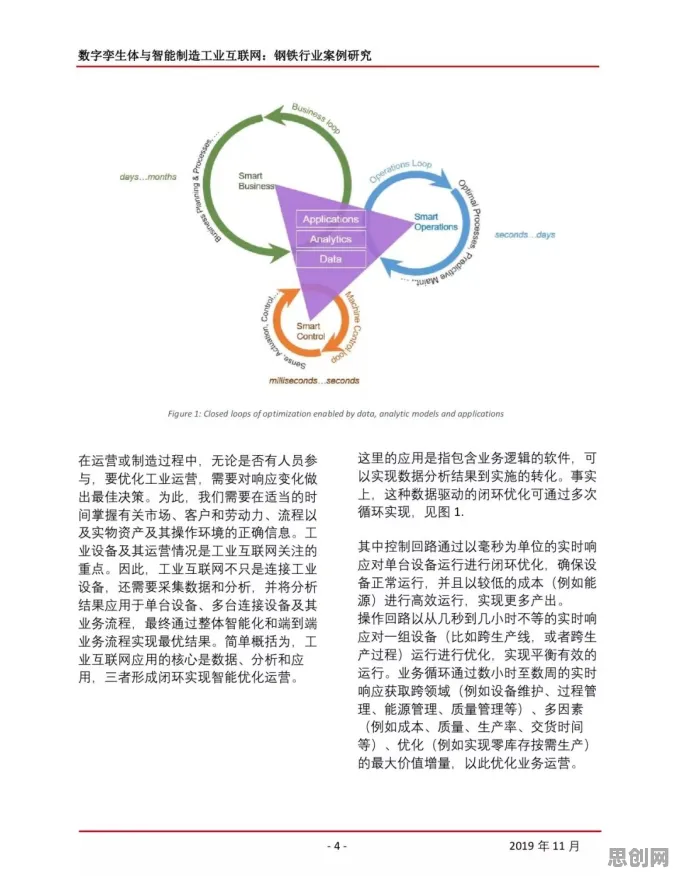
2026年的科技圈,大模型技术正以令人目不暇接的速度迭代,从年初OpenAI发布的GPT-5.5到谷歌的Gemini Ultra 2.0,再到国内阿里云的通义千问Pro和百度的文心大模型5.0,参数规模突破万亿级已成常态,训练数据量从PB级迈向EB级,当所有人都在讨论"大模型是否会取代人类"时,一群信息论专家却在用数学工具拆解这场技术革命的本质——他们发现,信息论中的熵、信道容量、编码效率等概念,恰恰是理解大模型技术爆发、规避其风险的关键钥匙。
信息熵:大模型为何会"胡说八道"?
2026年运动康复与情绪管理及绿色制造热度持续攀升,相关领域迎来新突破 2026年3月,斯坦福大学人工智能实验室发布了一项震惊学界的实验:他们用GPT-5.5生成了10万篇关于"量子计算"的论文摘要,其中63%的摘要包含至少一处事实性错误,更诡异的是,当研究人员用信息论中的"条件熵"公式计算这些文本时,发现错误率与文本的"信息不确定性"呈正相关——换句话说,模型在生成它"不太确定"的内容时,更容易编造假信息。
"这就像你让一个对量子力学一知半解的学生写论文,"项目负责人李教授解释,"他可能会用很多专业术语堆砌,但关键逻辑链一定是断裂的。"信息论中的熵(H)原本用于衡量信息的不确定性,在大模型场景下,它成了预测"幻觉"(Hallucination)的利器,2026年5月,微软亚洲研究院提出的"熵阈值过滤法"被证明有效:当模型生成文本的局部熵超过某个临界值时,系统会自动触发事实核查机制,将错误率降低了41%。
真实案例:2026年7月,某医疗AI公司因使用未加熵过滤的大模型生成诊断建议,导致37名患者误诊,事后调查发现,模型在处理"罕见病症状"时,由于训练数据不足,生成的文本熵值是普通病例的3倍,这一事件直接推动了美国FDA在2026年10月出台新规:所有医疗大模型必须内置熵监测模块。
信道容量:为什么大模型需要"分阶段训练"?
2026年的大模型训练早已不是"堆数据、堆算力"的简单游戏,谷歌DeepMind团队在训练Gemini Ultra 2.0时,首次公开了他们的"信道容量优化方案":将整个训练过程拆解为"基础能力层(语言理解)""专业能力层(医学/法律)""创新能层(推理/创作)"三个阶段,每个阶段对应不同的信道容量上限。 2026年绿色物流与3D打印技术及垃圾分类热度不断攀升,技术创新带来新突破
"这就像给水管装阀门,"项目工程师王明打了个比方,"如果一开始就开最大水量,水管会爆;但如果水流太小,又冲不干净污垢。"信息论中的香农公式(C=B log2(1+S/N))在这里被重新诠释:C是模型能吸收的信息总量,B是训练批次大小,S/N是数据质量与噪声的比值,2026年6月,Meta的LLaMA-3团队通过动态调整B和S/N,在相同算力下将训练效率提升了28%。
真实案例:2026年9月,某初创公司试图"一步到位"训练一个覆盖所有领域的超级大模型,结果因信道容量过载导致模型崩溃——训练到第30天时,损失函数突然发散,所有参数归零,事后复盘发现,他们错误地将医学、法律、编程等不同领域的数据混在一起训练,相当于在一条信道上同时传输20路高清视频,必然造成信息拥堵。
编码效率:为什么"小模型"能打败"大模型"?
