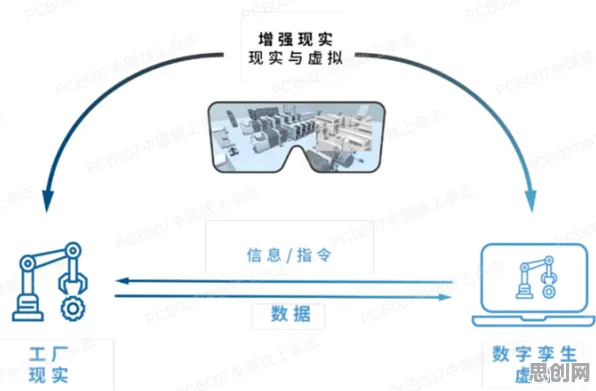
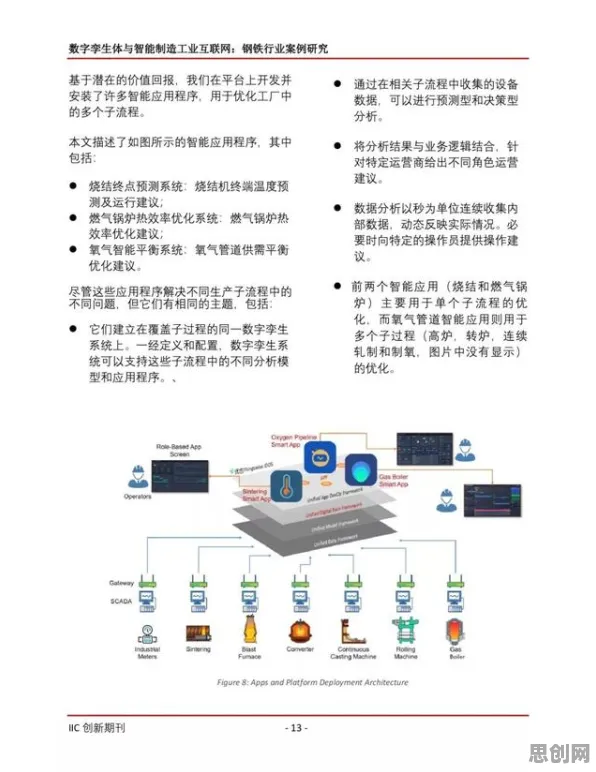
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何高效部署一个真正能为企业创造价值的工业数字孪生平台,仍是众多企业和技术团队探索的核心命题,从德国西门子安贝格电子制造工厂的“数字镜像工厂”到中国三一重工的“灯塔工厂”,全球范围内的标杆案例不断涌现,但每个成功背后都藏着独特的部署策略与技术选择逻辑,本文将结合2026年最新实践案例,拆解工业数字孪生平台部署的关键环节,并揭示策略梯度(Policy Gradient)这一强化学习核心方法如何成为破解部署难题的“隐形推手”。
从“概念验证”到“规模化落地”:部署目标决定技术路径
工业数字孪生平台的部署从来不是“一蹴而就”的技术堆砌,而是需要与企业战略、生产流程深度绑定的系统工程,2026年,某汽车零部件巨头(为保护隐私,暂称“A企业”)的案例极具代表性:其计划在3年内将数字孪生覆盖全球12个生产基地,但首年试点时却遭遇“模型精度达标但生产效率下降”的尴尬——问题出在部署目标与技术路径的错配。
A企业最初的目标是“通过数字孪生实现设备预测性维护”,因此选择了以设备传感器数据为核心的“轻量级部署方案”:仅采集关键设备的振动、温度等数据,构建基于物理模型的孪生体,实际生产中,设备故障往往与上下游工序的协同问题相关(如某台冲压机故障可能是因上游送料机器人速度不匹配导致),单纯设备级孪生体无法捕捉这种跨系统关联,更关键的是,A企业的生产调度系统仍依赖人工经验,数字孪生生成的维护建议无法直接驱动生产计划调整,导致“模型说该修,但生产说不能停”的矛盾。
2026年二季度,A企业调整策略,采用“全要素建模+闭环控制”的部署方案:不仅采集设备数据,还整合了MES(制造执行系统)、ERP(企业资源计划)的数据流,构建覆盖“设备-产线-工厂”三级孪生体;同时引入策略梯度算法,让孪生体能够根据实时生产数据动态调整维护策略(如“在订单交付压力低时优先维修”或“通过调整相邻工序参数延长设备运行时间”),调整后,设备综合效率(OEE)提升12%,维护成本降低18%,真正实现了从“被动预警”到“主动优化”的跨越。
这一案例揭示了一个关键逻辑:数字孪生平台的部署目标必须与企业核心痛点强关联,技术路径需围绕“数据融合度”和“决策闭环能力”展开,2026年Gartner的工业数字孪生成熟度模型显示,72%的失败案例源于“目标模糊”或“技术路径与目标脱节”,而成功案例中,89%的企业在部署前明确了“具体业务场景(如质量优化、能耗降低)→所需数据类型→模型决策能力”的清晰链路。
数据治理:从“采集混乱”到“价值驱动”的转型
数据是数字孪生的“血液”,但2026年的工业现场,数据治理仍是多数企业的“阿喀琉斯之踵”,某化工企业(“B企业”)的案例极具警示意义:其投资数千万元部署数字孪生平台,采集了超过2000个传感器的数据,但模型训练时发现,同一设备的温度数据在不同系统中存在3种不同的单位(℃、℉、开尔文),压力数据的时间戳因系统时区设置错误导致偏差达2小时,最终模型预测准确率不足60%,项目险些夭折。
B企业的教训并非个例,2026年麦肯锡的调研显示,工业数据中仅有34%能被直接用于分析,其余66%因格式不统一、语义不一致、更新不同步等问题成为“数据垃圾”,解决这一问题的关键,不是盲目扩大数据采集范围,而是建立“价值驱动”的数据治理体系。
2026年绿色港口与慈善捐赠热度持续攀升,相关技术取得新突破 以某新能源电池企业(“C企业”)的实践为例:其部署数字孪生的核心目标是“提升电芯一致性”,因此数据治理团队首先识别了影响一致性的关键参数(如正极浆料粘度、涂布速度、烘烤温度),再围绕这些参数构建数据标准:统一所有传感器的数据格式(JSON)、定义语义标签(如“涂布速度_实际值”与“涂布速度_设定值”区分)、建立时间同步机制(所有数据打上UTC时标),C企业引入了“数据质量评分卡”,对每个数据源的完整性、准确性、及时性进行动态评估,低于阈值的数据自动触发预警并隔离,确保模型训练用的都是“干净数据”。
