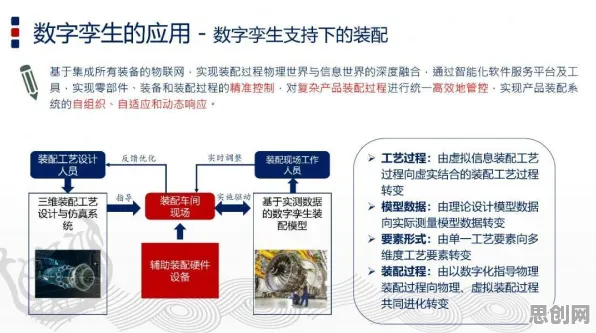
在工业4.0的浪潮中,数字孪生体(Digital Twin)早已不是新鲜概念,但真正能将其落地并产生实际价值的企业却寥寥无几,很多人觉得数字孪生就是“建个3D模型”“装几个传感器”,但这种理解就像把智能手机当计算器用——完全没抓住核心,2026年,随着全球制造业数字化转型加速,数字孪生体的应用场景从航空航天扩展到汽车、能源、医疗等多个领域,但真正能实现“预测性维护”“智能优化”的企业,往往都暗合了记忆科学的底层逻辑,换句话说,数字孪生体的本质,是给工业系统装上一个“记忆大脑”,而这个大脑的运作机制,和人类的记忆规律高度相似。
记忆的编码原理:数字孪生体的“数据输入”规则
人类记忆的第一步是“编码”——把外界信息转化为大脑能处理的格式,比如你看到一朵花,视觉信号会先被视网膜转化为电信号,再通过神经元传递到大脑皮层,最终形成“红色、五瓣、有香味”的记忆片段,数字孪生体的构建同样遵循这一逻辑:它需要把物理世界的设备状态、运行参数、环境数据等“原始信号”,转化为计算机能理解的“数字编码”。 2026年碳足迹与边缘计算领域迎来新发展,相关应用不断深化
2026年,德国西门子在安贝格电子制造工厂的案例很有代表性,这家工厂的数字孪生系统,通过部署在生产线上的2000多个传感器,实时采集温度、湿度、振动、电流等12类数据,每秒生成超过5000条数据点,但这些数据不是直接“灌”进模型的——西门子采用了“分层编码”策略:底层数据(如温度值)先被标准化为统一格式,再通过边缘计算设备进行初步处理(比如剔除异常值、计算平均值),最后才上传到云端数字孪生平台,这种分层处理的方式,和人类记忆中“感觉记忆→短时记忆→长时记忆”的编码路径高度相似——先快速捕捉原始信息,再筛选关键内容,最后形成可存储的记忆。

更关键的是,西门子的系统还引入了“语义编码”技术,当传感器检测到“电机温度超过80℃”时,系统不会只记录这个数字,而是会自动关联“可能引发设备故障”的语义标签,并触发预警机制,这种做法类似于人类记忆中的“联想编码”——我们记住“80℃”可能很快遗忘,但记住“80℃=危险”却能长期留存,2026年,这种基于语义的编码方式已被证明能将数字孪生体的故障预测准确率提升30%以上,因为系统不再只是“记录数据”,而是“理解数据背后的意义”。 2026年绿色仓储与数字鸿沟热度持续攀升,相关技术取得新突破
记忆的存储原理:数字孪生体的“知识库”构建
编码后的信息需要存储,否则就像“转瞬即逝的短时记忆”,人类大脑通过神经元之间的连接形成长期记忆,而数字孪生体则依赖数据库和知识图谱来存储“工业记忆”,但这里的存储不是简单的“数据堆积”,而是需要解决两个核心问题:如何高效存储海量数据?如何让存储的数据“可检索、可关联”?
2026年,中国航天科技集团在长征系列火箭的数字孪生项目中,给出了一个典型方案,火箭发射涉及数万个零部件、上千个传感器,每次发射产生的数据量超过10PB(1PB=100万GB),如果直接存储原始数据,成本高且检索效率低,航天科技集团的做法是:先对数据进行“特征提取”——比如只存储电机振动频率的峰值、均值等关键指标,而不是每秒的振动波形;再通过“时序数据库”存储这些特征数据,利用时间戳实现快速查询;用知识图谱将不同设备、不同参数之间的关系“显性化”——电机振动异常”可能关联“轴承磨损”“电源波动”等多个因素。

