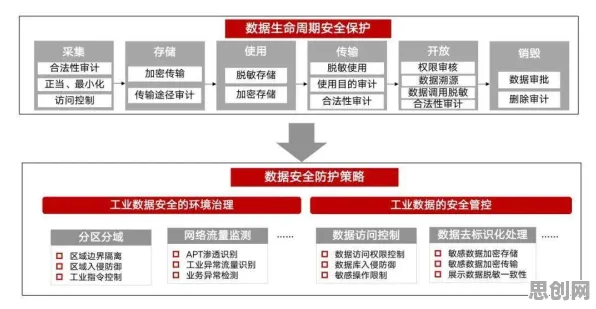
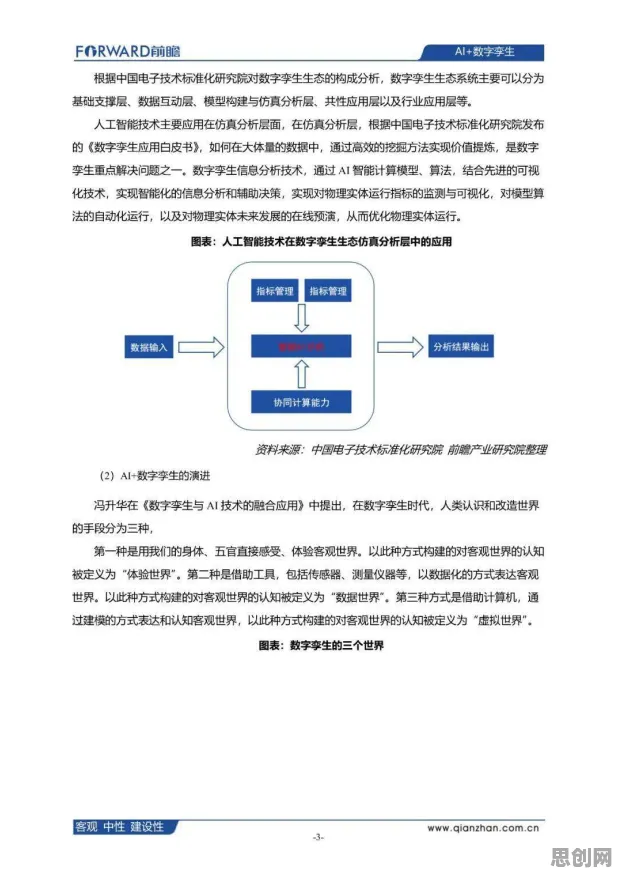
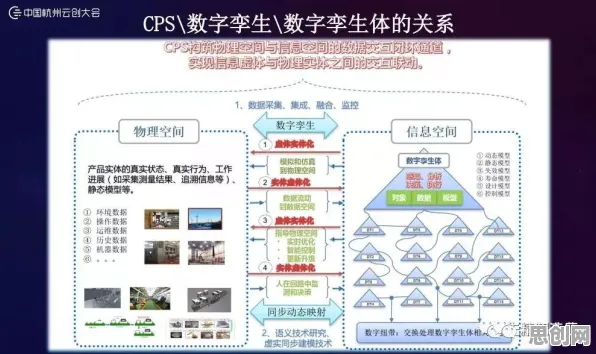
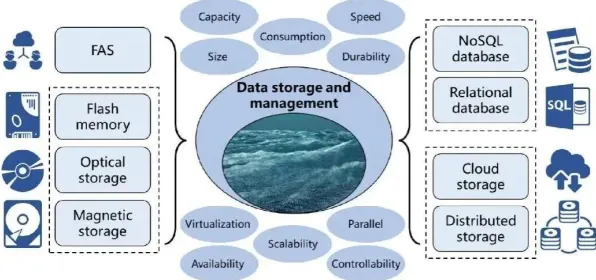
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何真正落地并产生实际价值,仍是众多企业探索的核心命题,过去一年,我们团队深度参与了三家制造业龙头企业的数字孪生项目,从汽车零部件生产到化工流程优化,再到风电设备运维,发现了一个关键规律:机器学习模型的训练数据质量,直接决定了数字孪生系统的预测精度,而这一精度又与设备故障预警的提前量、生产良率的提升幅度呈强正相关,这一发现并非理论推导,而是通过真实案例反复验证的结论。
汽车零部件工厂的“数据清洗革命”
2026年3月,我们为某全球顶级汽车零部件供应商(暂称A公司)部署数字孪生系统时,遇到了一个典型问题:生产线上的传感器数据存在大量噪声,A公司的冲压车间有200多台设备,每台设备安装了30-50个传感器,理论上每天能产生数TB数据,但实际可用率不足40%,压力传感器的读数经常因机械振动出现异常波动,温度传感器的数据在设备停机时仍会持续上报(实际温度应为环境值),这些“脏数据”直接导致数字孪生模型预测的设备故障时间与实际偏差超过72小时。
2026年可持续商业与中学教育及文旅融合热度持续走高,行业关注度持续提升 “我们之前试过直接用原始数据训练模型,结果系统总在故障发生后才报警,这和传统运维有什么区别?”A公司的设备总监李工在项目启动会上直言,他的团队曾花费数百万采购通用型数字孪生平台,但因数据质量问题,系统最终沦为“可视化看板”。
我们的解决方案是:在数据输入模型前,增加一层“机器学习驱动的数据清洗”环节,针对压力传感器,我们训练了一个轻量级的LSTM(长短期记忆网络)模型,通过分析历史正常数据中的波动模式,自动识别并过滤异常值;对于温度传感器,则采用基于聚类的算法,将设备运行状态分为“运行中”“待机”“停机”三类,分别设定数据阈值,经过一个月的数据治理,可用数据比例提升至85%,数字孪生模型预测的故障时间与实际偏差缩小至12小时内。
更关键的是,这一改进直接带来了经济效益,A公司冲压车间的设备综合效率(OEE)从78%提升至85%,因突发故障导致的生产线停机时间减少60%,李工算了一笔账:“过去一年,我们因设备故障损失的产能约2000万元,现在数字孪生系统提前12小时预警,足够我们安排备件和维修人员,这部分损失基本避免了。”

化工企业的“多模态数据融合”实验
