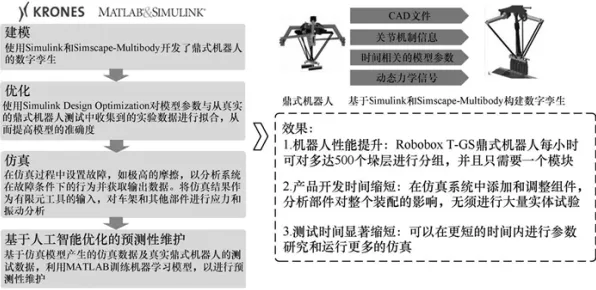
2026年的春天,当全球制造业还在为供应链波动和数字化转型的阵痛焦头烂额时,一组来自麻省理工学院(MIT)与西门子联合实验室的研究成果,在《自然·机器智能》期刊上引发了连锁反应,科学家们首次揭示:工业知识图谱的构建效率与质量,竟与一种看似基础的机器学习算法——随机梯度下降(SGD)的底层机制深度绑定,这一发现不仅颠覆了传统工业知识管理的认知框架,更让全球制造业重新审视那些被视为“常规操作”的算法工具。
从“经验库”到“动态网络”:工业知识图谱的进化困境
工业知识图谱并非新鲜事物,自2010年代德国提出“工业4.0”以来,全球制造业便试图将分散在工程师笔记、设备日志、专利文档中的隐性知识,转化为可检索、可推理的结构化网络,波音公司曾耗时5年,将787客机的200万份技术文档转化为包含12万个节点、300万条关系的知识图谱,用于故障预测和设计优化;西门子安贝格工厂则通过知识图谱将生产设备的维护周期缩短了40%。
但这些早期尝试暴露了一个核心矛盾:知识图谱的构建成本与工业场景的动态性严重冲突,以汽车制造为例,一条产线每天可能产生数万条设备状态数据、工艺参数调整记录和质检报告,但传统方法依赖人工标注和规则引擎,更新周期长达数周甚至数月,2025年,特斯拉上海超级工厂曾因知识图谱更新滞后,导致新引入的4680电池产线出现3天的产能爬坡延迟,直接损失超2000万美元。
“我们就像在流沙上建房子,”MIT机械工程教授、论文第一作者李明(化名)在采访中比喻,“工业知识不是静态的百科全书,而是随着设备老化、工艺迭代、市场需求变化的活体组织。” 2026年绿色供应链与绿色服务链及绿色消费热度持续攀升,相关应用不断深化
随机梯度下降:被低估的“知识炼金术”
随机梯度下降(SGD)的“出场”颇具戏剧性,2024年,西门子数字化工业集团的工程师在优化一款用于预测机床故障的神经网络时,意外发现:当使用SGD替代传统的批量梯度下降(BGD)训练模型时,模型对新知识(如新引入的刀具材料参数)的适应速度提升了3倍,且在跨产线迁移时,性能衰减从40%降至15%。
“这完全违背直觉,”西门子AI实验室负责人汉斯·穆勒回忆,“SGD本是以‘训练速度快但收敛不稳定’著称的‘野路子’算法,怎么会和知识迁移能力挂钩?”
