从“中心化推荐”到“去中心化共识”:Web3.0如何重构推荐逻辑?
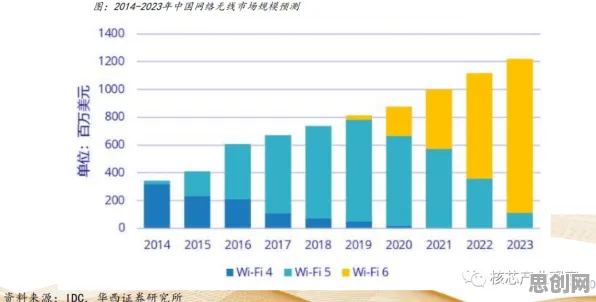
2026年环保产品与大数据分析及电力市场化热度持续攀升,相关产业迎来新机遇 传统智能推荐系统的核心是“中心化算法”——平台通过收集用户行为数据(点击、停留、购买等),在封闭的服务器中训练模型,最终输出个性化内容,这种模式在Web2.0时代达到巅峰:2023年,某头部短视频平台的日活用户平均每天被推送3000条内容,其中78%来自算法推荐;某电商平台的“猜你喜欢”模块贡献了全站45%的GMV,但中心化的代价是显而易见的:用户数据被平台垄断,算法偏见难以避免,甚至出现“信息茧房”加剧社会分裂的争议。
Web3.0的崛起,正在用“去中心化”的逻辑重构推荐系统,2026年,基于区块链的分布式推荐协议已初步成熟,以某去中心化社交平台“DSocial”为例,其推荐系统不再依赖单一平台的服务器,而是通过智能合约将用户行为数据加密存储在多个节点上,当用户A点赞了一条关于“可持续农业”的帖子,系统不会直接分析A的偏好,而是将这条互动记录上链,由全网节点共同验证并更新A的“兴趣图谱”,这种模式下,推荐结果由社区共识决定,而非平台算法独裁。
更关键的是,用户首次拥有了数据主权,在DSocial中,A可以选择是否将自己的“兴趣图谱”授权给第三方应用——比如某农业科技创业公司想精准触达潜在用户,需向A支付微量的加密货币作为数据使用费,这种“数据即资产”的模式,彻底颠覆了Web2.0时代“用户免费贡献数据,平台独享商业价值”的旧秩序,2026年一季度,DSocial的用户数据授权收入已突破2亿美元,其中70%直接分配给用户,平台仅收取10%的管理费。
但去中心化推荐并非完美解药,某区块链分析机构2026年的报告显示,由于分布式节点计算能力有限,当前去中心化推荐系统的响应速度比中心化系统慢3-5倍;且智能合约的透明性可能导致用户隐私泄露——比如攻击者可通过分析链上互动记录,推断出用户的性取向、政治倾向等敏感信息,如何在“去中心化”与“效率”“隐私”之间找到平衡,仍是行业待解的难题。
联邦学习:当“数据不出域”成为推荐系统的新底线
本月绿色售后链与循环利用及新型电池热度持续攀升,相关应用不断深化 如果说去中心化推荐是Web3.0的“理想主义”,那么联邦学习则是Web2.5时代的“现实妥协”,2026年,这项由谷歌2017年提出的技术,已成为全球主流平台平衡“个性化推荐”与“数据隐私”的核心工具。
中医调理与绿色标识及工业互联网热度持续上升,相关领域迎来新发展 传统算法训练需要集中所有用户数据,而联邦学习的逻辑是“数据不出域,模型到本地”,以某头部电商平台“E购”为例:其拥有5亿用户,但用户数据分散在各个业务部门(如服饰、家电、生鲜)的独立数据库中,若用传统方式训练推荐模型,需将所有数据汇总到中央服务器,存在泄露风险,而E购采用的联邦学习方案是:在每个部门的服务器上部署本地模型,这些模型仅用本部门数据训练;训练完成后,模型参数(而非原始数据)被加密上传至中央服务器聚合;最终生成的全球模型再下发至各部门,指导个性化推荐。
2026年“618”期间,E购的联邦学习推荐系统首次大规模应用,数据显示,使用联邦学习后,用户点击率提升12%,但数据泄露投诉量下降87%,更关键的是,这项技术帮助E购突破了跨部门数据共享的壁垒——此前,服饰部门无法使用家电部门的用户购买记录推荐“智能家居套装”,而联邦学习让这种跨品类推荐成为可能。

联邦学习的应用场景远不止电商,2026年,某跨国医疗集团“HealthLink”将其用于疾病预测推荐系统,该系统整合了全球20个国家的医院数据,但受限于各国数据隐私法规(如欧盟GDPR、中国《个人信息保护法》),原始数据无法跨境流动,通过联邦学习,HealthLink在每个国家的服务器上训练本地模型,仅共享模型参数,最终构建出能预测罕见病发病风险的全球模型,据临床测试,该模型的准确率比传统集中式模型高9%,且完全符合各国数据合规要求。
但联邦学习并非没有漏洞,2026年3月,某安全团队发现,通过分析模型参数的更新频率和幅度,攻击者可以反向推断出原始数据的特征——若某本地模型频繁更新“孕妇装”类目的参数,可能暗示该部门拥有大量孕期用户数据,为此,E购等平台开始引入“差分隐私”技术,在模型参数中添加随机噪声,进一步模糊数据特征,这场“算法攻防战”,仍在持续升级。
推荐系统的“黑箱”与“白箱”:可解释性AI如何重建用户信任?
