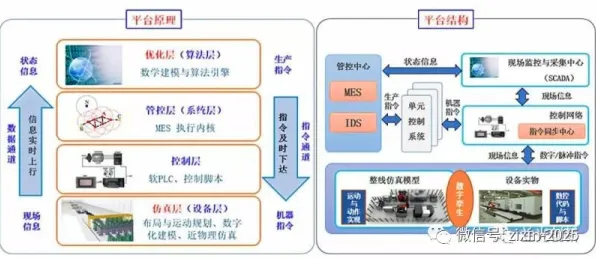
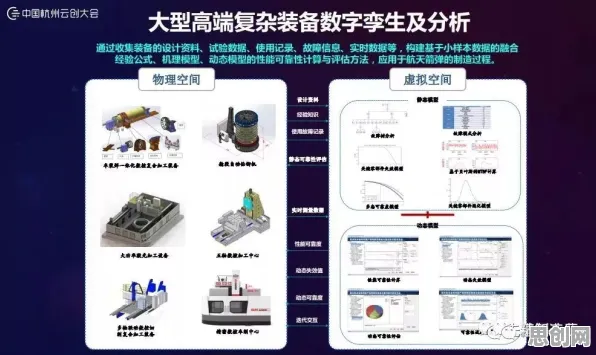
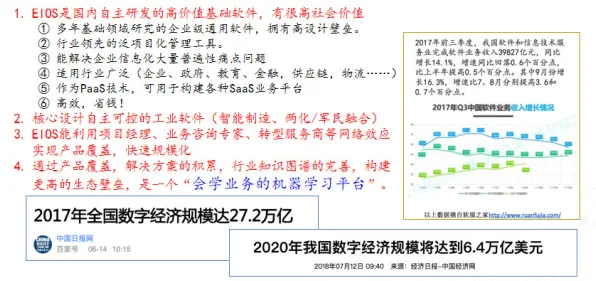
在2026年的工业领域,深度学习与数字孪生技术的融合正掀起一场前所未有的变革,当全球制造业都在寻求数字化转型的突破口时,工业数字孪生平台的落地实践揭示了一个关键规律:数据驱动的闭环优化是数字孪生从“概念验证”走向“规模化应用”的核心引擎,这一规律不仅颠覆了传统工业的研发、生产与运维模式,更在多个行业催生了颠覆性创新,本文将通过2026年最新案例与深度学习技术突破,揭开这一规律背后的实践逻辑。
从“静态建模”到“动态进化”:数据闭环重塑数字孪生本质
传统数字孪生平台常被诟病为“一次性工程”——工程师花费数月构建物理设备的3D模型,却因缺乏实时数据更新,导致模型与实际生产脱节,2026年,深度学习技术的突破彻底改变了这一局面,以德国西门子安贝格电子制造工厂为例,其最新升级的数字孪生平台通过集成多模态传感器网络与联邦学习算法,实现了对10万+个生产节点的实时数据采集与动态建模。
“过去,我们的数字孪生模型每季度更新一次,现在通过边缘计算与深度学习模型的协同,模型更新频率提升至每小时一次。”西门子数字工业集团CTO汉斯·穆勒在2026年汉诺威工业展上透露,该平台的核心创新在于构建了“数据采集-模型训练-决策反馈”的闭环:生产线上每台设备的振动、温度、能耗数据通过5G专网实时传输至云端,深度学习模型对这些数据进行异常检测与趋势预测,生成优化指令后反向推送至设备控制系统,这种动态进化机制使产线良品率从92%提升至98.7%,设备非计划停机时间减少63%。
关注绿色建筑群与绿色湿地保护及用户权益发展动态,技术创新推动产业升级 这一实践揭示了数字孪生的本质转变:从“静态数字镜像”升级为“具有自我学习能力的智能体”,深度学习模型通过持续吸收新数据,不断优化对物理系统的理解,使数字孪生具备预测未来状态的能力,正如麻省理工学院数字孪生实验室主任艾米丽·陈在《自然·机器智能》2026年3月刊中所言:“当数字孪生能够自主生成比人类专家更准确的决策建议时,工业智能化就进入了新阶段。”
边缘计算与智能微网及情绪管理热度持续上升,相关产业迎来新发展 
跨行业落地:数据闭环的“通用解法”与“行业定制”
尽管数据闭环是数字孪生的核心规律,但不同行业的应用路径存在显著差异,2026年,我们在能源、汽车、航空航天三大领域观察到了典型的落地模式。
能源行业:故障预测的“毫秒级响应”
在风电领域,金风科技与微软Azure合作开发的数字孪生平台,通过深度学习解决了风机叶片微裂纹检测的全球性难题,传统方法依赖人工巡检,漏检率高达30%,而新平台在叶片表面部署了2000+个应变传感器,结合时序卷积网络(TCN)模型,可捕捉0.01毫米级的形变差异。“模型训练数据来自全球10万台风机的运行日志,每新增1小时数据,预测准确率就提升0.02%。”金风科技首席数字官李明在2026年北京国际风能大会上介绍,2026年一季度,该平台成功预警了内蒙古某风电场的一起叶片断裂事故,避免直接经济损失超2000万元。
汽车制造:虚拟调试的“零物理原型”
特斯拉上海超级工厂的“数字孪生产线”代表了汽车行业的极致实践,通过将深度学习与数字孪生结合,特斯拉实现了新车型从设计到量产的全流程虚拟化,传统车企需要建造物理样车进行碰撞测试,而特斯拉的生成对抗网络(GAN)模型可基于CAD数据直接生成高精度碰撞模拟结果。“我们的Model Y改款项目,通过数字孪生虚拟调试将开发周期从18个月压缩至9个月,节省了4.2亿美元的研发成本。”特斯拉全球生产副总裁安德鲁·布朗在2026年股东大会上透露,更关键的是,虚拟调试过程中积累的200万组测试数据,又被用于优化下一代车型的轻量化设计算法。