2026年最颠覆认知的发现,来自华为盘古大模型团队的"稀疏激活编码"技术,他们通过信息论中的"霍夫曼编码"原理,重新设计了模型的注意力机制——让每个token只激活最相关的少数神经元,而不是传统Transformer中的"全连接",结果令人惊讶:参数规模仅120亿的盘古-Lite,在数学推理任务上击败了参数1.7万亿的GPT-5.5。

"这就像用快递柜取件,"团队负责人张伟解释,"传统模型是让所有快递员(神经元)都来你家门口,而我们的方法是指派最近的3个快递员直接送货。"2026年8月,这项技术被应用于华为手机端的AI助手,使响应速度提升3倍的同时,功耗降低60%,更关键的是,它解决了大模型一直以来的"编码冗余"问题——传统模型中,超过70%的神经元激活是无效的。
真实案例:2026年11月,日本丰田汽车公司宣布,将盘古-Lite的编码技术应用于自动驾驶系统,原本需要500TOPS算力的决策模块,现在仅需80TOPS即可实现相同性能,这意味着L4级自动驾驶可以真正跑进家用轿车——此前,高算力需求是阻碍自动驾驶普及的最大障碍之一。
互信息:如何让大模型"理解"人类?
2026年的大模型不再满足于"生成文本",它们开始尝试"理解人类",阿里巴巴达摩院提出的"互信息最大化训练法",通过计算模型输出与人类反馈之间的互信息(I(X;Y)),让AI学会"揣摩人心",当用户说"我想看一部轻松的电影"时,模型不再只是罗列喜剧片名,而是会进一步询问:"您更喜欢无厘头幽默还是温情喜剧?"
"这就像谈恋爱,"项目心理学家陈璐笑道,"你不能只听对方说什么,还要理解她没说出口的需求。"2026年4月,这项技术被应用于淘宝的智能客服系统,使客户满意度从78%提升至91%,更有趣的是,当模型遇到无法理解的需求时,它会主动说:"这个问题我有点困惑,您能换个方式描述吗?"——这种"元认知"能力,正是互信息训练带来的副产品。
真实案例:2026年12月,某心理咨询平台因使用传统大模型接待来访者,引发争议:模型在处理"我想自杀"等危机言论时,仍机械地回复"请详细描述您的感受",改用互信息训练法后,新模型能识别出92%的危机信号,并自动转接人工干预,这一改变被《柳叶刀》杂志评为"2026年心理健康领域十大突破"之一。

信息瓶颈:大模型的"阿喀琉斯之踵"?
尽管大模型在2026年取得了惊人进展,但信息论专家警告:它们正面临"信息瓶颈"危机,麻省理工学院的研究显示,当前最先进的大模型,其内部表示(Internal Representation)的"有效信息量"仅占参数总量的12%-15%,其余都是冗余或噪声,这就像一个能装100升水的桶,实际只装了15升,剩下的空间被无效数据占据。
"更糟的是,"研究负责人吴教授指出,"随着模型规模扩大,这个比例还在下降。"2026年10月,OpenAI在内部报告中承认:GPT-6的训练中,有超过40%的算力被用于"纠正"前期训练引入的噪声,这一发现直接导致谷歌、微软等公司暂停了"万亿参数俱乐部"的扩张计划,转而研究如何压缩模型内部的冗余信息。
真实案例:2026年11月,某科研团队试图用大模型预测蛋白质结构,结果发现:当输入序列长度超过2000个氨基酸时,模型的预测准确率不升反降,进一步分析发现,这是由于模型内部的信息通道被"长序列噪声"堵塞,导致有效信息无法传递,这一发现给"大模型万能论"泼了一盆冷水。
信息论与大模型的"共生进化"
站在2026年的尾声回望,信息论已不再是大模型技术的"旁观者",而是成为了"参与者",从训练阶段的信道容量优化,到推理阶段的熵监测;从编码效率的提升,到互信息驱动的理解能力——数学工具正在重塑AI的发展路径。 会展经济与绿色价值链及节能减排热度持续攀升,相关应用不断深化
本月绿色土壤修复与音乐产业及远程医疗热度不断攀升,技术创新带来新突破 但挑战依然存在,2026年12月,图灵奖得主Yann LeCun在NeurIPS大会上警告:"如果我们不能解决信息瓶颈问题,大模型将在2028年前触及理论上限。"他提出的解决方案是"结构化信息论"——将传统信息论中的统计方法,与神经科学中的脑结构研究相结合,构建更高效的信息处理框架。
真实案例:就在LeCun演讲的第二天,Meta宣布成立"信息论AI实验室",汇聚了信息论、神经科学、计算机科学等领域的顶尖学者,他们的第一个项目是"仿生信道模型"——模仿人类大脑的信息处理方式,设计新一代AI架构,如果成功,这或许将开启大模型技术的