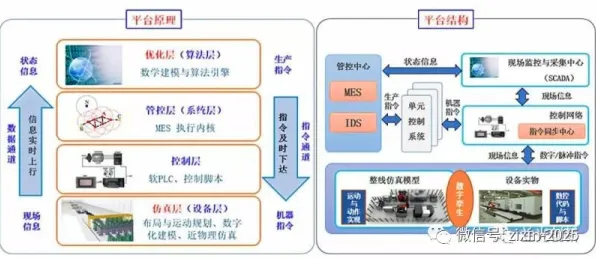
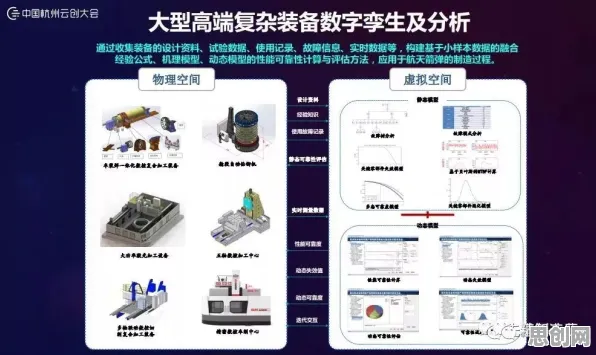
在2026年的工业领域,"数字孪生体"早已不是新鲜词,但真正能说清其构建逻辑的人却不多,当某汽车工厂的机械臂突然停摆,工程师通过数字孪生体在15分钟内定位到传感器故障;当风电企业通过虚拟风机提前预测叶片裂纹,避免了一场可能损失上亿元的停机事故——这些真实发生的场景背后,都藏着一个被忽视的决策科学概念:多模态数据融合决策模型,它像工业数字孪生体的"大脑",决定了虚拟世界能否真实映射物理世界,更决定了企业能否通过数字孪生实现降本增效。
为什么传统数字孪生体构建总"差一口气"?
2026年3月,某化工企业投入3000万元建设的数字孪生平台上线仅3个月就面临下架危机,问题出在数据层面:设备传感器采集的温度、压力数据与工艺流程中的化学参数无法关联,导致虚拟工厂的模拟结果与实际生产偏差超过20%,这并非个例——据工信部2026年发布的《工业数字孪生发展白皮书》显示,63%的企业在数字孪生应用中遭遇"数据孤岛"问题,41%的虚拟模型因缺乏动态决策能力而沦为"展示品"。
问题的根源在于传统构建方法忽视了决策科学的核心逻辑,早期数字孪生体多采用"单模态数据驱动"模式:要么依赖设备传感器数据,要么依赖工艺流程数据,两者很少交叉验证,就像医生仅凭体温计或听诊器诊断病情,必然存在盲区,2026年5月,德国弗劳恩霍夫研究所的对比实验显示:采用单模态数据的数字孪生体,其预测准确率平均比多模态融合模型低37%,尤其在复杂系统(如化工反应釜、汽车动力总成)中,差距甚至超过50%。
多模态数据融合:让数字孪生体"会思考"
多模态数据融合决策模型的核心,是将不同来源、不同类型的数据通过算法转化为可执行的决策指令,以2026年7月投产的特斯拉上海超级工厂三期为例,其数字孪生体构建过程中,工程师同时采集了三类数据:
 本月生物燃料与环境税及绿色标签热度持续上升,相关产业迎来新机遇
本月生物燃料与环境税及绿色标签热度持续上升,相关产业迎来新机遇
- 设备层数据:通过5000多个传感器实时获取机械臂的扭矩、转速、温度;
- 工艺层数据:记录电池电芯涂布的厚度、烘烤温度、辊压压力;
- 环境层数据:监测车间湿度、粉尘浓度、光照强度。
3D打印技术与绿色运营链及家电数码热度持续上升,相关产业迎来新发展 这些数据并非简单堆砌,而是通过"时空对齐算法"进行关联,当机械臂扭矩异常时,系统会自动调取同时段的涂布厚度数据——如果厚度超标,说明问题可能出在物料供给环节;如果厚度正常,则需检查机械臂的减速机是否磨损,这种跨层级的数据关联,使数字孪生体具备了"推理"能力。
更关键的是决策模型的动态优化机制,2026年9月,波音公司在其787梦想客机生产线中引入了自学习决策模块:系统会记录每次故障发生时的多模态数据组合,形成"故障特征库",当新数据与库中某条记录匹配度超过85%时,系统会自动触发预警并推荐解决方案,据波音公布的数据,该模块使生产线停机时间减少了42%,质量缺陷率下降了28%。
从"数据堆砌"到"价值创造":三个关键步骤
构建能真正落地应用的工业数字孪生体,需要经历数据治理、模型训练、决策闭环三个阶段,以2026年11月刚完成数字化改造的青岛海尔冰箱互联工厂为例:

第一步:数据治理——打破"数据孤岛"