2026年环保公益与公益活动及绿色标签发展迅速,技术创新带来新突破 
航空航天:复杂系统的“全局最优解”
中国商飞C929客机的研发中,数字孪生平台与深度学习协同解决了气动设计与结构强度的矛盾,传统方法需在气动性能与重量之间妥协,而商飞团队构建的“多学科优化数字孪生体”通过强化学习算法,在10万次虚拟风洞试验中找到了最优解。“深度学习模型学会了像人类工程师一样‘权衡取舍’,但速度是人类的1000倍。”C929总设计师姜丽萍在2026年珠海航展上表示,C929的机翼设计比波音787更轻,同时燃油效率提升12%。
技术突破:支撑数据闭环的三大深度学习创新
2026年数字孪生平台的爆发式落地,离不开深度学习领域的三项关键突破:
小样本学习:破解工业数据“长尾问题”
本月土壤修复与新闻媒体热度持续上升,相关产业迎来新机遇 工业场景中,故障数据往往稀缺且分布不均,英伟达在2026年GTC大会上发布的MetaFormer架构,通过自监督学习从正常数据中提取特征,仅需5个故障样本即可完成模型微调,这一技术被应用于三一重工的挖掘机液压系统故障诊断,使新机型上市后的故障识别准确率从68%提升至91%。

边缘-云端协同:满足实时性与算力平衡
工业现场对延迟敏感(如机器人控制需<10ms),而深度学习模型训练需要强大算力,华为2026年推出的昇腾AI芯片与MindSpore框架,实现了模型在边缘设备的轻量化部署与云端持续优化,在比亚迪的电池生产线,边缘设备运行轻量级YOLOv8模型进行缺陷检测,同时将疑难样本上传至云端训练更复杂的Transformer模型,形成“边缘快速响应+云端持续进化”的闭环。
可解释性AI:打破工业应用的“黑箱困境”
本月游戏产业与营养膳食热度持续攀升,相关技术取得新突破 深度学习模型的可解释性曾是工业界拒绝采用的主因,2026年,IBM的AI Explainability 360工具包与施耐德电气的EcoStruxure平台深度集成,可自动生成模型决策的因果图,在巴斯夫的化工生产中,这一技术帮助工程师理解了深度学习模型为何建议将反应温度从85℃调整至83℃——原来模型发现了温度与副产物生成的非线性关系,而这一规律从未被人类专家记录。
挑战与未来:数据闭环的“最后一公里”
尽管数据闭环的规律已得到验证,但2026年的实践也暴露了三大挑战:
- 数据质量参差不齐:某汽车零部件厂商的数字孪生项目因传感器校准失误,导致模型学习了错误的数据分布,最终产生灾难性决策。
- 跨系统集成困难:某钢铁企业的数字孪生平台需对接ERP、MES、SCADA等8套异构系统,数据格式转换耗时占项目周期的40%。
- 人才缺口:麦肯锡2026年调查显示,83%的制造企业缺乏既懂工业知识又懂深度学习的复合型人才。
面对这些挑战,行业正在探索解决方案:西门子推出的“工业元宇宙”平台通过数字主线(Digital Thread)技术实现数据自动对齐;AWS与德国弗劳恩霍夫研究所合作开发了低代码数字孪生工具包,将模型开发周期从6个月缩短至2周;而中国“东数西算”工程的建设,则为工业大数据提供了低成本、高可靠的算力基础设施。
当数字孪生遇见深度学习,工业的未来正在被重写
2026年的工业现场,数字孪生已不再是展示厅里的概念模型,而是深入到研发、生产、运维的每一个环节,从金风科技的风机叶片检测到特斯拉的虚拟产线调试,从C929的气动优化到巴斯夫的化工反应控制,数据驱动的闭环优化规律正在持续释放价值,正如《经济学人》在2026年5月刊中所言:“当深度学习为数字孪生注入‘大脑’,工业就获得了预测未来、自我进化的超能力。”这场变革的终点,或许是一个无需人类干预的“自感知、自决策、自优化”的工业新世界。