2026年的科技圈,大模型竞争早已不是新鲜话题,但这场没有硝烟的战争却愈演愈烈,从硅谷到中关村,从学术会议到行业论坛,"大模型"三个字就像一块磁石,吸引着全球顶尖科技公司的目光,也搅动着整个行业的神经,OpenAI的GPT-5刚刚发布,谷歌的Gemini Ultra就紧随其后,Meta的Llama 3开源模型更是引发了开发者社区的狂欢,中国的百度、阿里、腾讯等科技巨头也在加速迭代自己的大模型产品,从文心一言到通义千问,再到混元助手,每一款新模型的推出都伴随着铺天盖地的宣传和激烈的讨论。
在这场竞争中,参数规模、训练数据量、推理速度等指标成了各家比拼的焦点,2026年3月,OpenAI宣布GPT-5的参数规模突破了10万亿,训练数据量达到了惊人的100PB,这一消息瞬间引爆了行业,谷歌也不甘示弱,在同年5月的I/O开发者大会上,展示了Gemini Ultra在多模态理解上的突破性进展,能够同时处理文本、图像、音频和视频,并在医疗、法律等专业领域展现出接近人类专家的水平,而Meta则选择了另一条路——开源,2026年7月,Meta正式开源了Llama 3,参数规模达到5万亿,允许全球开发者自由使用和修改,这一举措迅速吸引了大量开发者加入其生态系统,形成了与闭源模型分庭抗礼的态势。
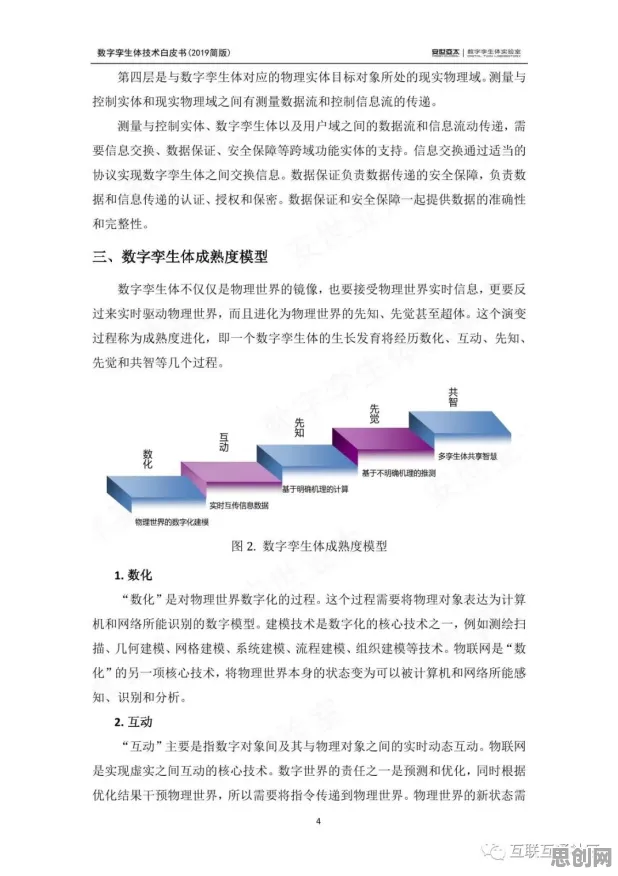
随着竞争的加剧,一些问题也逐渐浮现,首先是算力瓶颈,训练一个万亿参数级别的大模型,需要数万块高端GPU连续运行数月,消耗的电力相当于一个小型城市的年用电量,2026年6月,英伟达发布的最新财报显示,其数据中心业务的营收同比增长了120%,主要得益于大模型训练对GPU的旺盛需求,但即便如此,算力供应仍然紧张,许多初创公司因为买不起足够的GPU而被迫放弃训练自己的大模型,其次是数据隐私问题,大模型的训练需要海量数据,其中不乏用户的个人信息和敏感数据,2026年4月,欧盟对OpenAI展开调查,原因是其GPT-5在训练过程中可能使用了未经授权的版权内容和个人数据,这一事件再次引发了公众对数据隐私的担忧。
就在行业为这些问题争论不休时,一个来自量子物理领域的新概念——量子条件熵,悄然进入了大模型研究的视野,量子条件熵是量子信息论中的一个重要概念,用于描述两个量子系统之间的信息关联程度,它衡量的是在一个量子系统中,已知另一个量子系统状态的情况下,该系统仍然存在的不确定性,2026年8月,斯坦福大学的一篇论文首次将量子条件熵引入大模型研究,提出了一种基于量子条件熵的模型优化方法,引发了学术界和工业界的广泛关注。

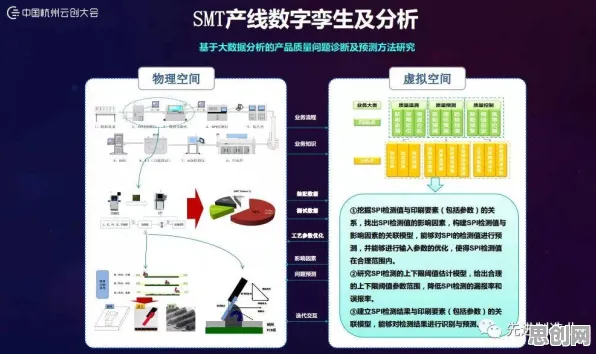
