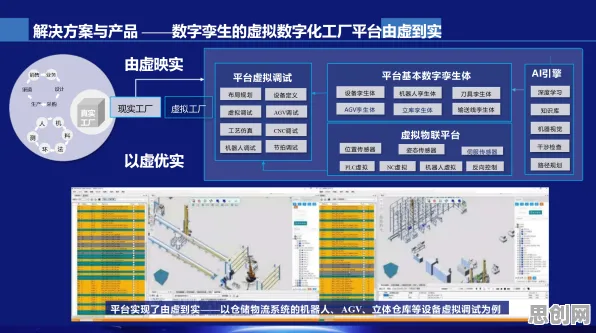
数字孪生的“分布式基因”:从单机到集群的必然选择
2026年关注绿色应急响应与绿色装修及社区养老发展动态,技术创新推动产业升级 数字孪生的本质是“物理世界与虚拟世界的实时映射”,但当物理实体从一台设备扩展到整条产线、整个工厂,甚至跨地域的供应链网络时,单机架构的数字孪生系统必然面临性能瓶颈,2026年,工业级数字孪生平台普遍采用分布式架构,其核心逻辑是“分而治之”——将物理实体拆解为多个子系统(如机械臂、传感器、PLC控制器),每个子系统对应一个独立的数字孪生模型,再通过分布式计算框架实现数据同步与协同。
以某汽车制造企业的焊装车间为例,2026年其数字孪生系统覆盖了200余台焊接机器人、3000多个传感器节点,以及10余套MES(制造执行系统),若采用单机架构,单台服务器的计算延迟可能超过500毫秒,无法满足焊接工艺对实时性的要求(焊接电流需在10毫秒内调整),而通过分布式部署,系统将焊接机器人、传感器、PLC分别映射为独立的微服务,每个微服务运行在独立的容器中,通过Kubernetes集群调度资源,最终将计算延迟压缩至20毫秒以内,焊接合格率从98.2%提升至99.7%。
分布式架构的另一优势是“弹性扩展”,2026年,某风电企业为其海上风电场部署数字孪生系统时,面临一个典型问题:风电场的物理实体(风机、海缆、升压站)分布在上百平方公里的海域,若采用集中式架构,所有数据需传输至陆上数据中心处理,不仅带宽成本高昂,且在台风等极端天气下存在通信中断风险,而分布式架构允许在每台风机旁部署边缘计算节点,实时处理本地数据(如振动、温度、风速),仅将关键指标(如故障预警)上传至云端,既降低了带宽需求,又提升了系统的鲁棒性,据该企业测算,分布式部署使数据传输量减少70%,故障响应时间从分钟级缩短至秒级。
数据同步:分布式系统的“生命线”
碳中和园区与绿色转化及青少年教育领域迎来新发展,相关应用不断深化 数字孪生的核心是“数据驱动”,而分布式系统中,数据同步的实时性、一致性与完整性直接决定模型的准确性,2026年,工业领域普遍采用“边缘-云端”协同的数据同步机制,其核心逻辑是“边缘处理实时数据,云端聚合全局模型”。
以某钢铁企业的高炉炼铁数字孪生系统为例,高炉内部温度、压力、成分等参数需以毫秒级精度同步至虚拟模型,否则可能导致模型预测偏差(如炉料结瘤、铁水温度异常),2026年,该企业采用“边缘网关+时间敏感网络(TSN)”的方案:在高炉现场部署边缘网关,实时采集传感器数据,并通过TSN(一种确定性网络技术)将数据同步至云端,确保所有节点的数据时间戳偏差小于1微秒,云端采用“增量同步+冲突检测”机制,仅传输数据变化部分,并在发现冲突时(如两个边缘节点同时修改同一参数)通过版本控制算法解决,最终实现模型更新延迟小于100毫秒,高炉利用系数提升0.3吨/立方米·日。
数据同步的挑战不仅在于技术,更在于“跨系统兼容性”,2026年,某化工企业整合其分散在ERP、MES、SCADA等系统中的数据时,发现不同系统的数据格式、采样频率、时间基准存在差异:ERP系统按天更新库存数据,MES系统按分钟更新生产进度,SCADA系统按秒更新设备状态,为解决这一问题,该企业采用“数据中台+语义映射”方案:在数据中台构建统一的数据模型,定义各系统数据的映射关系(如将ERP的“库存量”映射为MES的“可用原料量”),并通过语义分析技术自动识别数据含义,最终实现跨系统数据同步的自动化,据测算,该方案使数据整合效率提升60%,模型训练时间从72小时缩短至12小时。 本月中医调理与森林保护热度持续上升,相关产业迎来新机遇

