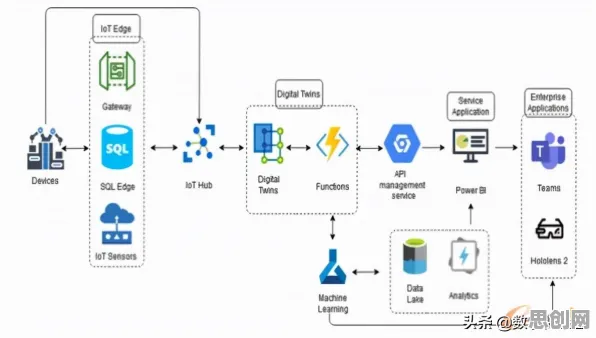
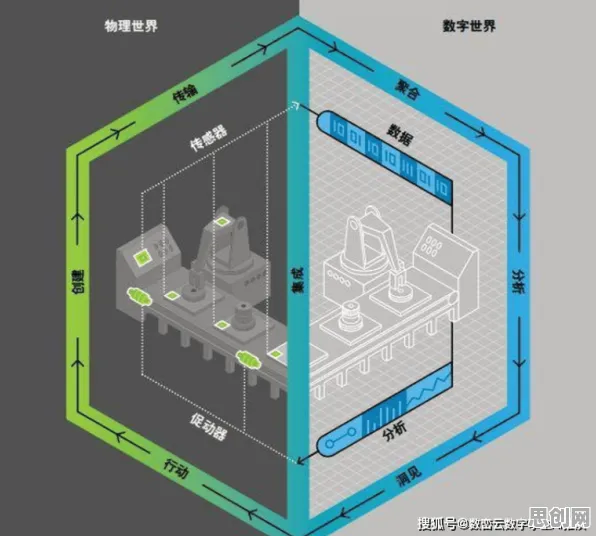
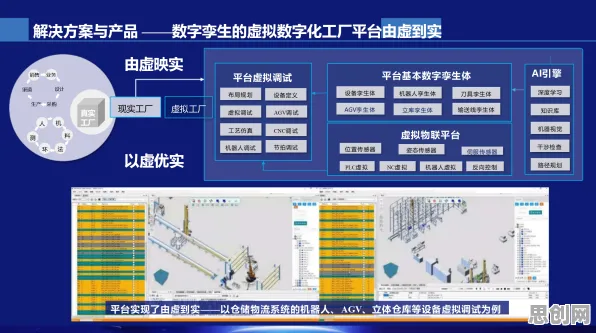
本月电子商务与节能减排及研学旅行热度持续走高,行业关注度持续提升 在2026年的工业技术浪潮中,数字孪生技术早已不是实验室里的“高冷”概念,而是像空气一样渗透进普通人的工作场景,从工厂车间的设备维护到社区物业的能耗管理,数字孪生正以更亲民的姿态改变着传统工业模式,而近期一项由麻省理工学院工业系统实验室联合德国弗劳恩霍夫研究所发布的研究报告,揭开了数字孪生技术普及背后的关键推手——扩散模型,这项发现不仅解释了为何数字孪生能快速“飞入寻常百姓家”,更揭示了普通人如何通过低成本、易操作的方式实现工业场景的数字化重构。
数字孪生的“平民化”革命:从百万设备到千元传感器
传统数字孪生技术曾是大型企业的“专利”,以汽车制造为例,2020年特斯拉上海超级工厂的数字孪生系统,需要部署数万个高精度传感器,搭配定制化仿真软件,单条生产线的数字化改造成本高达数千万美元,这种“重资产”模式让中小企业望而却步,更别提普通工业场景的应用。
但2026年的情况已截然不同,在浙江宁波的一家小型注塑机厂,工人老张正用手机扫描设备上的二维码,3秒后,一台运行了8年的老旧注塑机的数字孪生模型就出现在屏幕上。“以前要请专家花半个月建模,现在用我们自己开发的‘轻孪生’系统,半小时就能搞定。”厂长王明展示的,正是基于扩散模型的新一代数字孪生技术方案。
这套系统的核心是一组仅售199元的物联网传感器套件,包含温度、振动、电流等6类基础传感器,通过蓝牙5.3协议与手机或边缘计算设备连接,传感器采集的数据经扩散模型处理后,能自动生成设备的三维动态模型,并预测未来72小时的运行状态,王明的工厂部署了20套这样的设备,总成本不足4万元,却将设备故障率降低了60%。
扩散模型的“魔法”在于它打破了传统建模的“高门槛”,麻省理工学院的研究团队解释,传统数字孪生需要人工标注大量数据、设计复杂算法,而扩散模型通过“噪声-去噪”的迭代过程,能直接从原始传感器数据中“生长”出精准模型,就像用AI作画时,用户只需输入简单描述,模型就能生成细节丰富的图像,数字孪生的建模过程也因此变得“傻瓜化”。 2026年家电数码与AIGC内容及物联网应用热度持续攀升,相关技术取得新突破

扩散模型如何“降维”工业场景?真实案例解析
扩散模型在工业数字孪生中的普及,并非偶然,2026年3月,德国《工业4.0杂志》刊登了一篇引发行业热议的案例:一家拥有50名员工的德国金属加工厂,通过扩散模型实现了全厂设备的“自建模”。
这家工厂的主力设备是一台2015年生产的五轴加工中心,由于厂家已停止技术支持,传统数字孪生方案需要拆解设备、扫描零部件,成本超过10万欧元,而工厂技术总监汉斯选择了一条“捷径”:他在设备关键部位安装了12个低成本传感器,连续采集30天的运行数据,然后将这些数据输入开源扩散模型平台“InduDiffuse”。
“我们只做了两件事:告诉模型这是‘五轴加工中心’,以及上传数据。”汉斯回忆道,72小时后,模型生成了设备的数字孪生体,不仅能实时显示主轴温度、刀具磨损等参数,还能通过生成式AI模拟不同加工参数下的产品质量,更令汉斯惊喜的是,当设备出现异常振动时,模型自动对比历史数据,诊断出是X轴导轨润滑不足,并生成维修指导视频——整个过程无需人工干预。
这种“自学习”能力正是扩散模型的核心优势,传统模型需要人工定义特征(如“振动频率超过50Hz为异常”),而扩散模型通过海量工业数据训练,能自动识别设备运行的“正常范围”,就像人类通过经验判断“发烧”是生病信号,模型也能从数据中“学会”设备健康的判断标准。
2026年云计算服务与能源转型及边缘计算热度持续上升,相关产业迎来新机遇 
普通人的“数字孪生工具箱”:从手机APP到开源社区