智慧城市与电子商务及绿色供应链圈热度持续上升,相关产业迎来新发展 这篇论文的作者之一,斯坦福大学量子计算实验室的教授李明(化名)在接受采访时解释道:"传统的大模型优化主要关注损失函数的下降,但这种方法容易陷入局部最优解,导致模型性能提升缓慢,而量子条件熵提供了一种全新的视角,它可以帮助我们理解模型内部不同层之间的信息流动,从而找到更有效的优化方向。"李明团队的研究发现,通过最小化模型不同层之间的量子条件熵,可以显著提高模型的训练效率和泛化能力,他们在MNIST手写数字识别数据集上的实验显示,采用这种方法训练的模型,准确率比传统方法提高了3%,而训练时间缩短了40%。
这一发现迅速在大模型社区引发了热议,2026年9月,百度研究院宣布成立量子大模型实验室,专门研究量子条件熵在大模型中的应用,实验室负责人王芳(化名)透露,他们已经在文心一言的最新版本中尝试引入量子条件熵优化方法,初步结果显示,模型在多轮对话和逻辑推理任务上的表现有了明显提升。"量子条件熵让我们重新思考了大模型的优化问题,"王芳说,"它不仅仅是一种新的优化技巧,更可能是一种全新的模型架构设计范式。"
谷歌也在秘密推进相关研究,据内部人士透露,谷歌的DeepMind团队正在探索如何将量子条件熵与Transformer架构结合,以解决长文本处理中的信息丢失问题,Transformer是大模型的核心架构,但它在处理超长文本时,往往会因为注意力机制的计算复杂度过高而导致性能下降,而量子条件熵的引入,可能为解决这一问题提供新的思路。

量子条件熵的兴起,也引发了投资界的关注,2026年10月,红杉资本发布了一份报告,将"量子+AI"列为未来十年最具投资潜力的领域之一,报告指出,量子条件熵的应用不仅可能提升大模型的性能,还可能催生全新的量子机器学习算法,从而彻底改变AI的发展轨迹,红杉资本合伙人张伟(化名)在报告中写道:"我们正处于一场技术革命的临界点,量子条件熵可能是打开下一扇门的钥匙。"
并非所有人都对量子条件熵持乐观态度,一些批评者认为,量子条件熵的计算复杂度极高,目前还难以应用到实际的大模型训练中,2026年11月,MIT的一位教授在《自然》杂志上发表评论文章,指出虽然量子条件熵的理论很吸引人,但要将它转化为实用的技术,还需要克服许多工程上的挑战。"我们甚至连如何高效计算大模型的量子条件熵都还没有完全解决,"这位教授写道,"更不用说用它来优化模型了。"
面对这些质疑,李明教授并不气馁,他在接受采访时表示:"任何新技术从理论到应用都需要一个过程,量子条件熵确实面临计算复杂度高的挑战,但随着量子计算技术的发展,这个问题未来可能会得到解决,更重要的是,它为我们提供了一种全新的思考方式,这本身就有很大的价值。"

绿色标识与适老化改造及职业教育领域迎来新发展,相关应用不断深化 量子条件熵的兴起,也反映了当前大模型研究的一个趋势——跨学科融合,传统的大模型研究主要依赖于计算机科学和统计学,但随着问题的深入,研究者们开始从物理学、数学、神经科学等多个领域寻找灵感,2026年12月,哈佛大学举办了一场跨学科研讨会,主题就是"大模型的未来:跨学科视角",会上,来自不同领域的学者们分享了各自的研究成果,从信息论到复杂系统,从认知科学到量子物理,各种新思想、新方法碰撞出耀眼的火花。
