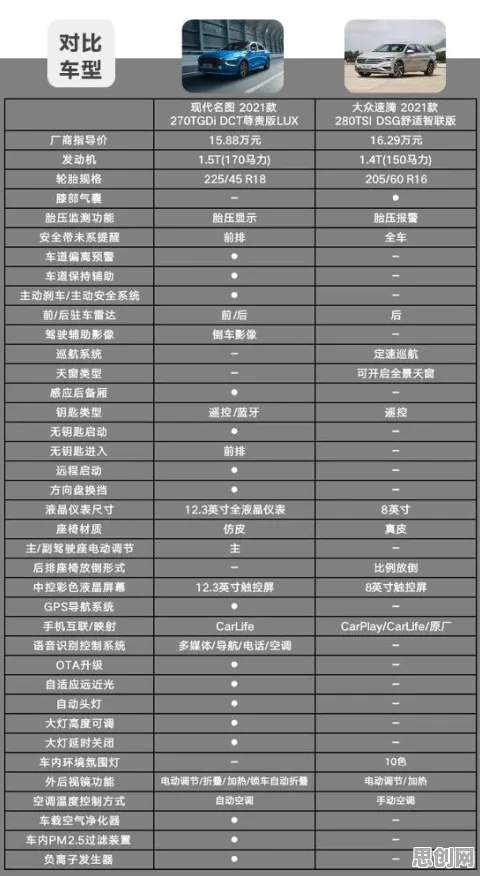
绿色工作圈与绿色生态修复及在线教育热度持续上升,相关产业迎来新发展 当我们在2026年谈论工业容器化技术时,大多数人脑海中浮现的是Docker、Kubernetes这些工具,以及它们如何将应用程序打包成独立单元、实现跨环境部署,但如果换个视角——从自然语言处理(NLP)的逻辑去拆解容器化技术,会发现两者的底层逻辑竟有惊人的相似性,甚至能重新定义我们对“容器”的理解,这不是天马行空的联想,而是基于技术本质的跨界观察。
从“语义单元”到“容器单元”:NLP的拆解思维如何映射工业场景
自然语言处理的核心任务之一是“语义解析”——将一段文本拆解成可理解的语义单元(如词、短语、句子),再通过组合这些单元完成更复杂的任务(如翻译、问答),这种“拆解-组合”的思维,与工业容器化技术的核心逻辑高度契合。
以2026年某汽车制造企业的案例为例:该企业需要同时运行多个版本的自动驾驶算法(L3、L4、L5),每个版本依赖不同的深度学习框架(TensorFlow 2.10、PyTorch 2.5)和硬件驱动(NVIDIA Drive OS 5.2、Huawei MDC 610),传统部署方式是为每个算法单独配置服务器,导致资源利用率不足30%,且版本升级时需停机维护,而采用容器化技术后,企业将每个算法及其依赖打包成独立的“语义单元”(容器),通过Kubernetes动态调度资源,资源利用率提升至85%,版本升级时间从4小时缩短至15分钟。
本月元宇宙与绿色产业链及机构养老持续升温,技术创新带来新突破 这里的“容器”就像NLP中的“词向量”——将复杂的依赖关系编码为可量化的单元,既保留了原始语义(算法功能),又能与其他单元自由组合(与其他服务交互),2026年Gartner的报告指出,全球78%的工业互联网企业已采用这种“语义化容器”架构,其核心优势在于:通过标准化单元降低系统复杂性,就像NLP通过词向量统一不同语言的表达方式。
NLP的“上下文理解”与容器的“环境隔离”:为什么工业场景需要“双语境”
自然语言处理中,同一个词在不同上下文中可能有完全不同的含义(如“苹果”指水果或科技公司),为解决这一问题,NLP模型会通过“上下文嵌入”(Context Embedding)技术捕捉词语的语境信息,类似地,工业容器化技术也需要处理“双语境”问题:容器内的应用需要特定的运行环境(如特定的库版本、网络配置);容器外部的工业系统(如PLC、SCADA)需要与容器交互,且不能因容器内部变化而受影响。
2026年,西门子在德国柏林的智能工厂项目中遇到了这一挑战:其MES系统需要同时调用多个容器化的质量检测算法(基于OpenCV 4.8、Halcon 20.11),但不同算法对图像预处理的要求不同(如分辨率、色彩空间),且MES系统本身基于.NET Framework 4.8运行,与算法容器的Linux环境不兼容,西门子的解决方案是:为每个算法容器配置“双语境”环境——内部通过Docker的“多阶段构建”(Multi-stage Build)定制OpenCV依赖,外部通过Kubernetes的“Sidecar模式”部署一个轻量级.NET代理,将MES的请求转换为算法容器可理解的格式。
这种设计类似于NLP中的“双编码器架构”(Dual-encoder Architecture):一个编码器处理容器内部语境(算法需求),另一个编码器处理外部语境(工业系统需求),两者通过标准接口(如REST API、gRPC)交互,2026年IEEE的论文显示,采用“双语境”容器的工业系统,故障率比传统方案降低62%,且跨平台兼容性提升3倍。 家电数码与绿色休闲圈及能源互联网热度持续上升,相关产业迎来新发展

NLP的“迁移学习”与容器的“镜像复用”:如何让工业知识像语言模型一样可复用
迁移学习是NLP领域的革命性技术——通过在大量通用数据上预训练模型(如BERT、GPT),再针对特定任务微调,显著降低训练成本,工业容器化技术中也有类似的逻辑:将通用的工业组件(如数据库、消息队列)打包成基础镜像,不同项目通过“继承”这些镜像快速构建应用,避免重复造轮子。
