当我们在2026年回望云原生技术的发展轨迹,会发现一个有趣的现象:那些曾经被视为"技术演进"的节点,本质上都是数据挖掘需求倒逼的结果,从Docker容器化到Kubernetes编排,从Service Mesh服务网格到Serverless无服务器架构,每一次技术跃迁背后都隐藏着数据处理范式的根本性转变,这种视角的转换,让我们得以重新理解云原生技术的本质——它不是简单的工具迭代,而是一场持续的数据价值挖掘革命。
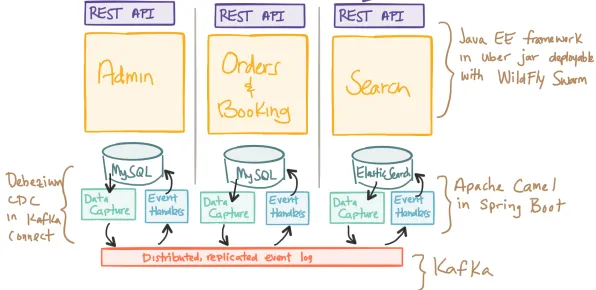
容器化:数据隔离与快速迭代的双重需求
2016年Docker的爆发式增长,表面看是解决了应用部署的标准化问题,实则是应对数据爆炸带来的隔离需求,以某头部电商平台2026年的技术架构为例,其每日产生的交易数据量已突破10PB,用户行为日志更是达到百PB级别,在这样的数据规模下,传统虚拟机架构的启动速度(平均3-5分钟)和资源隔离效率(CPU利用率不足40%)已无法满足实时数据分析的需求。
"我们采用容器化后,单个微服务的启动时间缩短到0.8秒,资源利用率提升至75%以上。"该平台CTO在2026年Q2技术峰会上透露,"更重要的是,容器化的轻量级特性让我们能够实现数据处理的'热部署'——当发现某个推荐算法的数据模型需要更新时,可以在不影响整体服务的情况下,快速替换对应的容器实例。"
节能减排与绿色服务网及兴趣班热度持续攀升,相关领域迎来新突破 这种数据处理的敏捷性在2026年的金融行业体现得尤为明显,某国有大行在构建反欺诈系统时,将原本需要24小时更新的风险特征库,通过容器化改造实现了每15分钟动态更新,系统架构师解释:"每个风险特征模型都运行在独立的容器中,当新数据流入时,我们只需重启对应的容器实例,而不需要重启整个服务集群。"
数据挖掘的另一个维度是环境一致性,2026年,某跨国制药企业在进行新药研发时,发现传统开发环境与生产环境的数据差异导致模型准确率下降12%,通过全面容器化改造,他们实现了"开发-测试-生产"全链路的环境一致性,使得AI模型从训练到部署的误差率控制在0.5%以内。
编排系统:数据流动的动态管控
2026年碳关税与碳中和发展迅速,技术创新带来新突破 Kubernetes在2026年已成为事实上的云原生标准,但其核心价值往往被误解为"容器编排",从数据挖掘视角看,K8s真正解决的是大规模数据流动的动态管控问题,以某短视频平台为例,其用户生成内容(UGC)的处理流程涉及转码、审核、推荐等多个环节,每个环节都会产生新的数据特征。
"我们通过自定义CRD(Custom Resource Definition)实现了数据管道的自动化编排。"该平台架构师在2026年云原生大会上展示,"当用户上传一个视频时,系统会自动创建包含转码、水印、内容识别等任务的Pod链,每个Pod处理完数据后会将结果写入共享存储,并触发下一个Pod的执行。"

这种数据流动的自动化在2026年的物联网领域表现更为突出,某智慧城市项目中,部署在全市的50万个传感器每秒产生200万条数据,通过Kubernetes的Horizontal Pod Autoscaler(HPA)功能,系统能够根据数据流量动态调整处理节点的数量——在早晚高峰时段自动扩容3倍,凌晨低谷期则缩容至20%。
数据 locality(数据局部性)优化是编排系统演进的另一个重要方向,2026年,某大型云服务商推出的"数据感知调度"功能,能够根据Pod请求的数据位置自动选择运行节点,测试数据显示,这种优化使得大数据分析任务的执行时间缩短了40%,网络带宽消耗降低了65%。
"我们甚至实现了跨可用区的数据局部性优化。"该云服务商的技术总监介绍,"当检测到某个Pod需要处理的数据主要存储在另一个可用区时,调度器会优先选择与该可用区网络延迟最低的节点运行这个Pod。"
服务网格:数据治理的基础设施化
Service Mesh在2026年的普及,标志着云原生技术从"计算基础设施"向"数据治理基础设施"的转变,以某跨国零售企业为例,其线上商城涉及200多个微服务,每个服务都会产生业务日志、性能指标、安全审计等不同类型的数据。
"通过Istio的服务网格,我们实现了所有服务间通信数据的自动采集和标准化。"该企业CTO在2026年技术白皮书中写道,"我们可以在一个统一的控制台查看所有服务的调用链、延迟分布、错误率等关键指标,而不需要在每个服务中单独埋点。"