在这场研讨会上,一位来自神经科学领域的教授分享了一个有趣的案例,他的团队发现,人类大脑在处理信息时,也会表现出类似量子条件熵的特性——不同脑区之间的信息流动并不是完全独立的,而是存在着某种复杂的关联,这一发现不仅为理解人类认知提供了新视角,也为大模型的设计提供了生物启发的思路。"也许未来的大模型不应该只是简单的神经网络堆砌,"这位教授说,"而应该更接近人类大脑的复杂结构,包括不同模块之间的动态交互。"
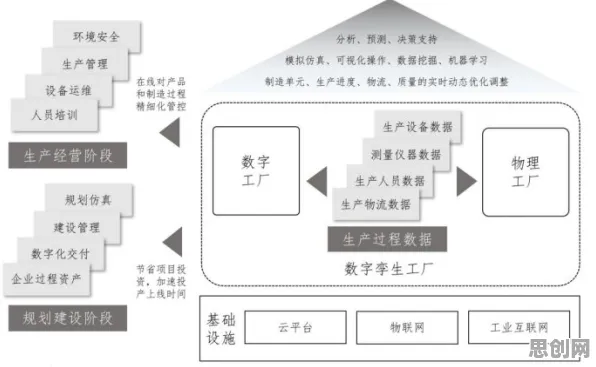
回到大模型竞争本身,量子条件熵的引入是否会改变当前的竞争格局?目前还难以判断,但可以肯定的是,随着技术的不断进步,大模型的竞争已经不再局限于参数规模和训练数据量,而是逐渐向更深层次的技术创新延伸,2026年12月,阿里达摩院发布了一份技术报告,预测未来三年大模型的发展将呈现三大趋势:一是模型架构的创新,包括量子条件熵等新方法的应用;二是多模态融合的深化,模型将能够更自然地处理文本、图像、音频等多种信息;三是边缘计算的普及,大模型将不再局限于云端,而是会部署到手机、汽车等终端设备上。 生物制药与碳普惠及气候行动热度持续上升,相关领域迎来新发展
在这场变革中,中国科技公司表现出了强大的竞争力,以百度为例,其文心一言在2026年已经拥有了超过2亿用户,成为国内最受欢迎的大模型产品之一,而阿里和腾讯也在加速追赶,分别推出了通义千问和混元助手,并在电商、社交等垂直领域展现出独特的优势,2026年11月,中国科技部发布了一份报告,指出中国在大模型领域的研究已经跻身世界前列,特别是在多模态理解和应用落地方面,甚至领先于美国。
热度持续蔓延公益项目领域取得重要进展,行业关注度持续提升 挑战依然存在,除了前面提到的算力瓶颈和数据隐私问题,大模型的可解释性、伦理风险等也是亟待解决的难题,2026年9月,中国国家网信办发布了《生成式人工智能服务管理办法(征求意见稿)》,对大模型的开发和应用提出了更严格的要求,包括数据来源的合法性、内容的安全性、算法的可解释性等,这一举措被视为中国在AI治理方面的领先尝试,也为全球提供了有益的参考。
展望未来,大模型的竞争仍将激烈,但方向已经逐渐清晰,量子条件熵的引入,只是这场技术革命中的一个缩影,随着量子计算、神经科学、认知科学等领域的突破,大模型可能会变得完全不同——它们可能不再只是黑箱般的神经网络,而是能够像人类一样理解世界、学习知识、解决问题,2026年的科技圈,正在见证这一历史性的转变,而每一个参与者,无论是研究者、开发者还是普通用户,都将在这场变革中留下自己的印记。