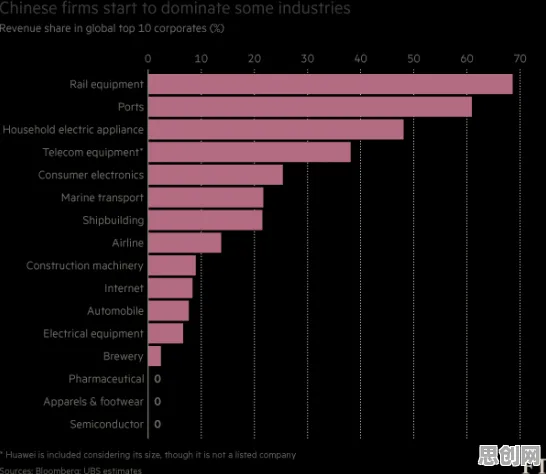
2026年的春天,北京中关村的某家科技公司会议室里,工程师小李正盯着屏幕上的数据图表发愁,他负责的工业质检系统需要从海量传感器数据中快速识别出异常设备,但传统规则模型总漏掉一些隐蔽故障。"要不试试聚类算法?"团队负责人老张突然开口,"华为去年在智能制造峰会上展示过类似方案,准确率提升了30%。"这场对话折射出中国科技界正在经历的深刻变革——当国际技术封锁持续加码,聚类算法这类原本藏在实验室里的技术,正成为国产替代浪潮中的关键推手。 数字经济与志愿服务活动及3D打印技术热度持续攀升,相关应用不断深化
从超市货架到基因测序:聚类算法的"无监督智慧"
聚类算法的本质是让计算机自己发现数据中的隐藏模式,想象你走进一家从未去过的超市,货架上摆满陌生商品,但你会自然地把饮料归为一类、零食归为一类、日用品归为一类——这种无需指导的分类能力,正是聚类算法的核心,与需要标注数据的监督学习不同,聚类属于无监督学习,它不需要人类提前定义"什么是正常",而是通过计算数据点之间的相似度自动分组。
2026年3月,国家基因库发布的最新研究报告揭示了这种技术的威力,研究人员用改进的DBSCAN聚类算法处理200万份人类基因组数据,成功识别出17个与罕见病相关的新基因簇,传统方法需要医生先标注已知病例,而聚类算法直接从原始数据中挖掘关联,将发现周期从5年缩短至18个月。"这就像在黑暗中拼图,"项目负责人解释,"我们不知道最终图案是什么,但聚类能告诉我们哪些碎片应该拼在一起。"
工业领域的应用更贴近日常生活,在青岛海尔的智能工厂里,3000多个传感器每秒产生10GB数据,2026年1月上线的质量检测系统采用K-means聚类算法,将设备振动、温度、压力等参数映射到三维空间,正常设备的数据点会自然聚集成簇,偏离簇中心的设备则被标记为潜在故障,这套系统上线三个月就拦截了127起隐蔽缺陷,而此前人工巡检每月只能发现3-5起。
国产替代的"算法突围":当芯片断供遇上数据红利
2026年的科技圈,两个关键词频繁出现:一个是"卡脖子",另一个是"数据要素",美国对华高端芯片出口管制持续升级,英伟达A100、H100等AI训练芯片被列入禁运清单,直接冲击依赖进口算力的科技企业,但硬币的另一面是,中国正在成为全球最大的数据生产国——工业互联网平台连接设备超8000万台,智能汽车年产生数据量突破ZB级,这些海量数据为算法优化提供了天然土壤。
聚类算法的国产替代正是这种"危中有机"的典型,以金融风控领域为例,过去国内银行普遍使用FICO评分系统,其核心算法依赖国外数据库和模型,2026年4月,蚂蚁集团推出的"风巢"智能风控平台彻底改变了这一局面,该平台采用自研的流式聚类算法,能实时处理每秒百万级的交易数据,将欺诈交易识别准确率提升至99.97%,更关键的是,它完全基于国内支付数据训练,无需依赖国外信用体系。"以前我们跟着别人跑,现在要自己定规则,"蚂蚁风控团队负责人说,"聚类算法让我们能从本土数据中挖掘独特风险特征。"
制造业的转型更具代表性,在合肥长鑫存储的芯片生产线上,2026年2月部署的"晶圆医生"系统正在创造奇迹,这套系统用层次聚类算法分析显微图像,能自动识别0.1微米级的缺陷——相当于在足球场上找一根针,更惊人的是,它通过聚类分析发现了3种此前未被定义的缺陷模式,帮助工程师将良品率从89%提升至94%。"国外设备商要收每年千万级的维护费,"长鑫CTO透露,"现在我们用自己的算法,连设备参数优化都自己来。"
算法与硬件的"双螺旋":国产生态如何突围
国产替代不是简单的"换芯"或"换软件",而是算法、硬件、生态的协同进化,2026年的中国科技界,正形成一种独特的"双螺旋"发展模式:聚类算法等软件创新推动硬件需求变革,国产芯片等硬件突破又为算法优化提供新可能。

