在2026年的工业领域,智能语音系统早已不是实验室里的“黑科技”,而是像螺丝刀一样常见的生产工具,从汽车工厂的质检流水线到化工园区的安全监控室,从电力巡检的无人机到港口码头的集装箱调度,语音指令正以每秒数万次的速度与工业大数据交互,但很多人不知道的是,这些看似简单的“说话办事”背后,藏着三种截然不同的技术路径——它们决定了系统能否在零下30度的极寒车间准确识别指令,能否在120分贝的噪音环境中区分设备异响,甚至能否预测一台机床三个月后的故障概率。
基于规则匹配的语音系统:工业场景的“老黄牛”
在青岛某重型机械厂的装配车间里,老师傅老张正对着头顶的麦克风喊:“小智,调取3号龙门吊的维修记录。”两秒后,他面前的AR眼镜上弹出详细的数据表格——这是该厂2024年上线的“规则语音系统”在工作,这套系统的核心逻辑简单粗暴:把所有可能的指令提前录入数据库,当用户说话时,系统通过声纹识别确认身份,再通过关键词匹配找到对应操作。 2026年环保公益与噪音治理及绿色设计热度持续走高,行业关注度持续提升
循环经济与居家养老及基因检测热度持续上升,相关产业迎来新发展 “它就像个超级字典,”系统开发方中科声学的工程师李明解释,“我们花了三个月时间,把工厂里2000多条操作指令、设备参数、安全规范转化成语音模板,连‘把扳手递给我’这种口语化表达都做了同义词扩展。”这种“笨办法”在标准化程度高的工业场景里却异常好用——在某汽车零部件厂的测试中,系统对固定指令的识别准确率达到99.2%,响应时间控制在0.8秒以内。
但规则系统的短板同样明显,2026年3月,济南某钢铁厂的高炉监控系统就栽了跟头,当天夜班工人发现炉温异常,情急之下喊出:“快查二号炉的冷却水流量!”系统却因为“冷却水”这个关键词未被提前录入而死机,导致抢修延迟了17分钟,事后复盘发现,该厂原有规则库只包含“循环水”“冷却系统”等术语,却漏掉了工人日常使用的口语化表达。
“现在我们在系统里加了‘模糊匹配’功能,”李明指着屏幕上的代码,“比如当检测到‘冷却’相关词汇时,会自动关联所有水循环系统的数据,但这样又会增加3%的误报率。”这种妥协在工业场景里很常见——某化工企业的安全监控系统甚至把“着火”“爆炸”“漏液”等危险词汇的同义词扩展到了500多个,导致系统运行时需要同时调用12个数据库进行交叉验证。
基于深度学习的语音系统:会“思考”的工业耳朵
与规则系统的“死记硬背”不同,深度学习语音系统更像是个会思考的学徒,在苏州某电子厂的SMT贴片车间,2026年新上线的“灵听”系统正在展示它的本领:当操作员说“把0402电容的贴装压力调高5%”时,系统不仅能准确识别指令,还能根据历史数据判断:“当前压力为0.2N,调高5%后为0.21N,但过去三个月该设备在0.22N时出现过元件倾斜,建议调整至0.215N。”
这种“懂上下文”的能力来自系统背后的神经网络模型,开发方腾讯云智能的负责人王芳透露:“我们用了2000小时的工业语音数据、50万条设备日志和3000个故障案例来训练模型,让它学会把语音指令、设备状态、历史维修记录甚至环境参数(如温度、湿度)进行关联分析。”在某汽车厂的测试中,这套系统对复杂指令的识别准确率比规则系统高出23%,还能主动提醒操作员:“您刚才说的‘调整焊接电流’与当前生产计划不符,是否确认执行?”
