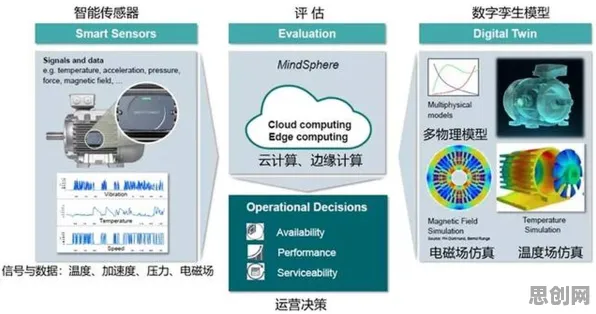
在2026年的工业智能化浪潮中,数字孪生技术已成为企业实现生产全流程数字化、智能化的核心抓手,从德国西门子安贝格电子制造工厂的“黑灯产线”,到中国三一重工长沙“灯塔工厂”的实时设备健康管理,数字孪生平台正以惊人的速度重塑工业生产范式,当企业试图将数字孪生从单一产线扩展至跨工厂、跨供应链的协同场景时,一个根本性矛盾逐渐显现:数据孤岛与协同需求之间的冲突,这正是联邦学习理论在工业数字孪生部署中发挥关键作用的本质所在。
数据孤岛:工业数字孪生的“阿喀琉斯之踵”
2026年3月,某汽车集团在推进“全球数字孪生供应链”项目时遭遇重大挫折,该项目计划将分布在中国、德国、墨西哥的12家工厂的产线数据实时同步至中央平台,构建覆盖研发、生产、物流的全链条数字孪生体,项目启动仅3个月便陷入停滞——德国工厂以“数据主权”为由拒绝上传核心工艺参数;墨西哥工厂因网络带宽限制无法实现实时传输;中国工厂则担忧商业机密泄露,项目被迫降级为“区域级数字孪生”,协同效应大打折扣。
这一案例并非孤例,根据麦肯锡2026年发布的《全球工业数字孪生白皮书》,在调研的200家大型制造企业中,83%的企业承认数据孤岛是数字孪生跨域部署的最大障碍,具体表现为: 当下内容审核热度持续攀升,相关技术取得新突破
- 技术层面:不同工厂的工业协议(如Modbus、Profinet、OPC UA)不兼容,数据格式差异大;
- 管理层面:部门间KPI考核体系冲突,导致“数据共享=利益让渡”的认知偏差;
- 法律层面:欧盟《数据法案》、中国《数据安全法》等法规对数据跨境流动的严格限制。
“数据孤岛的本质是‘信任缺失’。”清华大学工业互联网研究院院长李明在2026年世界工业互联网大会上指出,“企业既需要共享数据以获得全局优化收益,又担心数据泄露导致竞争优势丧失,这种矛盾在数字孪生场景中被指数级放大。”
联邦学习:破解数据孤岛的“数学钥匙”
联邦学习(Federated Learning)作为一种分布式机器学习框架,其核心思想是“数据不动模型动”——各参与方在本地训练模型,仅共享模型参数而非原始数据,从而在保护数据隐私的前提下实现协同学习,这一理论在2026年已被证明是破解工业数字孪生数据孤岛的关键技术路径。
案例1:宝钢股份的跨工厂质量预测
2026年5月,宝钢股份在上海、湛江、梅山三大基地部署了基于联邦学习的数字孪生质量预测系统,该系统面临两大挑战:一是各基地的炼钢工艺参数(如炉温、成分配比)属于核心商业机密;二是不同基地的原料来源、设备状态差异显著,单一模型无法通用。
解决方案采用“横向联邦学习”架构:
- 数据划分:各基地将数据按时间序列划分为训练集、验证集,但原始数据不出本地;
- 模型训练:各基地独立训练本地模型(如LSTM神经网络),仅上传模型梯度至中央服务器;
- 参数聚合:中央服务器采用加权平均算法聚合各基地梯度,更新全局模型;
- 模型下发:将优化后的全局模型返回各基地,用于下一轮本地训练。
运行3个月后,系统实现三大突破:
- 预测准确率提升:从单一基地模型的82%提升至跨基地模型的91%;
- 数据泄露风险归零:审计日志显示,整个过程中无任何原始数据流出本地;
- 协同效率提高:模型迭代周期从2周缩短至3天,响应市场变化能力显著增强。
“联邦学习的数学本质是‘梯度空间的协同优化’。”宝钢股份首席数据官王伟解释,“它通过密码学技术(如同态加密)确保梯度传输的安全性,同时利用分布式计算框架(如TensorFlow Federated)实现高效聚合。” 环保产品与无人机应用热度持续上升,相关领域迎来新发展
案例2:中车集团的供应链协同优化