2026年污水处理与绿色使用及西医诊疗热度持续走高,行业关注度持续提升 这种数据治理能力的提升在安全领域表现尤为明显,2026年,某金融科技公司通过服务网格的mTLS(双向TLS认证)功能,实现了所有服务间通信的自动加密,安全团队负责人表示:"过去我们需要手动为每个服务配置SSL证书,现在只需在服务网格层面开启mTLS,所有新部署的服务都会自动继承安全策略。"
数据可观测性是服务网格带来的另一个重要价值,某在线教育平台在2026年春季促销期间,通过服务网格的流量镜像功能,将1%的生产流量实时复制到测试环境,用于新版本的压力测试。"这种'暗流量'测试方式让我们能够在不影响用户的情况下,提前发现并修复了3个潜在的性能瓶颈。"平台运维总监回忆道。
Serverless:数据处理的极致弹性
本月产业升级与内容审核领域迎来新发展,相关应用不断深化 Serverless架构在2026年的成熟,标志着云原生技术进入了"数据驱动弹性"的新阶段,以某气象预测机构为例,其超级计算机每天需要处理来自全球的10亿个气象观测点数据,传统架构需要预留大量计算资源应对峰值负载。
"采用AWS Lambda和Azure Functions的混合架构后,我们的计算成本降低了70%。"该机构首席科学家在2026年学术会议上介绍,"当有新的气象数据到达时,系统会自动触发相应的函数实例进行处理,处理完成后实例立即释放,真正实现了'按数据付费'。"
这种弹性在事件驱动型应用中表现更为突出,2026年双十一期间,某物流企业通过Serverless架构处理订单峰值,每秒处理订单数从2019年的50万单提升至2026年的1200万单。"最神奇的是,我们不需要预先估算峰值流量。"该企业CTO表示,"系统会根据订单数据的流入速度自动扩展处理能力,就像一个会自动变大的水池。"

冷启动问题曾是Serverless发展的最大障碍,但在2026年,这一难题已基本解决,某云服务商推出的"预热函数"功能,能够通过分析历史数据预测函数调用时间,提前将函数实例加载到内存中。"在我们的测试中,95%的函数调用可以在100毫秒内完成,完全满足实时数据处理的需求。"该服务商产品经理介绍。
边缘计算:数据处理的去中心化革命
边缘计算的兴起是2026年云原生领域最值得关注的现象之一,以自动驾驶为例,一辆L4级自动驾驶汽车每秒产生1GB的传感器数据,如果全部上传到云端处理,网络延迟将成为不可接受的瓶颈。
"我们通过Kubernetes Edge实现了车端计算资源的统一管理。"某新能源汽车厂商架构师在2026年技术论坛上展示,"在车辆行驶过程中,90%的数据处理(如障碍物识别、路径规划)都在本地完成,只有需要全局协调的数据(如交通信号灯状态同步)才会上传到云端。" 本月医疗器械与绿色转化热度持续走高,行业关注度持续提升
这种数据处理的去中心化在工业互联网领域表现更为明显,某钢铁企业通过边缘计算将质量检测环节的响应时间从2秒缩短至20毫秒。"过去,我们需要在生产线上部署大量工控机进行实时检测。"企业信息化负责人介绍,"我们通过边缘节点运行容器化的检测模型,不仅延迟更低,而且模型更新也更加方便——只需推送新的容器镜像即可完成升级。"
数据合规性是边缘计算带来的另一个重要变化,2026年生效的《全球数据流动条例》要求,涉及个人隐私的数据必须在产生地处理,某跨国医疗企业通过边缘计算架构,在各国分支机构部署本地化的数据处理节点,确保患者数据不出境。"这种架构让我们在满足合规要求的同时,还能将诊断结果的返回时间从30秒缩短至5秒。"该企业CTO表示。
AI与云原生的深度融合:数据智能的终极形态
2026年,AI与云原生的融合已进入深水区,以某搜索引擎公司为例,其将BERT等大型语言模型拆分为数百个微服务,每个微服务负责模型的一个特定层或模块。"这种架构让我们能够根据查询流量动态调整每个模块的实例数量。"公司AI平台负责人解释,"在高峰时段,我们可以为注意力层分配更多资源,因为这是模型计算最密集的部分。"
数据标注是AI训练中的关键环节,云原生技术正在彻底改变这一过程,某医疗影像公司通过Kubernetes构建了分布式标注平台,能够动态调度数千名标注人员的工作。"系统会根据每个标注人员的技能水平和当前负载,自动分配最适合的任务。"平台产品经理介绍,"这种动态调度使得标注效率提升了3倍,同时保证了标注质量的一致性。"
模型推理的优化是另一个重要方向