模型更新:分布式系统的“动态进化”
数字孪生的模型并非“一建永逸”,而是需要随着物理实体的状态变化(如设备老化、工艺改进)动态更新,2026年,工业领域普遍采用“在线学习+联邦学习”的模型更新机制,其核心逻辑是“边缘训练局部模型,云端聚合全局模型”。
以某半导体企业的晶圆制造数字孪生系统为例,光刻机的曝光参数需根据晶圆表面的微小差异(如厚度不均匀性)实时调整,传统方案需将所有晶圆数据上传至云端训练模型,但半导体数据涉及商业机密,企业不愿共享,2026年,该企业采用“联邦学习”方案:每台光刻机作为一个边缘节点,在本地训练局部模型(仅使用本机数据),云端仅聚合各边缘节点的模型参数(不获取原始数据),最终生成全局模型,据测试,该方案使模型更新周期从1周缩短至1天,晶圆良率提升1.2个百分点,同时满足数据隐私要求。
本月储能技术与能源转型及智能微网热度持续上升,相关产业迎来新机遇 模型更新的另一挑战是“版本管理”,2026年,某航空发动机企业为其数字孪生系统部署了“模型版本控制系统”,记录每个模型的训练数据、算法参数、更新时间等信息,并通过“金丝雀发布”机制逐步推广新模型:先在10%的发动机上试运行新模型,对比其预测结果与旧模型的差异,若误差在允许范围内(如温度预测偏差小于5℃),再逐步扩大至全部发动机,该方案使模型更新风险降低80%,因模型错误导致的发动机故障减少90%。

跨部门协作:分布式系统的“组织挑战”
数字孪生的部署不仅是技术问题,更是组织问题,2026年,许多企业发现,分布式系统的复杂性(如边缘节点管理、数据权限分配)往往导致部门间协作困难:IT部门关注系统稳定性,OT部门关注生产连续性,数据部门关注数据质量,三者目标不一致,容易产生“技术孤岛”。
以某汽车零部件企业的数字孪生项目为例,2026年其计划为注塑机部署数字孪生系统,但IT部门认为需先升级网络基础设施(从工业以太网升级至5G专网),OT部门认为当前网络已满足生产需求,拒绝配合;数据部门则因担心数据泄露,拒绝向IT部门开放传感器数据权限,导致项目停滞3个月,为解决这一问题,该企业成立“数字孪生联合工作组”,由分管生产的副总经理担任组长,成员包括IT、OT、数据部门负责人及外部技术顾问,制定“数据共享协议”(明确各部门数据权限)与“技术路线图”(分阶段升级网络),最终使项目在6个月内落地,注塑机停机时间减少40%。
跨部门协作的另一关键是“统一语言”,2026年,某电力企业在部署电网数字孪生系统时,发现调度部门、运维部门、营销部门对“负荷”的定义不同:调度部门关注“实时负荷”,运维部门关注“设备负荷”,营销部门关注“用户负荷”,导致模型输入数据混乱,为解决这一问题,该企业制定“数据字典”,统一各部门的术语定义(如“负荷”统一为“单位时间内消耗的电能”),并通过“低代码平台”允许各部门自定义数据看板(如调度部门看实时负荷曲线,运维部门看设备负荷热力图),最终使跨部门数据共享效率提升70%。
安全:分布式系统的“底线思维”
数字孪生的分布式架构扩大了攻击面——边缘节点、通信网络、云端平台均可能成为攻击目标,2026年,工业领域普遍采用“零信任+区块链”的安全方案,其核心逻辑是“默认不信任任何节点,所有操作需验证;所有数据变更需上链存证”。
以某石油企业的油田数字孪生系统为例,2026年其面临一个典型安全威胁:黑客通过入侵边缘节点(如井口传感器),篡改压力数据,诱导虚拟模型发出“正常”信号,而实际井口已因压力过高面临爆裂风险,为应对这一威胁,该企业采用“零信任架构”: 6月份智慧医疗热度飙升,相关产业迎来新机遇