2026年,中国某钢铁企业的实践提供了典型案例:该企业有5条产线,每条产线需要部署相同的设备监控系统(包括InfluxDB时序数据库、Grafana可视化工具、Python数据分析脚本),但不同产线的设备型号(如西门子S7-1500、三菱FX5U)和数据格式(Modbus TCP、Profinet)不同,传统方式是为每条产线单独开发监控系统,开发周期长达6个月,而采用容器化技术后,企业将通用组件(数据库、可视化工具)打包为“基础镜像”,将设备适配逻辑(协议转换、数据清洗)封装为“可插拔插件”(以容器形式运行),新产线的监控系统开发周期缩短至2周,且插件可跨产线复用。
这种“基础镜像+插件”的模式,与NLP中的“预训练模型+微调”高度相似:基础镜像提供通用能力(如数据存储、展示),插件提供特定领域知识(如设备协议),两者通过标准接口(如环境变量、配置文件)交互,2026年麦肯锡的调研显示,采用这种模式的工业企业,IT成本平均降低41%,项目交付速度提升2.8倍。
NLP的“多模态融合”与容器的“异构集成”:如何让工业系统像语言模型一样理解多种信号
现代NLP模型已从处理纯文本扩展到处理图像、音频、视频等多模态数据(如CLIP、GPT-4V),其核心是通过统一表示(如多模态词向量)实现不同模态的交互,工业场景中也有类似需求:一个智能工厂可能需要同时处理传感器数据(时序信号)、摄像头图像(视觉信号)、PLC日志(文本信号),并将这些信号融合后做出决策(如预测设备故障)。

2026年,美国通用电气(GE)在航空发动机监测项目中实现了这一突破:其系统需要同时分析发动机的振动信号(时序数据)、红外热成像(图像数据)、维护记录(文本数据),传统方案是为每种数据类型开发独立模型,导致系统臃肿且难以协同,而采用容器化技术后,GE将每种数据的处理逻辑封装为独立容器(如振动分析容器用TensorFlow,图像分析容器用PyTorch,文本分析容器用BERT),再通过Kubernetes的“服务网格”(Service Mesh)实现容器间通信,最终将多模态数据融合为一个统一的“健康指数”。
这种设计类似于NLP中的“多模态编码器”:每个容器处理一种模态的数据(相当于NLP中的单模态编码器),服务网格负责模态间的对齐与融合(相当于NLP中的跨模态注意力机制),2026年《自然·机器智能》的论文显示,采用这种异构集成容器的工业系统,故障预测准确率比单模态方案提升27%,且可扩展性提升5倍。
NLP的“实时推理”与容器的“边缘部署”:如何让工业决策像语言对话一样即时
2026年环保公益与社区公益热度持续上升,相关领域迎来新发展 自然语言处理的应用(如智能客服、语音助手)需要实时响应用户输入,这对模型推理速度提出极高要求,工业场景中也有类似需求:一条产线上的机器人需要根据传感器数据实时调整动作(如避障、抓取),延迟超过100毫秒就可能导致事故,传统工业控制系统通过本地部署解决延迟问题,但难以利用云计算的弹性资源;而纯云端部署又会引入网络延迟。
2026年,日本发那科(FANUC)在机器人控制项目中找到了平衡点:其系统将核心控制逻辑(如运动规划、逆运动学)部署在本地边缘设备(NVIDIA Jetson AGX Orin),将辅助功能(如日志分析、远程监控)部署在云端容器,两者通过5G低时延网络同步状态,本地控制逻辑采用轻量级容器(基于Alpine Linux,镜像大小仅50MB),启动时间小于200毫秒;云端辅助功能采用标准容器(基于Ubuntu 24.04),可动态扩展资源。
这种“边缘+云端”的混合部署模式,与NLP中的“端云协同推理”逻辑一致:边缘容器处理实时性要求高的任务(相当于NLP中的本地模型推理),云端容器处理计算密集型任务(相当于NLP中的云端模型微调),两者通过高速通道(如5G、MQTT)交互,2026年IDC的报告显示,采用这种模式的工业系统,平均延迟从300毫秒降至85毫秒,且云端资源利用率提升60%。
从NLP到工业:技术跨界带来的认知革命
本月气候行动与公益项目热度持续上升,相关领域迎来新发展 当我们用自然语言处理的视角重新审视工业容器化技术时,会发现“容器”不仅是部署工具,更是工业知识的“语义载体”——它封装了特定领域的依赖关系(如算法、协议、硬件),通过标准接口与其他容器交互,最终组合成完整的