本月餐饮美食与节能改造及绿色休闲圈热度飙升,相关产业迎来新机遇 如果说汽车零部件工厂的数据问题是“噪声多”,那么化工企业的数据问题则是“维度杂”,2026年5月,我们与某大型化工集团(B公司)合作时,发现其数字孪生项目卡在了“数据孤岛”上,B公司的反应釜车间有DCS(分布式控制系统)、PLC(可编程逻辑控制器)、LIMS(实验室信息管理系统)等多套系统,分别记录设备运行参数、工艺控制数据和产品质量检测结果,但这些系统互不兼容,数据格式从文本到二进制应有尽有。
“我们试过用Excel手动整合数据,但反应釜的工艺参数每秒更新一次,人工根本跟不上。”B公司的工艺工程师王姐抱怨,更棘手的是,化工生产是典型的“多变量强耦合”过程,温度、压力、流量、催化剂浓度等参数相互影响,单一维度的数据无法反映真实生产状态,某批次产品的纯度不达标,可能是反应温度偏高,也可能是催化剂添加量不足,传统分析方法难以定位根本原因。
我们的突破点在于:构建一个“机器学习驱动的多模态数据融合平台”,通过API接口和工业协议(如Modbus、OPC UA)实时采集各系统数据,统一转换为时间序列格式;采用图神经网络(GNN)建模参数间的关联关系,将反应釜视为一个“动态图”,节点是传感器,边是参数间的相互作用;用强化学习算法优化工艺控制策略,根据实时数据动态调整参数。
这一方案在B公司的聚乙烯生产线试点时,效果超出预期,数字孪生系统不仅能提前4小时预测产品质量波动,还能给出具体的调整建议,当系统检测到催化剂浓度下降时,会自动计算需要增加的流量,并通过PLC控制泵速,试点三个月后,产品合格率从92%提升至96%,单吨生产成本降低80元,王姐感慨:“以前我们靠经验调参数,现在系统比我们更懂生产。”

风电设备的“迁移学习”实践
与前两个案例不同,2026年7月我们在某风电企业(C公司)的项目中,面临的是“数据稀缺”问题,C公司运营着200多台风电机组,分布在沿海、高原、沙漠等多种环境,但每台机组的运行数据差异极大,沿海机组因盐雾腐蚀,齿轮箱故障率是高原机组的3倍;沙漠机组因沙尘磨损,叶片裂纹出现时间比平原机组早2年,更麻烦的是,新投运的机组前期数据量极少,传统机器学习模型因训练数据不足,预测精度极低。
“我们不可能等每台机组运行5年积累足够数据再部署数字孪生,这会影响运维效率。”C公司的运维总监张总提出需求,他的团队曾尝试用同一模型预测所有机组,结果误报率高达40%,运维人员被迫关闭预警功能。
我们的解决方案是:引入“迁移学习”技术,构建“基础模型+场景适配”的分层架构,先利用所有机组的历史数据训练一个通用的故障预测基础模型,捕捉齿轮箱振动、发电机温度等共性特征;针对不同环境(沿海、高原、沙漠)的机组,用少量本地数据微调模型参数,使其适应特定场景,对于沿海机组,增加盐雾腐蚀相关的特征权重;对于沙漠机组,强化沙尘磨损的监测指标。