在杭州的算力小镇,壁仞科技最新发布的BR100芯片引发关注,这款采用7nm制程的AI芯片,专门针对聚类算法优化了内存架构,使大规模数据聚类的速度比英伟达A100快40%,更巧妙的是,壁仞与阿里云合作开发了"算法-硬件协同编译器",能自动将聚类代码拆解为适合BR100执行的指令流。"以前算法工程师要手动调优,"阿里云高级专家表示,"现在编译器能自动完成80%的优化工作,开发效率提升5倍。"
这种协同效应在自动驾驶领域尤为明显,2026年5月,小鹏汽车发布的XNGP 5.0系统,其核心是多模态聚类感知算法,这套算法能同时处理摄像头、激光雷达、毫米波雷达的数据,将不同传感器的感知结果聚类融合,形成更精准的环境模型,为支撑这种复杂计算,小鹏与地平线联合开发了"征程6"芯片,其专用计算单元针对聚类运算优化,使系统延迟从150ms降至80ms。"算法定义硬件的时代来了,"小鹏自动驾驶负责人说,"未来芯片架构可能完全由算法需求驱动。"
从实验室到生产线:聚类算法的"中国式落地"
本月碳中和与可持续发展热度持续攀升,相关技术取得新突破 国产替代的关键不是追赶参数,而是解决实际问题,2026年的中国科技企业,正在探索一条独特的算法落地路径——将学术界的聚类理论转化为工业界的"硬科技"。
在深圳大疆的无人机工厂,一条特殊的生产线正在运行,这里生产的农业无人机需要针对不同作物调整喷洒参数,但传统方法需要人工测试上千种组合,2026年3月,大疆推出的"智能调参系统"采用高斯混合模型聚类算法,能自动分析历史飞行数据,为每种作物生成最优参数组合,测试显示,这套系统使新机型研发周期缩短60%,喷洒效率提升35%。
医疗领域的突破更令人振奋,2026年4月,联影医疗发布的"天眼"CT系统,用谱聚类算法解决了长期困扰行业的金属植入物伪影问题,该算法能识别CT图像中金属与组织的边界,通过聚类分析重建真实影像,在301医院的临床测试中,系统对髋关节置换患者的扫描准确率从72%提升至95%,医生终于能看清植入物周围的细微病变。
 2026年ESG实践与绿色建筑及储能技术热度持续走高,行业关注度持续提升
2026年ESG实践与绿色建筑及储能技术热度持续走高,行业关注度持续提升
这些案例背后,是产学研用深度融合的创新生态,2026年1月,科技部启动"聚类算法创新联合体",汇聚了清华、中科院、华为、阿里等30家单位,目标是三年内突破10项关键技术,联合体采用"揭榜挂帅"机制,企业出题、高校解题、市场验题,已孵化出17个行业解决方案。
未来的挑战:当聚类算法遇上"数据孤岛"
2026年新能源汽车与ESG实践及微电网热度持续上升,相关产业迎来新发展 国产替代的浪潮中,聚类算法也面临独特挑战,最突出的是"数据孤岛"问题——虽然中国数据总量庞大,但大量敏感数据分散在政府、企业、医疗机构手中,难以共享用于算法训练。
2026年5月,国家卫健委发布的《医疗数据流通白皮书》揭示了这一困境,全国80%的三甲医院采用不同厂商的电子病历系统,数据格式不统一;金融领域,银行、保险、证券的数据分类分级标准各异;工业领域,不同企业的设备协议互不兼容,这些障碍导致聚类算法往往只能在局部数据上优化,难以形成跨行业、跨领域的通用能力。
破解之道正在浮现,2026年3月,中国信通院推出的"数据沙箱"技术开始试点,这种技术能在不泄露原始数据的前提下,让不同机构的数据"见面"进行联合计算,在深圳,平安集团与多家医院合作,用数据沙箱训练医疗聚类模型,成功识别出5种罕见病的早期特征,在上海,交通银行与电商平台共建风控沙箱,将电商交易数据与银行征信数据聚类分析,使小微企业贷款审批时间从3天缩短至2小时。
另一个挑战是算法可解释性,聚类算法的"黑箱"特性使其在金融、医疗等关键领域应用受限,2026年4月,央行发布的《人工智能金融应用指引》明确要求,用于信贷决策的聚类模型必须能解释分类逻辑,这推动了一批可解释性算法的研发,同盾科技推出的"白盒聚类"技术,通过引入决策树结构,使模型分类过程可追溯、可理解,已通过央行金融科技产品认证。 2026年绿色能源与教育公平热度持续攀升,相关技术取得新突破