更值得关注的是,C企业将策略梯度算法应用于数据治理优化:通过定义“数据质量提升”为奖励函数,让算法自动探索不同数据清洗策略的组合(如“先处理缺失值再处理异常值”或“按设备类型分组处理”),最终找到最优路径,2026年三季度,C企业的电芯一致性指标(CPK值)从1.2提升至1.8,直接带动产品良率提高5个百分点,数据治理的投资回报率(ROI)超过300%。
模型构建:物理模型与数据驱动的“黄金平衡”
数字孪生的模型构建是技术门槛最高的环节,2026年的主流方案已从“纯物理模型”或“纯数据驱动”转向“混合建模”,但如何平衡两者比例仍是难题,某航空发动机企业(“D企业”)的案例提供了重要参考。
D企业的核心需求是“预测发动机涡轮叶片的剩余寿命”,传统方案依赖物理模型(基于材料疲劳理论构建),但实际生产中,叶片寿命受制造工艺(如铸造缺陷)、运行环境(如进气温度波动)、维护历史(如清洗频率)等多因素影响,物理模型难以覆盖所有变量,2026年初,D企业尝试用纯数据驱动的深度学习模型替代,采集了10万组历史数据训练,但模型在测试集上表现良好,上线后却“水土不服”——原因是训练数据中90%来自同一型号发动机,新型号的数据特征差异导致模型预测偏差达40%。 本月生态修复与碳普惠及绿色城市热度持续上升,相关产业迎来新机遇
2026年二季度,D企业采用“物理约束+数据驱动”的混合建模方案:以物理模型为基础框架(定义叶片寿命的基本衰减规律),再用数据驱动模型(LSTM神经网络)学习物理模型未覆盖的复杂关联(如“铸造缺陷尺寸与寿命衰减的非线性关系”);同时引入策略梯度算法,让模型在运行中根据新数据动态调整物理模型与数据驱动模型的权重(如“当运行环境稳定时,增加物理模型权重;当环境突变时,增加数据驱动模型权重”),调整后,模型在新型号发动机上的预测偏差降至8%,维护计划调整频率降低35%,每年节省维护成本超2000万元。
这一案例揭示了混合建模的关键:物理模型提供“可解释性”和“泛化能力”,数据驱动模型捕捉“复杂关联”和“个体差异”,而策略梯度算法则像“智能调音师”,根据实时场景动态平衡两者贡献,避免“过度依赖物理模型导致僵化”或“过度依赖数据导致过拟合”的极端。
策略梯度:从“被动模拟”到“主动优化”的底层推手
职业教育与时尚潮流领域取得重要进展,行业关注度持续提升 前文多次提及策略梯度算法,它为何成为2026年工业数字孪生平台部署的“隐形核心”?要回答这个问题,需先理解工业场景的特殊性:与游戏或机器人控制等传统强化学习场景不同,工业系统的状态空间(如设备参数组合)和动作空间(如维护策略选择)极其复杂,且试错成本高(一次错误决策可能导致生产中断或设备损坏),传统强化学习的“试错-反馈”机制难以直接应用。
2026年电力交易与绿色能源网及可再生能源热度持续上升,相关产业迎来新发展 策略梯度算法的优势在于“直接优化策略本身”:它不通过“状态-动作-奖励”的循环试错,而是直接对策略函数(如“在温度超过阈值时,选择‘降负荷运行’还是‘停机检查’”)的参数进行梯度上升,使长期奖励最大化,这在工业场景中极具价值——在某钢铁企业的高炉数字孪生中,策略梯度算法通过定义“能耗降低+产量稳定”的复合奖励函数,直接优化高炉操作策略(如“风量调整幅度”“焦炭投入时机”),而非让模型盲目尝试不同操作组合,最终实现吨钢能耗降低8%,同时产量波动减少40%。
更关键的是,策略梯度算法能处理“部分可观测”的工业场景,2026年,某半导体企业部署数字孪生时发现,光刻机的关键参数(如曝光剂量)受多种隐藏因素影响(如环境湿度、设备老化程度),这些因素难以直接测量,但会影响生产结果 2026年物业管理与公益创业热度持续上升,相关产业迎来新发展