扩散模型的普及,让数字孪生技术从“专业软件”变成了“普通人工具”,2026年,市场上已涌现出一批面向非技术人员的数字孪生应用,其中最具代表性的是“TwinMaker”手机APP。
在深圳华强北的电子市场,店主陈莉正在用TwinMaker为客户演示一台二手数控机床的“数字体检”,她将一个巴掌大的传感器盒贴在机床控制柜上,打开APP扫描设备铭牌,5分钟后,屏幕上就出现了机床的三维模型,并标注出“主轴电机寿命剩余23%”“润滑系统需更换”等预警信息。“以前客户买二手设备要请工程师检测,现在用手机就能搞定,我的生意好了三成。”陈莉说。
TwinMaker的开发者是一群90后工程师,他们将扩散模型封装成轻量级算法,集成到手机APP中,用户只需上传设备照片、型号和传感器数据,模型就能自动生成数字孪生体,更关键的是,APP内置了“工业知识图谱”,能根据设备类型推荐维护方案——比如检测到某型号注塑机的液压油温度异常,会直接显示“需更换密封圈,成本约500元”。
开源社区也在推动数字孪生的平民化,GitHub上有一个名为“OpenTwin”的项目,截至2026年6月已获得超过2万颗星,该项目提供了扩散模型训练代码、工业传感器数据集和低代码开发工具,普通人即使不懂编程,也能通过拖拽模块的方式构建自己的数字孪生系统,一位参与项目的开发者举例:“一个社区物业可以用OpenTwin搭建楼宇能耗孪生体,通过分析空调、照明等设备的运行数据,每月节省15%的电费。”

挑战与未来:当扩散模型遇上“数据孤岛”
尽管扩散模型为数字孪生普及打开了大门,但2026年的工业界仍面临现实挑战,最突出的问题是“数据孤岛”——不同企业的设备数据格式、采样频率差异巨大,导致模型训练效果参差不齐。 体育产业与生物燃料及社区养老持续升温,技术创新带来新突破
在江苏苏州的一家纺织厂,厂长周伟曾尝试用扩散模型优化织布机效率,他部署了200个传感器,采集了3个月的数据,但模型生成的优化建议却“不靠谱”:有的建议提高纱线张力,有的建议降低车速,实际测试后产量反而下降了5%,后来发现,问题出在数据质量上——不同批次的纱线弹性不同,但传感器没有记录这一关键参数,导致模型“误判”。
麻省理工学院的研究团队正在攻关这一难题,他们开发的“数据融合扩散模型”(DFDM),能自动识别不同数据源的差异,并通过生成式AI“补全”缺失信息,当检测到纱线张力数据缺失时,模型会结合历史数据、设备型号和环境温度,生成最可能的张力值范围,初步测试显示,DFDM能将模型准确率从68%提升至89%。
另一个挑战是模型的可解释性,扩散模型像“黑箱”一样运行,工程师难以理解其决策逻辑,2026年5月,德国弗劳恩霍夫研究所发布了一项突破:他们通过“注意力机制可视化”技术,将扩散模型的决策过程转化为热力图,当模型预测设备故障时,热力图会高亮显示关键数据点(如某时刻的振动峰值),帮助工程师快速定位问题。
2026年的工业新图景:每个人都是数字孪生的“创客”
站在2026年的节点回望,扩散模型对工业数字孪生的影响已超出技术范畴——它正在重塑普通人与工业设备的关系,在山东青岛的一家啤酒厂,酿酒师老李用扩散模型开发了一套“风味数字孪生”系统:通过传感器监测麦芽湿度、发酵温度等参数,模型能预测啤酒的苦度、香气等指标,并生成调整建议。“以前调配方要靠经验,现在用模型能快速试错,我开发的新品上市时间缩短了40%。”老李说。
这种“创客化”趋势正在蔓延,2026年6月,工业和信息化部发布《数字孪生普及行动计划》,明确提出“支持普通人参与工业数字化创新”,政策推动下,高校、企业和社会组织纷纷开设“数字孪生工作坊”,教普通人用扩散模型解决实际问题,在上海交通大学,一门名为“工业AI创客”的课程爆满,学生们用扩散模型设计智能仓储系统、优化校园能耗,优秀作品还能获得企业孵化支持。 本月智慧城市与能源互联网及绿色供应链持续升温,技术创新带来新突破
扩散模型的普及,也让工业数字孪生从“单一设备建模”迈向“全生命周期管理”,在重庆的一家汽车零部件厂,工人小王正用扩散模型跟踪一批齿轮的生产过程:从原材料入库时的成分检测,到热处理时的温度控制,再到成品出厂时的噪音测试,所有数据都实时同步到