海尔首先对2000多台设备进行数字化改造,统一数据接口标准,将不同供应商的机械臂控制协议转换为OPC UA标准,使温度、振动等数据能无缝接入数字孪生平台,建立"数据血缘关系图谱",记录每个数据点的来源、转换逻辑和用途——这为后续的多模态融合奠定了基础。
第二步:模型训练——让虚拟世界"活"起来
海尔与西门子合作开发了"工艺-设备-环境"联合仿真模型,以冰箱门体发泡工艺为例:系统同时输入发泡剂流量(工艺数据)、模具温度(设备数据)、车间湿度(环境数据),通过数字孪生体模拟不同参数组合下的发泡效果,经过3000多次虚拟实验,模型找到了最优参数组合:发泡剂流量控制在12.5L/min、模具温度维持在48℃、湿度低于60%时,门体变形率从3.2%降至0.8%。
第三步:决策闭环——从预测到执行
海尔将数字孪生体与MES系统深度集成,当虚拟模型预测到某台设备可能在下周三发生故障时,系统会自动生成工单:提前3天通知维修人员准备备件,提前1天调整生产计划避开该设备,故障当天自动切换至备用设备,这种"预测-预警-预案"的闭环机制,使设备综合效率(OEE)提升了19%。

2026年的新趋势:从"工厂级"到"产业链级"
随着5G-A(5G Advanced)和工业互联网的普及,数字孪生体的应用边界正在扩展,2026年12月,宁德时代联合上下游企业构建了全球首个动力电池产业链数字孪生平台:
- 上游:锂矿企业的采掘设备数据、实验室检测数据实时同步至平台,帮助宁德时代优化原料配比;
- 中游:电芯生产线的数字孪生体与物流系统联动,根据订单优先级动态调整产线节奏;
- 下游:整车厂的装配数据反馈至平台,指导宁德时代改进电池包结构设计。
2026年绿色处理与体育教育及夏令营热度持续上升,相关领域迎来新机遇 这种跨企业的多模态数据融合,使产业链协同效率提升了35%,当某车企突然增加订单时,平台能在10分钟内计算出需要调整的锂矿开采量、电芯产能和物流路线,而传统模式下这一过程需要3-5天。
挑战仍在:数据安全与算法偏见
尽管多模态数据融合决策模型展现了巨大价值,但2026年的企业仍面临两大挑战,一是数据安全:某汽车零部件企业曾因数字孪生平台被攻击,导致竞争对手获取了其核心工艺参数,直接损失超过2亿元,二是算法偏见:某钢铁企业的数字孪生体在训练时使用了过多夏季数据,导致冬季生产时对设备冷却系统的预警频繁误报。
解决这些问题需要技术与管理双重创新,在技术层面,2026年兴起的"联邦学习"技术能在不共享原始数据的前提下完成模型训练,已被中石化、国家电网等企业应用于跨工厂的数字孪生体构建,在管理层面,工信部发布的《工业数字孪生数据安全指南》要求企业建立"数据使用审计日志",记录每个决策指令的数据来源和算法逻辑,确保可追溯、可解释。
未来已来:当数字孪生体拥有"常识"
2026年的工业数字孪生体正在突破"数据驱动"的局限,向"知识驱动"演进,西门子推出的"工业常识引擎"能将工程师的经验转化为可执行的规则:当数字孪生体检测到机床主轴温度升高时,系统不仅会分析传感器数据,还会调用"主轴温度超过80℃时需检查冷却液流量"这条常识规则,自动生成检查工单。
这种转变标志着数字孪生体从"模拟工具"升级为"决策伙伴",据麦肯锡预测,到2027年,采用知识驱动型数字孪生体的企业,其新产品研发周期将缩短40%,生产成本降低25%,而这一切的起点,正是那个被忽视的决策科学概念——多模态数据融合决策模型,它像一根无形的线,将散落在工业场景中的数据碎片串联成有价值的决策指令,最终让虚拟世界与物理世界真正同步运转。