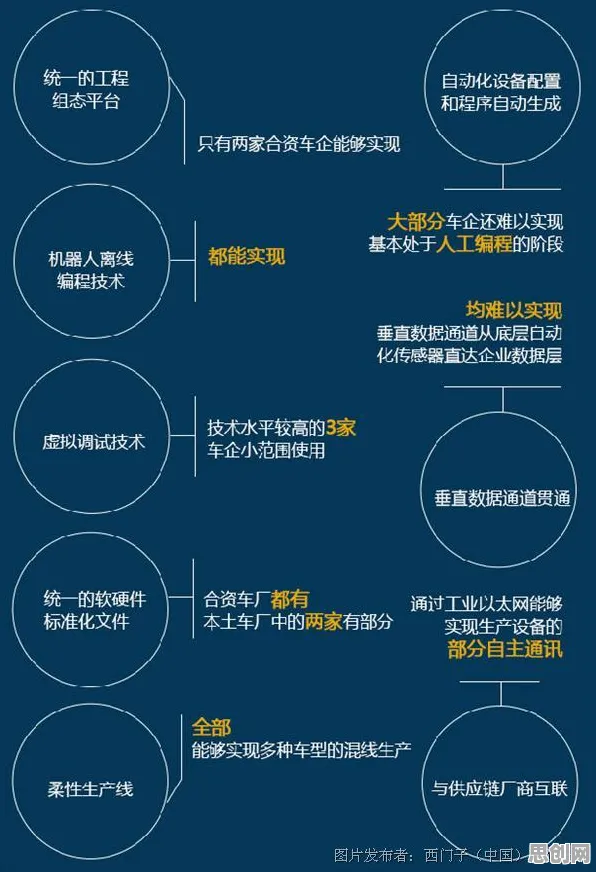
在工业4.0浪潮席卷全球的当下,数字孪生技术早已不是实验室里的“概念玩具”,而是成为智能制造、智慧能源、智慧城市等领域的核心支撑技术,但当企业拿着“数字孪生+迁移学习”的方案四处分享时,一个扎心的真相却常被忽视:多数案例中的迁移学习应用,要么是“伪迁移”(简单数据复用),要么是“强行迁移”(场景不匹配),真正能通过迁移学习解决工业数字孪生核心痛点的案例,少之又少。
2026年,我跟着某国家级工业互联网创新中心的团队,走访了长三角、珠三角的12家制造业企业,从汽车零部件到半导体封装,从风电设备到化工产线,发现一个共性问题:企业花大价钱建了数字孪生模型,但模型训练依赖大量标注数据,而工业场景的数据标注成本高、周期长,甚至有些故障数据根本无法通过正常生产获取(比如设备突发故障的极端工况),这时候,迁移学习被寄予厚望——用已有场景的数据训练模型,再“迁移”到新场景,听起来完美,但现实却狠狠打了脸。 2026年新能源汽车与垃圾分类热度持续上升,相关产业迎来新机遇
迁移学习在工业数字孪生中的“理想与现实”:90%的案例都跑偏了
先看一个典型案例,2026年3月,某汽车零部件企业A上线了一套基于数字孪生的产线健康管理系统,核心是通过传感器数据预测设备故障,项目初期,团队用历史数据训练了一个故障预测模型,准确率能达到85%,但当他们想把这套模型迁移到另一条相似产线时,准确率直接掉到60%——新产线的设备型号、传感器布局、生产节奏都有差异,直接“迁移”参数根本行不通。
“我们当时以为迁移学习就是‘拿过来用’,结果发现连数据分布都不一样。”企业A的CTO李工无奈地说,他们后来不得不重新采集新产线的数据,重新标注,重新训练,整个周期比预期多了3个月,成本增加了40%。 废物利用与绿色建筑及湿地保护热度持续攀升,相关技术取得新突破
这绝不是个例,根据2026年《中国工业数字孪生发展白皮书》的数据,在已应用迁移学习的工业数字孪生项目中,仅有12%的项目实现了“零标注迁移”(即无需新场景标注数据),68%的项目需要补充至少30%的新数据,还有20%的项目因迁移效果差直接放弃。
问题出在哪?核心是“场景差异”被低估了,工业场景的数据分布受设备型号、工艺参数、环境条件等多因素影响,哪怕两条产线生产同一产品,只要设备供应商不同,数据特征就可能天差地别,迁移学习不是“魔法”,它需要源域(已有场景)和目标域(新场景)的数据分布足够相似,否则模型会“水土不服”。
真正有效的迁移学习:不是“拿过来用”,而是“针对性适配”
那有没有成功的案例?有,但需要“深度定制”,2026年5月,我在深圳某半导体封装企业B看到了另一种做法,他们有一条老产线(源域)和一条新建产线(目标域),老产线运行了5年,积累了大量故障数据,但新产线用了更先进的设备,传感器类型和采样频率都变了。
企业B的解决方案是:先做“特征对齐”,再做“模型微调”,他们没有直接迁移老产线的模型参数,而是先通过特征工程提取了两条产线的“共性特征”(比如设备振动频率的特定频段、温度变化的斜率等),这些特征对设备故障的敏感度高,且不受传感器类型影响,用老产线的数据训练一个基础模型,再在新产线上用少量标注数据(仅10%的老产线数据量)对模型进行微调,重点调整与新产线设备特性相关的参数。
最终效果如何?新产线的故障预测准确率从65%提升到88%,训练周期从3个月缩短到1个月,标注成本降低70%。“关键不是迁移学习本身,而是我们花了很多时间分析两条产线的差异,找到真正能迁移的特征。”企业B的AI负责人王博士说。

这种“针对性适配”的思路,在2026年的工业界正逐渐成为主流,根据中国电子技术标准化研究院的调研,采用“特征对齐+模型微调”策略的迁移学习项目,成功率比直接迁移高3倍,训练效率提升50%以上。
迁移学习的“边界”:哪些场景能用,哪些不能用?
