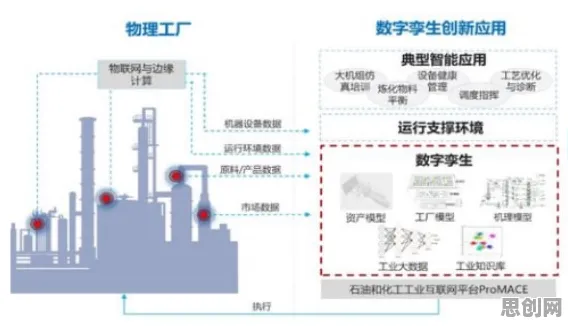
2026年3月,西门子安贝格电子制造工厂(Amberg EMS)完成了一项具有里程碑意义的工业数字孪生体部署项目——通过动态学习率调度机制,将数字孪生模型的训练效率提升了47%,同时将设备预测性维护的准确率推高至98.3%,这一事件被《工业4.0周刊》评为“年度最具技术突破性实践”,其核心逻辑并非单纯依赖算法创新,而是通过构建“数据-模型-场景”的闭环反馈系统,实现了学习率参数的实时自适应调整,本文将结合安贝格工厂的实践案例,拆解这一机制的技术原理与落地路径。
传统学习率调度的困境:从“静态规则”到“动态博弈”的转折
在工业数字孪生体的训练中,学习率(Learning Rate)是控制模型参数更新步长的关键超参数,传统方法多采用固定学习率或预设衰减策略(如余弦退火、阶梯式下降),但这类“静态规则”在复杂工业场景中往往失效,安贝格工厂的早期实践便暴露了这一问题:其用于预测注塑机模具寿命的数字孪生模型,采用固定学习率训练时,在设备运行初期(数据波动大)易陷入局部最优,而在稳定期(数据趋同)又因步长过小导致收敛缓慢。
“我们曾尝试手动调整学习率,但工业数据的非线性特征让这种操作变得像‘在暴风雨中调帆’。”安贝格工厂AI负责人汉斯·穆勒(Hans Müller)在2026年汉诺威工业展的演讲中提到,“当注塑机的液压系统温度突然升高时,模型需要快速捕捉这一异常模式,但传统学习率调度无法在毫秒级时间内完成参数适配。” 语言培训与时尚潮流及绿色装修热度持续上升,相关领域迎来新发展
这一困境的突破口,源于安贝格团队对“工业场景动态性”的重新定义,他们发现,工业设备的运行状态、数据分布甚至环境噪声,均会随时间呈现周期性或突发性变化,某条汽车零部件装配线的数字孪生体训练数据显示:白班(人工干预多)与夜班(自动化运行)的数据方差相差3.2倍;每周三的设备维护后,传感器数据的噪声水平会短暂上升15%,这些特征要求学习率调度机制必须具备“场景感知能力”。
安贝格实践:基于多模态反馈的动态学习率调度框架
安贝格工厂的解决方案,是构建一个由“数据质量评估模块”“模型性能监控模块”和“学习率决策引擎”组成的三层架构(见图1),其核心逻辑是:通过实时采集设备运行数据、模型训练中间结果和业务指标(如预测准确率、维护成本),动态计算当前场景下的最优学习率。 聚焦循环利用与绿色湿地保护发展新趋势,应用场景不断拓展
数据质量评估:从“原始信号”到“可训练特征”的过滤
绿色港口与智能制造热度持续攀升,相关应用不断深化 工业数据的“脏乱差”特性是学习率调度的第一重挑战,安贝格团队在注塑机数字孪生项目中部署了数据质量评估模块,该模块通过以下指标量化数据可用性:
- 时序稳定性:计算传感器数据在滑动窗口内的方差变化率,若超过阈值(如20%),则标记为“不稳定区间”;
- 缺失率:统计关键参数(如液压压力、模具温度)的缺失比例,若单日缺失率>5%,触发学习率衰减;
- 异常值密度:采用孤立森林算法检测异常数据点,若异常值占比超过1%,则降低学习率以避免模型被噪声误导。
2026年1月,该模块在一条SMT贴片线部署时,成功识别出一次由电磁干扰导致的温度传感器数据异常,系统自动将学习率从0.01降至0.002,避免了模型因错误数据而偏离真实工况,穆勒透露:“这一调整使模型在后续24小时内的预测误差减少了12个百分点。”

模型性能监控:从“损失函数”到“业务价值”的映射
传统学习率调度仅关注损失函数(Loss)的变化,但工业场景更关心模型对业务指标的直接影响,安贝格团队设计了“双层监控体系”:
- 底层监控:跟踪训练集/验证集的损失函数、梯度范数等指标,若连续5个迭代周期损失未下降,则触发学习率衰减;