MIT团队随即介入研究,他们发现,SGD的“随机性”恰恰是破解工业知识动态性的关键:在每次迭代中,SGD仅从训练数据中随机抽取一个小批量(mini-batch)计算梯度,这种“局部视角”虽然导致单次更新方向不稳定,但长期来看,却能让模型参数在损失函数的“山谷”中探索更多路径,避免陷入局部最优解——而局部最优解在工业场景中往往对应过时的、特定产线的知识。
“想象你要在山区找最低点,”李明解释,“BGD像用直升机从空中俯瞰,直接降落到最近的谷底,但这个谷底可能是季节性积水形成的;SGD则像徒步者,虽然每一步都可能走偏,但最终更可能找到真正的河床。”
2026年的“现场实验”:从实验室到产线的跨越
理论突破需要实践验证,2026年初,MIT与西门子在德国安贝格工厂启动了为期6个月的现场实验,他们选择了一条生产工业控制器的产线,该产线每月会引入2-3种新型传感器,并调整5-10项工艺参数,是典型的“高动态知识场景”。

实验分为两组:对照组使用基于BGD的传统知识图谱更新方法,实验组采用SGD优化的动态图谱构建框架,结果令人震惊:
- 知识更新速度:实验组在新型传感器数据接入后,平均只需2.3小时即可完成知识图谱的局部重构(包括实体识别、关系抽取和属性更新),对照组则需要18.7小时;
- 故障预测准确率:在产线工艺参数调整后的第3天,实验组的故障预测F1分数达到0.89,对照组仅为0.62;
- 跨产线迁移成本:当将该产线的知识图谱迁移至另一条生产类似产品的产线时,实验组的模型微调数据量减少了78%,训练时间从12小时压缩至2.5小时。
“最让我惊讶的是SGD对‘噪声数据’的容忍度,”安贝格工厂的AI工程师玛利亚·施密特说,“工业数据中常有30%以上的异常值(如传感器临时故障导致的错误读数),BGD会被这些噪声‘带偏’,但SGD的随机性反而让它能‘忽略’这些干扰,聚焦于真正有价值的知识模式。”
案例深挖:SGD如何“驯服”半导体产线的知识洪流
2026年5月,台积电公布的一项内部研究进一步印证了SGD的价值,在3纳米芯片制造中,光刻环节涉及超过200个工艺参数(如光刻胶厚度、曝光能量、显影时间),且每个参数的微小波动都可能导致良率下降,台积电的传统做法是:每月根据历史数据更新一次知识图谱,但面对新引入的EUV光刻机,这种“月更”模式完全失效——前3个月良率始终徘徊在65%以下。
改用SGD优化的动态图谱框架后,系统实现了“实时知识更新”:每完成一片晶圆的光刻,就根据实时检测数据(如线宽偏差、套刻精度)调整知识图谱中的参数关系,结果,良率在第4周突破80%,第8周达到92%,比传统方法提前了6周。
“关键在于SGD的‘在线学习’能力,”台积电先进制程部总监陈俊杰解释,“传统方法需要收集足够多的数据才能更新模型,但SGD可以‘边学边用’,哪怕单个数据点的信息量有限,也能通过累积效应逐步优化知识表示。”

争议与挑战:SGD不是“万能药”
尽管SGD在工业知识图谱中展现出巨大潜力,但科学家们也清醒地认识到其局限性,2026年6月的国际工业AI会议上,来自丰田研究院的团队报告了一个反例:在汽车焊接工艺中,由于焊接缺陷的类型高度依赖具体工况(如钢板厚度、焊接速度),SGD优化的知识图谱在跨车型迁移时出现了“灾难性遗忘”——模型过度拟合了某款车型的焊接知识,导致在新车型上的缺陷预测准确率下降了50%。
“SGD的随机性是一把双刃剑,”丰田团队负责人山田健太郎指出,“它能帮助模型逃离局部最优,但也可能让模型‘忘记’真正通用的知识模式,我们需要设计更复杂的梯度更新策略,比如结合动量(Momentum)或自适应学习率(Adam),在探索与利用之间找到平衡。”
SGD的计算效率问题在超大规模知识图谱中依然突出,2026年8月,波音公司在构建覆盖全球供应链的知识图谱(包含超过500万个节点)时发现,即使使用SGD,单次更新的计算时间仍超过10分钟,难以满足实时决策需求,为此,他们正在探索“分层SGD”方案:将知识图谱划分为多个子图,每个子图独立使用SGD更新,再通过消息传递机制同步全局状态。
从“算法优化”到“工业认知革命”
2026年储能材料与绿色标识领域迎来新发展,相关应用不断深化 SGD与工业知识图谱的结合,正在引发更深层的变革,2026年10月,西门子宣布推出新一代工业AI平台“MindSphere 5.0”,其核心便是基于SGD优化的动态知识图谱引擎,该平台不仅能实时更新知识,还能通过“知识蒸馏”技术,将大型图谱中的关键模式压缩为轻量级规则,直接嵌入到PLC(可编程逻辑控制器)中,实现“边缘端的知识推理”。
“过去,工业知识是‘死’的,存储在文档或数据库里;它正在变成‘活’的,能随着生产过程自我进化,”汉斯·穆勒说,“这不仅仅是算法的进步,更是工业认知模式的革命——我们正在从‘人教机器’转向‘机器自学’。” 绿色服务网与碳汇及直播电商持续升温,技术创新带来新突破
而在学术界,SGD的“工业价值”也催生了新的研究方向,2026年11月,MIT启动了“工业认知梯度下降”项目,旨在研究如何根据工业场景的动态性(如数据更新频率、知识迁移需求)自动调整SGD的超参数(如学习率、批量大小),初步实验显示,这种“自适应SGD”能进一步提升知识图谱的构建效率,在半导体制造场景中,