“为什么给我推荐这条内容?”——这是2026年用户对智能推荐系统最常见的质疑,当算法从“辅助工具”升级为“决策主体”,其“黑箱”特性正引发越来越多的信任危机。
2026年1月,某职场社交平台“LinkedIn+”因推荐系统争议登上热搜,用户B发现,自己频繁收到“35岁转行数据分析”的课程广告,而B实际是28岁的金融从业者,更讽刺的是,当B点击“不感兴趣”后,系统反而推送了更多同类内容,LinkedIn+的官方解释是“算法误判”,但用户并不买账——他们要求平台公开推荐逻辑,而非用“技术故障”搪塞。

这场风波背后,是推荐系统可解释性(Explainable AI, XAI)的缺失,传统深度学习模型(如神经网络)如同“黑箱”,输入数据后直接输出结果,中间的计算过程对用户甚至开发者都不可见,2026年,可解释性AI已成为行业刚需——欧盟《人工智能法案》要求所有高风险AI系统(包括推荐系统)必须提供“人类可理解的解释”;中国《互联网信息服务算法推荐管理规定》也明确规定,平台需向用户说明推荐逻辑。
某头部新闻客户端“NewsFlow”是首批应用可解释性AI的平台之一,其推荐系统采用“双模型架构”:主模型负责生成推荐结果,解释模型负责生成用户能理解的说明,当用户C收到一条关于“量子计算”的新闻推荐时,解释模型会显示:“根据您过去30天点击的12篇科技类文章,以及您关注的3位科技领域作者,系统判断您可能对前沿技术感兴趣;这条新闻的阅读量在同类话题中排名前5%,因此推荐给您。”这种“结果+依据”的展示方式,使NewsFlow的用户投诉率下降63%。
本月在线教育与体育赛事热度持续上升,相关产业迎来新发展 可解释性AI的应用场景远不止于此,2026年,某金融科技公司“FinTech Pro”将其用于信贷推荐系统,传统信贷模型仅给出“通过”或“拒绝”的结果,而FinTech Pro的解释模型会详细说明:“您的信用评分是720分(满分900),高于平均水平;但您最近3个月的信用卡使用率达到85%,高于系统设定的70%阈值,因此推荐额度为10万元而非15万元。”这种透明度不仅提升了用户信任,还帮助FinTech Pro将坏账率降低18%——用户更清楚自己的信用状况,主动优化行为以获得更高额度。
但可解释性AI仍面临挑战,某AI实验室2026年的研究显示,当前解释模型生成的说明多为“事后归因”,而非算法的真实计算逻辑——系统可能因“用户是男性”而推荐汽车广告,但解释模型会编造“您过去点击过3次汽车类内容”的虚假依据,如何让解释模型真正“诚实”,是下一阶段的技术攻坚方向。
当推荐系统开始“推荐自己”:算法与人类的权力博弈
2026年,智能推荐系统已不再满足于“服务用户”,而是开始主动“塑造用户”,这种转变在社交平台尤为明显——算法不仅推荐内容,还推荐“互动对象”“社交圈子”,甚至“价值观”。
某去中心化社交平台“DecentSocial”的案例极具代表性,其推荐系统采用“强化学习”技术,会根据用户的互动行为动态调整推荐策略,用户D最初关注了10个科技类账号,系统便持续推送同类内容