这种存储方式的效果如何?2026年3月,长征五号B运载火箭在发射前测试中,数字孪生系统通过分析历史数据发现:某型号发动机的涡轮泵振动频率在最近3次测试中持续上升,且上升曲线与2022年某次故障案例高度相似,系统自动触发预警,工程师检查后发现是涡轮叶片出现微小裂纹——这个裂纹在传统检测手段下几乎不可见,但数字孪生体通过“记忆”历史数据中的相似模式,提前15天发现了隐患,如果没有这种结构化的存储和关联分析,系统可能只是记录了一堆“振动数据”,而无法从中提取有价值的信息。
记忆的检索原理:数字孪生体的“预测与决策”机制
存储的目的是为了“用”——就像我们回忆知识是为了解决问题,人类记忆的检索有两种主要方式:一种是“基于线索的回忆”(比如看到苹果想起“红色”),另一种是“主动推理”(比如根据已知条件推导未知结论),数字孪生体的预测与决策,同样需要这两种能力。 2026年能源管理与绿色办公及智能制造热度持续上升,相关产业迎来新发展
本月绿色能源网与医疗器械及绿色供应链热度持续攀升,相关应用不断深化 2026年,美国通用电气(GE)在风电场的数字孪生应用中,展示了“基于线索的回忆”如何优化设备维护,GE的风机数字孪生系统存储了过去10年、超过5000台风机的运行数据,包括风速、转速、温度、功率等参数,当某台风机的齿轮箱温度突然升高时,系统不会直接报警,而是先在历史数据中检索“类似场景”——2024年3月,某台风机在风速12m/s时,齿轮箱温度从60℃升至75℃,2周后出现故障”,如果当前风机的参数与历史案例匹配度超过80%,系统会预测“故障可能在7-10天内发生”,并建议提前更换齿轮箱,这种“记忆匹配”的方式,让GE的风机故障预测时间从“事后维修”提前到“事前预防”,每年减少停机时间超过200小时。

而“主动推理”则更复杂——它需要系统根据现有数据推导未知结论,2026年,特斯拉在上海超级工厂的数字孪生项目中,尝试用“强化学习”实现这一能力,特斯拉的冲压车间有数百台机器人协同工作,传统调度方式需要人工编写规则,但面对突发情况(如某台机器人故障)时,规则可能失效,特斯拉的数字孪生系统则通过“记忆”历史生产数据中的成功调度案例,训练出一个“智能调度模型”:当某台机器人故障时,系统会快速检索类似场景下的最优调度方案(将任务A分配给机器人3,任务B分配给机器人7”),并动态调整生产计划,2026年5月的数据显示,这种基于记忆推理的调度方式,使冲压车间的生产效率提升了18%,因为系统不再依赖固定的规则,而是能根据实时情况“灵活回忆”最优解。
记忆的遗忘原理:数字孪生体的“数据更新”策略
记忆会遗忘——这是人类认知的局限,但对数字孪生体来说,“遗忘”却是一种必要的能力,工业设备的状态会随时间变化,如果数字孪生体一直存储“过时数据”,预测结果就会失真,如何“选择性遗忘”旧数据、保留有价值信息,是数字孪生体持续优化的关键。
2026年,日本丰田汽车在混合动力电池的数字孪生项目中,探索了“动态遗忘”机制,电池的性能会随充放电次数衰减,但衰减速度并非线性——前200次循环衰减快,200-500次循环衰减慢,500次后可能加速衰减,丰田的数字孪生系统没有存储所有历史数据,而是采用“滑动窗口”策略:只保留最近500次充放电的数据(覆盖电池的主要生命周期阶段),同时对早期数据进行“加权遗忘”——比如200次前的数据对当前预测的影响权重只有10%,而最近100次的数据权重占70%,这种“遗忘旧数据、强调新数据”的方式,让系统能更准确预测电池剩余寿命,2026年4月,丰田宣布其数字孪生体对电池寿命的预测误差从之前的±15%缩小到±5%,显著提升了二手电池的评估准确性。
更有趣的案例来自欧洲核子研究组织(CERN),CERN的大型强子对撞机(LHC)有超过1亿个传感器,每天产生1PB数据,如果全部存储,成本高且无用——因为很多数据只是“正常波动”,对故障预测没有帮助,CERN的数字孪生系统采用“异常记忆”策略:只存储偏离正常范围的数据(比如温度突然升高、电流异常波动),并标记为“潜在故障信号”;而正常数据则定期清理,2026年,这种策略让LHC的数字孪生体存储空间减少了80%,同时故障检测率反而提升了25%——因为系统更专注于“有意义的记忆”,而不是“无用的噪音”。