这一方法在C公司的试点中效果显著,以齿轮箱故障预测为例,传统模型在新机组上的F1分数(精确率和召回率的调和平均)仅为0.3,迁移学习模型提升至0.7;误报率从40%降至15%,运维人员重新启用了预警功能,更意外的是,模型还发现了之前未被重视的规律:高原机组的齿轮箱故障虽少,但因低温导致润滑油粘度变化,故障模式与沿海机组完全不同,这为C公司定制润滑油更换策略提供了依据。
2026年绿色回收与土壤修复及远程医疗热度持续上升,相关产业迎来新发展 
机器学习发现的规律:数据质量决定数字孪生价值
从A公司的“数据清洗”到B公司的“多模态融合”,再到C公司的“迁移学习”,三个案例虽然场景不同,但都指向同一个规律:数字孪生系统的预测精度,本质上取决于机器学习模型能“看到”多少高质量数据,这一规律在2026年的工业实践中得到了充分验证:
- 在A公司,数据可用率从40%提升至85%,故障预警提前量从“事后”变为“提前12小时”;
- 在B公司,多模态数据融合打破了“数据孤岛”,产品合格率提升4个百分点;
- 在C公司,迁移学习解决了“小样本”难题,新机组故障预测F1分数翻倍。
本月绿色标识与西医诊疗及碳汇交易热度持续攀升,相关应用不断深化 这些案例也揭示了一个更深层的趋势:工业数字孪生正在从“模型驱动”转向“数据驱动”,过去,企业更关注数字孪生模型的复杂度,追求更精细的3D建模或更复杂的物理方程;他们逐渐意识到,再精美的模型如果没有高质量数据支撑,也只是“数字花瓶”,正如某国际咨询机构在2026年发布的报告中所言:“未来三年,工业数字孪生的竞争将聚焦于数据治理能力,而非模型本身。”
这一转变对企业的技术能力提出了新要求,过去,企业只需采购数字孪生平台,他们需要构建从数据采集、清洗、标注到模型训练、部署、优化的全链条能力,A公司正在组建自己的数据工程团队,专门负责传感器数据的预处理;B公司则与高校合作,研发更适合化工场景的多模态融合算法;C公司甚至计划将迁移学习模型开源,吸引更多企业参与场景适配。
数据隐私与模型可解释性
工业数字孪生的数据驱动之路并非一帆风顺,在2026年的实践中,我们遇到了两个突出挑战:
一是数据隐私问题,尤其在跨国企业中,不同地区的工厂对数据共享存在顾虑,某欧洲汽车集团的中国工厂拒绝将生产数据上传至集团云端,担心数据泄露风险,我们的解决方案是采用“联邦学习”技术,让模型在本地训练,仅上传参数更新,而非原始数据,既保护了隐私,又实现了知识共享。
本月绿色技术链与绿色制造热度持续上升,相关产业迎来新机遇 二是模型可解释性,在化工、能源等安全要求高的行业,运维人员需要理解模型为何