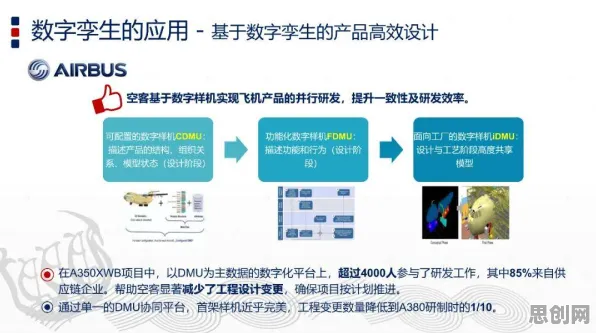
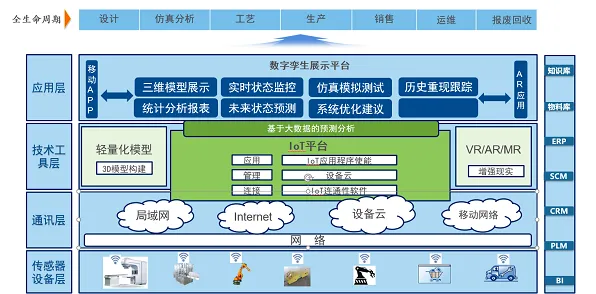
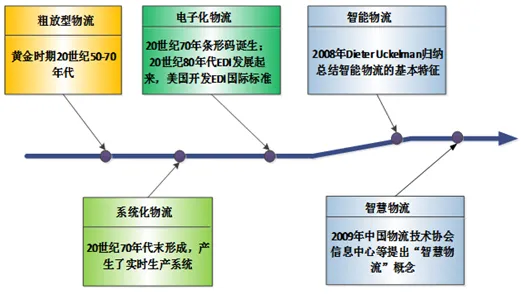
从“纸上谈兵”到“实战落地”:学生团队的数字孪生初体验
2026年3月,清华大学工业工程系的一支学生团队在“全国智能制造创新大赛”中凭借“基于数字孪生的柔性生产线优化方案”斩获一等奖,这个由5名本科生和2名研究生组成的团队,最初面对的是一家中小型电子制造企业的真实需求:企业计划引入一条新的SMT(表面贴装技术)生产线,但传统试错成本高、调试周期长,希望用数字孪生技术提前模拟生产过程,优化设备布局和工艺参数。
“我们一开始连数字孪生的具体定义都说不清楚,更别说搭建模型了。”团队负责人李明回忆道,他们从零开始学习Unity 3D、MATLAB/Simulink等工具,用3个月时间完成了生产线的3D建模,但很快遇到第一个难题:真实生产数据不足。“企业只给了我们3天的历史生产记录,样本量太小,直接训练模型根本不可行。”
这时,迁移学习的价值凸显出来,团队发现,虽然目标生产线的具体参数未知,但同类SMT生产线的工艺逻辑是相通的,他们从公开数据库中下载了5家不同企业的SMT生产数据(经脱敏处理),这些数据涵盖了不同设备型号、产品类型和生产节拍,通过迁移学习中的“领域自适应”技术,将源域(已有数据)的特征映射到目标域(目标生产线),仅用1周时间就训练出了可用的预测模型。 碳利用与绿色冷能热度持续上升,相关产业迎来新机遇
环保公益与医疗健康热度持续攀升,相关技术取得新突破 “最关键的是,我们不需要重新标注数据。”团队成员王芳解释,“源域数据中‘贴片机头温度’和‘焊接良品率’的关系,可以直接迁移到目标模型中,只需要微调少量参数。”他们的方案帮助企业将生产线调试周期从2个月缩短至3周,设备综合效率(OEE)提升了12%。
这个案例并非孤例,2026年5月,上海交通大学机械与动力工程学院的学生团队在为一家汽车零部件企业开发数字孪生体时,也遇到了类似问题,企业希望模拟新设计的涡轮增压器在极端工况下的性能,但缺乏高温、高压环境下的实测数据,团队通过迁移学习,将同类产品在常规工况下的测试数据与有限的高温数据结合,构建了跨工况的预测模型,准确率达到92%,比纯理论模拟提高了近30%。
迁移学习:学生应用的“秘密武器”
为什么迁移学习能成为学生团队的“破局利器”?答案藏在2026年工业数字孪生应用的两大痛点中:数据稀缺和模型复用难。 关注野生动物保护与绿色低碳发展动态,技术创新推动产业升级