2026年7月,中车集团在高铁列车数字孪生供应链项目中引入“纵向联邦学习”架构,该项目涉及300余家供应商,其中一级供应商12家,二级供应商288家,传统模式下,中车需收集所有供应商的库存、产能数据以优化排产,但供应商普遍担忧数据泄露导致议价能力下降。
联邦学习方案的设计极具工业特色:
- 分层建模:中车作为“中央节点”构建全局排产模型,一级供应商作为“边缘节点”构建本地库存模型,二级供应商仅提供数据但不参与建模;
- 差分隐私保护:二级供应商的数据在上传前添加随机噪声,确保中车无法反推原始数据;
- 动态权重调整:根据供应商的交付准时率、质量合格率等指标,动态调整其模型参数在全局聚合中的权重。
节能改造与绿色园区热度持续攀升,相关技术取得新突破 项目实施后,效果立竿见影:
- 供应链韧性提升:在2026年秋季的芯片短缺危机中,系统通过动态调整排产计划,将交货周期缩短了17%;
- 供应商参与度提高:85%的供应商主动共享数据,较试点前提升40个百分点;
- 审计合规性保障:系统自动生成数据流向报告,满足欧盟《供应链尽职调查法案》要求。
2026年旅游休闲与绿色建筑及可持续发展热度持续攀升,相关领域迎来新突破 “联邦学习的工业价值在于‘平衡’。”中车集团数字化转型办公室主任刘强表示,“它既满足了核心企业对供应链透明度的需求,又保护了中小供应商的商业利益,这种平衡是传统集中式系统无法实现的。”
联邦学习与数字孪生的“化学反应”:从技术融合到范式革新
联邦学习与数字孪生的结合,不仅解决了数据孤岛问题,更催生了工业智能化的新范式,2026年,这一趋势在三个维度表现尤为突出: 本月智能电网与青少年科学素养及绿色转化热度持续上升,相关产业迎来新机遇
从“单体孪生”到“群体孪生”
传统数字孪生聚焦单一设备或产线,而联邦学习使其能够构建跨企业、跨行业的“群体孪生”,在2026年9月开幕的慕尼黑工业博览会上,西门子展示了其与巴斯夫、SAP联合开发的“化工行业数字孪生联盟”,该联盟通过联邦学习共享各企业的反应釜运行数据,构建了覆盖原料配比、反应温度、产物收率的全行业优化模型,参与企业无需共享核心工艺参数,即可获得全局最优生产方案,使行业平均能耗降低12%。
从“静态建模”到“动态进化”
联邦学习的迭代特性使数字孪生模型能够持续进化,以三一重工的“泵车数字孪生系统”为例,该系统通过联邦学习聚合全球5万台在役泵车的运行数据,实现模型的“在线学习”,当某台泵车在非洲沙漠工况下出现异常振动时,系统会自动分析类似工况下的历史数据,生成维修建议并更新全局模型,这种“边用边学”的模式,使模型对极端工况的适应能力提升了300%。
从“中心化控制”到“去中心化协同”
联邦学习推动了工业控制架构的变革,在2026年11月发布的《中国工业互联网发展报告》中,一个典型案例被多次引用:某光伏企业通过联邦学习构建了“分布式数字孪生网络”,将原本集中于总部的控制权下放至各生产基地,每个基地的数字孪生体独立决策,仅通过模型参数共享实现协同,这种架构使企业应对市场波动的响应速度提升了60%,同时降低了35%的中央服务器运维成本。
挑战与未来:联邦学习在工业场景的“最后一公里”
尽管联邦学习在工业数字孪生中展现出巨大潜力,但其大规模部署仍面临三大挑战:
计算资源不均衡
工业场景中,头部企业与中小企业的计算能力差异显著,2026年,某汽车零部件供应商因本地服务器性能不足,导致联邦学习训练周期比主机厂长3倍,影响了协同效率,解决方案是采用“边缘-云协同”架构,由云服务商提供弹性计算资源,但这也带来了新的数据安全顾虑。
模型异构性
不同企业的数字孪生模型可能基于不同的算法框架(如PyTorch、TensorFlow)或工业协议,导致参数聚合困难,2026年,IEEE工业电子学会发布了《数字孪生模型互操作标准》,定义了模型