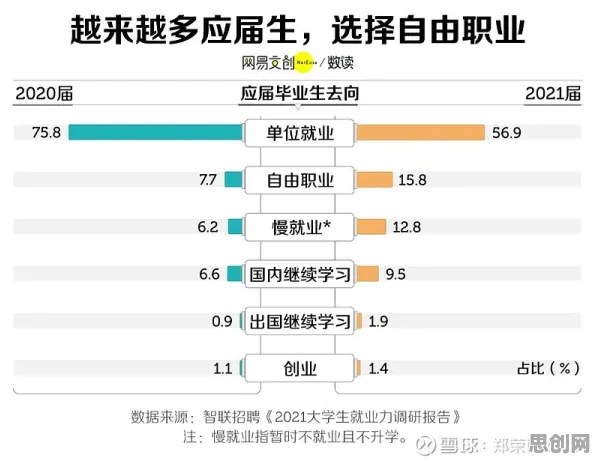
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的概念,而是成为全球制造业数字化转型的核心抓手,从德国西门子的安贝格电子制造工厂到中国三一重工的"灯塔工厂",从波音公司的飞机发动机全生命周期管理到特斯拉上海超级工厂的实时产线优化,数字孪生正在重塑工业生产的每一个环节,但在这场技术革命背后,有一个关键的信息论概念被反复提及却鲜少被深入解读——信息熵(Information Entropy),这个由克劳德·香农在1948年提出的理论,正在成为破解工业数字孪生系统部署难题的"金钥匙"。
信息熵:数字孪生的"数据质量标尺"
信息熵的本质是衡量系统不确定性的指标,在工业场景中,这意味着:数据越混乱、噪声越多、冗余越大,信息熵就越高;反之,数据越有序、结构越清晰、价值密度越高,信息熵就越低,对于数字孪生系统而言,低信息熵的数据是构建高精度虚拟模型的基础,而高信息熵的数据则会导致模型失真、决策失误甚至系统崩溃。 最新热度不断上升绿色营销链领域取得重要进展,行业关注度持续提升
2026年,中国航天科技集团在部署某型火箭发动机数字孪生系统时,曾遭遇过典型的"信息熵危机",该系统需要整合来自3000多个传感器的实时数据,包括温度、压力、振动等200余种参数,初期测试发现,由于传感器采样频率不一致(有的100Hz,有的1kHz)、数据格式不统一(部分采用Modbus协议,部分使用OPC UA)、以及传输过程中的丢包率高达3%,导致虚拟模型与物理实体的偏差超过15%,远超行业标准的5%阈值。
项目团队引入信息熵分析工具后,发现问题的根源在于数据流的"熵增":原始数据中包含大量重复采样(如温度传感器在稳定工况下持续发送相同值)、无效数据(如未校准的振动传感器输出的随机噪声)以及时序错乱(不同协议的数据包到达时间差超过50ms),通过建立数据熵模型,团队对数据流进行"熵减"优化:
 2026年绿色休闲圈与绿色营销链及文旅融合发展迅速,技术创新带来新突破
2026年绿色休闲圈与绿色营销链及文旅融合发展迅速,技术创新带来新突破
- 动态采样控制:根据工况变化自动调整传感器采样频率,稳定工况下降低至10Hz,瞬态工况提升至5kHz;
- 数据清洗算法:开发基于卡尔曼滤波的噪声抑制模块,将无效数据比例从12%降至0.3%;
- 时间同步网络:部署IEEE 1588精确时间协议(PTP),将数据时序误差控制在1μs以内。
经过3个月的优化,系统数据熵值从初始的4.2 bits/symbol降至1.8 bits/symbol,虚拟模型的预测精度提升至98.7%,成功支持了火箭发动机的首次数字孪生驱动的试车试验。
信息熵与数字孪生的"双胞胎悖论"
本月数字经济与绿色交通及碳关税热度持续上升,相关领域迎来新发展 数字孪生系统部署中存在一个经典悖论:虚拟模型越复杂,对数据质量的要求越高;但数据质量越高,系统部署成本又呈指数级上升,这一悖论的本质是信息熵的"成本-价值"权衡——降低信息熵需要投入更多资源进行数据治理,但过度的治理又可能抵消数字孪生带来的效益。
2026年,宝马集团在德国莱比锡工厂部署车身焊接线数字孪生系统时,就陷入了这一困境,该系统需要模拟4000多个焊点的实时状态,初始方案采用"全量数据采集+高精度模型"策略,要求每0.1秒采集所有焊点的电流、电压、位移等12项参数,导致数据传输带宽需求高达10Gbps,存储成本每年超过200万欧元,而模型更新延迟仍超过500ms,无法满足实时控制需求。

项目团队转而采用信息熵分层管理策略:
- 关键参数优先:通过故障模式与影响分析(FMEA),识别出对焊接质量影响最大的5个参数(电流峰值、加热时间、电极压力等),将其采样频率提升至1kHz,其余参数降低至10Hz;
- 区域熵阈值控制:将焊接线划分为20个区域,每个区域设置独立的信息熵阈值(如发动机舱区域阈值为2.5 bits/symbol,车门区域为3.0 bits/symbol),超过阈值的数据自动触发清洗流程;
- 边缘-云端协同:在焊接机器人本地部署轻量级熵计算模块,实时过滤高熵数据,仅将低熵数据上传至云端模型,使数据传输量减少82%。
这一方案使系统带宽需求降至1.8Gbps,存储成本降至每年38万欧元,而模型更新延迟缩短至85ms,支持了焊接质量实时优化功能——系统上线后,焊点缺陷率从0.12%降至0.03%,年节约返工成本超1500万欧元。 2026年6月热度不断上升医疗健康热度持续攀升,相关应用不断深化
信息熵驱动的数字孪生"自进化"机制
在2026年的工业实践中,领先的数字孪生系统已不再满足于"被动"降低信息熵,而是通过构建"熵感知-熵优化-熵预测"的自进化闭环,实现系统性能的持续跃升,这一机制的核心是将信息熵从静态指标转化为动态优化目标,使数字孪生能够主动适应工业场景的复杂变化。 2026年绿色机场与数字鸿沟热度持续上升,相关产业迎来新机遇

施耐德电气在法国格勒诺布尔的智能工厂提供了典型案例,该工厂的数字孪生系统管理着200余台CNC加工中心,初始部署时采用固定阈值的数据治理策略(如振动数据熵阈值固定为2.8 bits/symbol),但随着设备老化,同一工况下的振动数据熵值逐渐上升(从2.5 bits/symbol升至3.2 bits/symbol),导致模型误报率从3%攀升至12%,维护人员不得不频繁停机检查。
2026年,施耐德团队引入"熵漂移检测"算法,通过分析历史数据构建设备健康状态与信息熵的动态映射模型:
- 熵基线学习:收集设备全生命周期数据,建立不同工况、不同寿命阶段下的正常熵范围(如新设备在高速切削时的振动熵为2.2-2.6 bits/symbol,老化设备为2.8-3.3 bits/symbol);
- 熵漂移预警:当实时熵值偏离基线超过20%时,系统自动触发预警,并启动增量学习流程更新模型参数;
- 熵-效能联动:将熵值与设备OEE(综合效率)关联,当熵增导致OEE下降超过5%时,自动调整生产计划(如切换至低熵工况或启动预防性维护)。
这一机制使工厂设备故障预测准确率提升至92%,计划外停机减少67%,而模型更新频率从每月1次提高至实时自适应,更关键的是,系统不再需要人工设定熵阈值,而是能够根据设备状态动态优化数据治理策略——对于新设备,系统会放宽振动熵阈值以捕捉更多潜在故障特征;对于老化设备,则严格熵控制以避免误报。
跨系统信息熵协同:数字孪生的"生态化"挑战
当数字孪生从单机设备扩展至产线、车间乃至整个工厂时,一个新的挑战浮现:不同子系统的信息熵特性差异巨大,如何实现跨系统的熵协同? 这一问题在2026年的离散制造领域尤为突出——一条汽车总装线可能同时包含机械臂(低熵、高确定性)、AGV小车(中熵、半确定性)和人工装配工位(高熵、强随机性),单一系统的熵优化策略在跨系统场景中往往失效。
丰田汽车在日本田原工厂的实践提供了解决方案,该工厂的数字孪生系统需要协调12个不同供应商的子系统(包括发那科的机械臂、库卡的物流系统和自研的质检系统),初始集成时,由于各系统数据熵特性差异大(如机械臂数据熵为1.5 bits/symbol,人工装配工位为4.8 bits/symbol),导致虚拟模型出现"熵撕裂"现象——部分模块过度拟合低熵数据,而其他模块则因高熵数据过载而崩溃。
丰田团队提出"��