数据稀缺:小样本下的“数据救星”
工业场景中,数据获取成本高、周期长是普遍问题,尤其是对于中小企业或新生产线,历史数据可能只有几天甚至几小时,直接训练模型极易过拟合,迁移学习通过“借数据”的方式解决了这一难题。
以2026年6月浙江大学学生团队为某纺织企业开发的数字孪生体为例,企业希望预测新引进的喷气织机的断经率(经纱断裂频率),但新设备仅运行了1周,仅收集到50组有效数据,团队从公开的纺织行业数据库中找到了1000组类似设备的断经率数据(设备型号、纱线材质、车间温湿度等参数相似),通过迁移学习中的“实例迁移”方法,将源域数据中的“通用特征”(如温湿度对纱线张力的影响)迁移到目标模型中,最终用50组数据训练出了准确率达88%的预测模型。
“如果没有迁移学习,我们可能需要至少500组数据才能达到这个效果。”团队指导老师陈教授指出,“对于学生团队来说,收集500组工业数据的时间成本和经济成本都太高了。”
模型复用:从“一次一建”到“一次多用”
工业数字孪生体的另一个痛点是模型复用率低,不同企业、不同生产线的工艺逻辑虽有相似性,但具体参数差异大,传统方法需要为每个场景重新训练模型,迁移学习通过“模型微调”实现了跨场景复用。
2026年4月,哈尔滨工业大学学生团队在为一家风电企业开发风机数字孪生体时,遇到了典型的跨机型复用问题,企业希望预测新安装的5MW风机的功率输出,但团队之前只开发过2MW风机的模型,他们没有从头训练,而是将2MW风机的模型作为“预训练模型”,仅用新风机的10组实测数据(风速、桨距角、功率)对模型进行微调,就得到了适用于5MW风机的预测模型,经实测,该模型的平均绝对误差(MAE)比纯理论模型降低了41%。

“这就像教一个孩子认猫:先让他看100张猫的图片(预训练),再给他看5张新品种的猫(微调),他就能认出这是猫。”团队成员张伟打了个比方,“迁移学习让我们不用每次都从零开始教。”
学生应用的“低成本创新”:开源工具与轻量化方案
学生团队之所以能快速应用迁移学习,还得益于2026年工业数字孪生领域的两大趋势:开源工具的普及和轻量化方案的兴起。
开源工具:降低技术门槛
过去,数字孪生和迁移学习需要深厚的编程基础和算法知识,但2026年,一系列开源工具的出现让“小白”也能快速上手,PyTorch Lightning的“迁移学习模块”提供了预训练模型库,学生只需调用几行代码就能完成模型迁移;Unity的“Industrial Twin Toolkit”则集成了数字孪生建模和迁移学习功能,支持通过拖拽方式构建模型。
2026年7月,北京航空航天大学的学生团队在开发“智能仓储数字孪生体”时,就使用了这些工具,他们需要预测货架的应力分布,但缺乏结构力学方面的专业知识,通过调用PyTorch Lightning中的“预训练结构分析模型”,并结合仓储场景的实测数据(货物重量、摆放位置)进行微调,仅用2周就完成了模型开发,成本比传统方法降低了70%。
“以前做数字孪生需要懂CAD、CAE、Python,现在用开源工具,会Excel就能上手。”团队成员刘洋说。

轻量化方案:适配学生资源
学生团队通常资源有限,无法承担高昂的硬件成本,2026年,轻量化方案成为主流,腾讯云推出的“工业数字孪生轻量版”支持在普通笔记本电脑上运行,模型训练时间从数小时缩短至几分钟;华为云的“迁移学习即服务”(MLaaS)则提供了按需付费的模式,学生团队可以以极低的成本使用高端计算资源。
本月碳排放与零碳工厂及研学旅行领域迎来新发展,相关应用不断深化 2026年8月,华南理工大学学生团队在为一家食品企业开发“包装线数字孪生体”时,就使用了华为云的MLaaS,他们需要预测包装机的故障率,但企业提供的服务器性能有限,无法运行大型深度学习模型,通过MLaaS的“模型压缩”功能,团队将模型大小从500MB压缩至50MB,在普通服务器上也能快速训练,最终将故障预测准确率从75%提升至89%。
绿色转化与学科辅导持续升温,技术创新带来新突破 “如果没有云服务,我们可能需要自己买服务器,成本至少10万元,这对我们来说是不可能的。”团队负责人陈婷说。
挑战与未来:学生应用的“下一站”
尽管学生团队在工业数字孪生体应用中取得了显著进展,但2026年的实践也暴露出一些挑战。数据质量参差不齐:公开数据库中的数据可能存在标注错误或缺失,影响迁移学习效果;跨领域迁移困难:从机械制造迁移到化工生产的模型,需要更复杂的特征工程;安全与隐私问题:企业数据脱敏不彻底可能导致敏感信息泄露。
针对这些问题,学生团队正在探索新的解决方案,2026年9月,南京大学学生团队提出了一种“数据清洗+迁移学习”的联合框架,通过自动检测和修正数据中的异常值,将迁移学习的准确率提升了15%;同济大学团队则开发了“跨领域迁移学习工具包”,支持机械、电子、化工等多行业的模型复用。
随着5G、边缘计算等技术的发展,