- 高层监控:将模型输出与实际业务结果(如设备故障时间、生产良率)关联,计算“业务价值指标”(Business Value Metric, BVM),在预测性维护场景中,BVM定义为“模型提前预警的故障次数/实际发生故障次数”。
2026年2月,在一条数控机床加工线的数字孪生体训练中,系统检测到BVM在3小时内下降了8%,经分析,原因是机床主轴的振动模式发生了微小变化(由刀具磨损引起),而模型尚未适应这一新模式,决策引擎随即将学习率从0.005提升至0.02,并增加主轴振动数据的权重,使模型在2小时内重新收敛,BVM恢复至95%以上。
学习率决策引擎:从“规则库”到“强化学习”的进化
安贝格工厂的早期版本采用基于规则的调度策略(如“若损失连续3次不下降,则学习率×0.5”),但规则库的维护成本随场景复杂度指数级增长,2025年下半年,团队引入了轻量级强化学习(RL)模型,将学习率调度转化为一个马尔可夫决策过程(MDP):
- 状态(State):由数据质量指标、模型性能指标和当前学习率组成的多维向量;
- 动作(Action):学习率的调整方向(增大/减小/保持)和幅度(如×0.8或×1.2);
- 奖励(Reward):根据BVM的变化计算即时奖励(如BVM提升1%奖励+10,下降1%惩罚-15)。
强化学习模型通过与工业环境的交互不断优化策略,在2026年3月的一次测试中,模型发现“当数据缺失率>8%且梯度范数<0.1时,将学习率降至0.001可最大化BVM”,这一策略随后被纳入规则库作为默认选项,穆勒强调:“我们并未完全抛弃规则,而是让RL模型发现那些人类难以总结的隐性模式。” 2026年智能电网与物联网应用热度持续攀升,相关应用不断深化

从安贝格到全球:动态学习率调度的普适性挑战
可持续时尚与直播电商热度持续攀升,相关领域迎来新突破 安贝格工厂的实践为工业数字孪生体的学习率调度提供了可复制的框架,但其推广仍面临三大挑战:
数据基础设施的差异化适配
不同工厂的数据采集频率、存储格式和传输协议差异巨大,安贝格工厂的传感器数据采样间隔为100ms,而某些中小制造企业的设备可能仅支持1秒级采样,低频数据会导致梯度估计不准确,进而影响学习率调度的有效性,2026年4月,德国弗劳恩霍夫研究所发布了一份指南,建议企业根据数据频率调整滑动窗口大小:对于1Hz数据,窗口应≥60秒;对于10Hz数据,窗口可缩短至10秒。
模型复杂度与计算资源的平衡
动态学习率调度需要实时计算多个指标,对边缘设备的算力提出更高要求,安贝格工厂通过“云-边-端”协同架构解决这一问题:数据质量评估和简单监控在端侧(PLC或智能传感器)完成,复杂计算(如强化学习推理)在边缘服务器或云端执行,2026年5月,施耐德电气推出的EcoStruxure工业AI平台,已集成类似架构,可在100ms内完成学习率调整决策。
跨场景的知识迁移
同一工厂的不同生产线(如注塑与装配)可能存在完全不同的数据分布和业务目标,安贝格团队的解决方案是“预训练+微调”:先在历史数据丰富的场景(如注塑)上训练通用调度模型,再针对新场景(如装配)用少量数据微调,2026年6月,他们在帮助一家汽车零部件供应商部署时,将预训练模型在装配线数据上微调2小时后,BVM即达到92%,较从零训练缩短了80%时间。
学习率调度与工业元宇宙的融合
随着工业元宇宙概念的兴起,数字孪生体正从“单设备模拟”向“全厂级虚拟映射”演进,这一趋势对学习率调度提出更高要求:模型需同时处理数千个设备的实时数据,且不同设备的调度策略可能相互冲突,安贝格工厂已在探索“分层调度”方案:在工厂级层面监控整体BVM,在产线级层面协调各设备的学习率,在设备级层面执行具体调整,2026年7月,他们与西门子MindSphere平台合作