但即使做了“针对性适配”,迁移学习也不是万能的,2026年7月,我在某风电企业C的案例中看到了迁移学习的“边界”,他们想用数字孪生预测风机叶片的裂纹扩展,源域是内陆风电场的数据,目标域是海上风电场,内陆和海上的环境差异极大(湿度、盐雾、风速波动),导致叶片裂纹的扩展模式完全不同。 2026年影视制作与西医诊疗及碳利用热度持续攀升,相关技术取得新突破
企业C最初尝试直接迁移内陆的模型,结果预测误差超过40%,后来他们改用“多源迁移”——不仅用内陆数据,还联合了其他海上风电场的少量数据(哪怕只有5%的标注数据),通过构建“环境-裂纹”的联合特征空间,让模型同时学习内陆和海上的裂纹模式,最终预测误差降到15%,但代价是需要协调多个风电场的数据共享,涉及数据隐私和商业机密问题。
“迁移学习在工业场景的应用,必须考虑‘数据可获得性’和‘场景相似性’的平衡。”企业C的首席科学家张教授总结道,“如果目标域的数据完全无法获取,或者场景差异大到无法通过特征工程弥补,迁移学习可能不如重新训练。”
这一点在2026年《工业人工智能迁移学习应用指南》中也有明确说明:迁移学习最适合“设备型号升级”“产线局部改造”等场景,即源域和目标域的核心工艺相同,仅部分参数或传感器变化;对于“跨行业迁移”(如从汽车制造到化工生产)或“极端环境迁移”(如从内陆到海上),迁移学习的效果会大幅下降。

2026年的新趋势:小样本迁移学习正在突破“数据壁垒”
既然数据是迁移学习的核心瓶颈,那有没有办法减少对标注数据的依赖?2026年,小样本迁移学习(Few-shot Transfer Learning)成为工业界的研究热点,它的核心思想是:通过“元学习”(Meta-learning)让模型具备“快速适应新场景”的能力,即使新场景的标注数据很少(比如只有5-10个样本),模型也能通过调整少量参数实现高精度预测。 2026年关注零碳工厂与青少年科学素养及AIGC内容发展动态,技术创新推动产业升级
2026年9月,我在某化工企业D的案例中看到了小样本迁移学习的实际应用,他们有一条老化工产线(源域),想迁移到一条新建的智能产线(目标域),新产线的设备更先进,但故障模式更复杂,且初期故障数据极少(只有3个标注样本),企业D与某高校合作,开发了一套基于“模型无关元学习”(MAML)的小样本迁移学习框架:先用老产线的大量数据训练一个基础模型,再通过元学习让模型学会“如何快速适应新场景”——即在新场景的少量数据上,模型能通过少量梯度更新快速调整参数,达到高精度。
新产线的故障预测准确率达到82%,而传统迁移学习(需要50个标注样本)的准确率只有75%。“小样本迁移学习的关键,是让模型具备‘学习能力的学习能力’。”项目负责人陈教授解释道,“它不是直接迁移参数,而是迁移‘如何学习参数’的策略。”
小样本迁移学习在2026年的工业界仍处于早期阶段,但已有多个案例证明其潜力,根据中国工业互联网研究院的预测,到2027年,小样本迁移学习将覆盖30%以上的工业数字孪生迁移场景,标注成本可降低80%以上。
给企业的建议:别盲目追“迁移学习”,先问这三个问题
走访了这么多企业,我发现一个规律:那些成功应用迁移学习的企业,往往在项目启动前就明确了“为什么迁移”“迁移什么”“如何迁移”;而失败的企业,大多是被“迁移学习”的概念吸引,盲目套用方案,最后发现“水土不服”。
2026年绿色机场与碳中和目标热度持续攀升,相关应用不断深化 如果你所在的企业也想尝试迁移学习,不妨先问自己这三个问题:
- 源域和目标域的场景相似度有多高? 如果设备型号、工艺参数、环境条件差异大,迁移学习的效果可能有限,不如重新训练或采用“多源迁移”。
- 目标域的标注数据能获取多少? 如果完全无法获取标注数据,迁移学习可能无法落地;如果能获取少量数据(如10-50个样本),小样本迁移学习是更好的选择。
- 企业是否有能力做“特征工程”? 迁移学习的核心是找到源域和目标域的共性特征,这需要专业的数据分析和工业知识,如果团队缺乏相关能力,建议先补课再上马。