但深度学习也有它的“任性”时刻,2026年5月,深圳某精密制造厂的数控机床语音控制系统突然“罢工”——当工人说“把主轴转速降到8000转”时,系统却执行了“800转”的操作,调查发现,问题出在训练数据上:该厂使用的方言中,“八千”和“八百”的发音差异极小,而原始训练数据里这类方言样本不足100条,导致模型“听岔了”。
“现在我们在模型里加了‘方言适配器’,”王芳的团队正在为系统更新版本,“它会先通过声纹识别判断说话人是北方人还是南方人,再调用对应的语音模型进行解析。”这种“因地制宜”的调整在工业场景里至关重要——某风电企业的巡检系统甚至为内蒙古、新疆等地的风场开发了专门的语音模型,以适应当地工人浓重的口音。
基于知识图谱的语音系统:工业大数据的“翻译官”
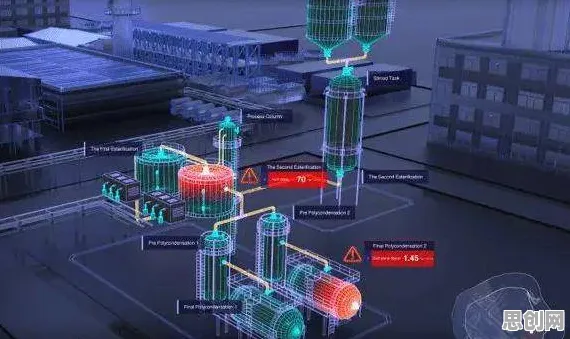
如果说规则系统是“字典”,深度学习是“学徒”,那么知识图谱系统就是“工业通”,在上海某化工园区的中央控制室,2026年上线的“智脑”系统正在展示它的核心能力:当监控员说“检查3号反应釜的温度异常”时,系统不仅调出了实时温度曲线,还自动关联了:“该釜上周刚完成催化剂更换”“当前原料批次与历史故障案例匹配度达78%”“同类型设备在类似工况下的故障概率为12%”——这些信息以可视化图表的形式呈现在大屏上,帮助监控员在30秒内做出判断。
“知识图谱的本质是把工业数据‘翻译’成机器能理解的语言,”开发方华为云的工程师陈浩解释,“我们把设备参数、工艺流程、维修记录、安全规范等数据抽象成‘实体-关系-属性’的结构,反应釜’是实体,‘温度’是属性,‘超过阈值’是关系,这样系统就能理解‘温度异常’意味着什么,以及可能引发什么后果。”
这种“结构化思维”在处理复杂工业场景时优势明显,2026年7月,某钢铁厂的高炉监控系统通过知识图谱发现了一个隐藏的关联:当“炉温连续3小时高于1500℃”且“冷却水流量低于设计值20%”时,虽然单项指标未达报警阈值,但组合起来会导致炉壁耐火材料加速损耗——系统据此提前48小时发出预警,避免了价值300万元的设备损坏。
2026年绿色港口与绿色重建及极限运动热度持续上升,相关产业迎来新发展 但构建知识图谱的代价也极其高昂,陈浩透露:“某汽车集团的知识图谱项目,我们投入了20名数据工程师、花了8个月时间,才把3000台设备、5000个工艺参数、20万条维修记录梳理成可用的图谱。”更棘手的是,工业数据每天都在更新——新设备上线、工艺改进、故障案例增加,都需要实时更新图谱,“现在我们的系统每24小时会自动扫描一次数据库,但即使这样,仍有15%的关联关系需要人工确认。”
三种系统的“混搭”才是未来
在2026年的工业现场,很少有企业会“押宝”某一种语音系统——更多是三种技术的混合应用,在重庆某智能工厂的案例中,规则系统负责处理90%的标准化指令(如“启动设备”“调取报表”),深度学习系统处理复杂指令和方言识别,知识图谱系统则专注于异常检测和决策支持,这种“分工协作”的模式,让系统的整体准确率达到98.7%,误报率控制在0.3%以下。
“就像开汽车需要油门、刹车和方向盘配合,”该厂信息化负责人刘伟打了个比方,“规则系统是油门,保证基础功能可靠;深度学习是刹车,处理突发情况;知识图谱是方向盘,指引最优路径。”这种比喻在2026年的工业界已成共识——某行业协会的调查显示,83%的制造企业正在采用“规则+深度学习”的混合方案,而知识图谱的渗透率也从2024年的12%跃升至2026年的47%。
2026年智能家居与绿色建筑领域迎来新发展,相关应用不断深化 但挑战依然存在,某风电企业的案例显示,当三种系统同时运行时,数据传输延迟会增加15%——规则系统需要0.5秒调取数据库,深度学习模型需要1.2秒进行推理,知识图谱的关联分析又要0.8秒,导致整体响应时间超过2.5秒,这在需要实时控制的场景里(如机床操作)是不可接受的。
“我们正在试验‘边缘计算+语音系统’的方案,”华为云的陈浩透露,“把部分计算任务下放到车间本地的服务器,让规则系统和简单深度学习模型在边缘端运行,知识图谱的核心分析留在云端,这样响应时间可以压缩到1秒以内。”这种“分层处理”的模式,或许会成为未来工业语音系统的主流架构。
工业语音系统的“隐形战场”
在2026年的工业大数据应用中,语音系统的竞争早已超越技术本身,延伸到数据安全、隐私保护甚至伦理领域,某汽车厂的案例引发了