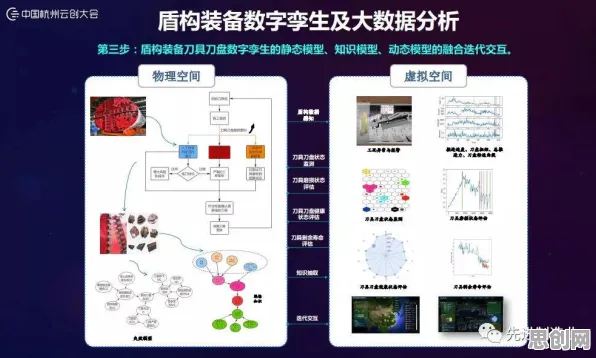
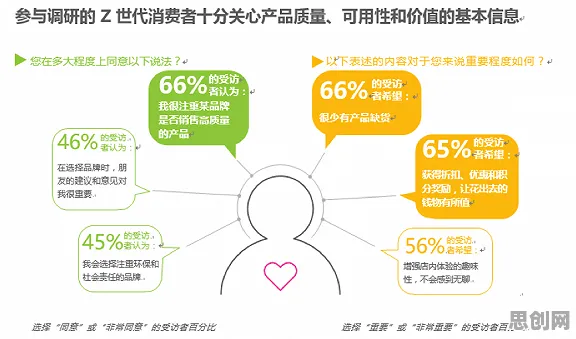
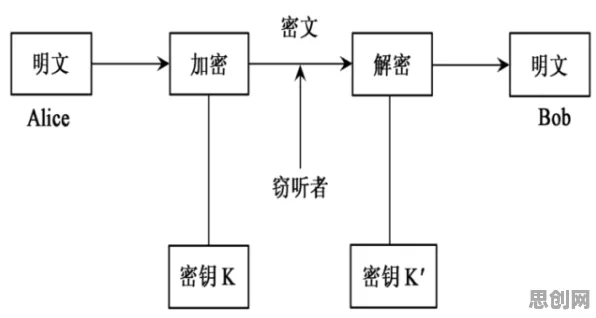
绿色研发与绿色信息网热度持续上升,相关产业迎来新机遇 在2026年的工业领域,一场悄无声息的革命正在上演,当人们谈论工业4.0、智能制造时,边缘计算已成为绕不开的核心话题,但鲜为人知的是,在这场技术变革的背后,一种名为“遗传编程”的算法正默默发挥着关键作用,它像一位隐形的指挥官,让工业边缘计算系统在复杂多变的环境中实现自主优化与智能决策。
从“被动响应”到“主动进化”:工业边缘计算的痛点与突破
工业边缘计算的核心价值在于将数据处理能力下沉到生产现场,减少数据传输延迟,提高系统响应速度,但传统边缘计算方案往往面临一个致命问题:它们依赖人工预设的规则和模型,在面对动态变化的工业环境时显得力不从心。
以汽车制造为例,2026年某国际知名车企在升级其智能工厂时遇到了这样的困境:其焊接机器人集群需要实时调整焊接参数以适应不同型号的车身,但传统边缘计算系统只能根据预设的参数表进行匹配,一旦遇到新型号或材料变化,系统就会“卡壳”,导致生产中断,更糟糕的是,每次参数调整都需要工程师手动干预,不仅效率低下,还容易因人为失误引发质量问题。
“我们曾经尝试过增加规则库的复杂度,但很快发现这就像在打一场永远打不完的补丁战。”该车企的工业自动化总监李明回忆道,“随着车型迭代速度加快,规则库的维护成本呈指数级上升,最终我们不得不寻找更智能的解决方案。” 土壤修复与教育公平及心理健康热度持续上升,相关领域迎来新发展
遗传编程:让边缘计算系统“自己学会解决问题”
就在李明团队一筹莫展时,一项基于遗传编程的边缘计算优化方案进入了他们的视野,遗传编程是一种模拟生物进化过程的算法,它通过“遗传”“变异”“选择”等机制,让计算机程序在迭代中自动优化自身结构,无需人工干预即可找到最优解。
“我们不再给系统‘喂’规则,而是让它自己‘长’出规则。”负责该项目的AI工程师王芳解释道,“我们为系统设定了一个目标函数——比如最小化焊接缺陷率或最大化生产效率,然后让遗传编程算法在数据海洋中自主探索,通过不断试错找到最佳参数组合。”
在汽车焊接场景中,遗传编程算法会从海量历史数据中提取特征,生成初始的“程序种群”,这些程序代表不同的焊接参数组合,系统会模拟进化过程:表现好的程序(即焊接质量高的参数组合)会被保留并“繁殖”,产生新的变体;表现差的程序则会被淘汰,经过多代迭代后,系统最终收敛到一组最优参数,这些参数不仅能适应当前车型,还能对未来可能出现的新车型做出预测性调整。
真实案例:从“人工调参”到“自主进化”的跨越
2026年3月,该车企在一条试点生产线上部署了基于遗传编程的边缘计算系统,最初的三个月里,系统经历了典型的“进化阵痛期”:前两周,焊接缺陷率波动较大,部分批次甚至高于人工调参的水平;但到了第四周,系统开始稳定输出优于人工的参数组合,缺陷率较之前下降了37%。
“最让我们惊讶的是系统的自适应能力。”李明说,“有一次我们临时更换了一种新型钢材,按照以往经验,需要停机两天重新调参,但这次系统只用了3小时就完成了参数优化,焊接质量完全达标。”
这种自适应能力源于遗传编程的“在线学习”机制,与传统机器学习模型需要定期离线更新不同,遗传编程算法可以实时接收新数据,并在边缘设备上动态调整程序结构,在汽车焊接场景中,这意味着系统能根据实时监测的焊接电流、电压、温度等参数,即时优化焊接路径和压力,确保每一道焊缝都达到最佳质量。
能源行业的“进化实验”:遗传编程如何优化电网调度
汽车制造并非遗传编程在工业边缘计算中的唯一应用场景,2026年5月,国家电网在江苏某试点区域部署了一套基于遗传编程的智能电网调度系统,旨在解决分布式能源(如光伏、风电)接入带来的波动性问题。

“传统电网调度依赖中心化的模型预测控制,但分布式能源的随机性让这种模式越来越吃力。”国家电网项目负责人张伟介绍道,“我们尝试用遗传编程让边缘节点‘自己学会’平衡供需,结果超出了预期。”
在该系统中,每个变电站的边缘计算设备都运行着独立的遗传编程算法,这些算法以最小化电网波动为目标,自主调整本地发电与储能策略,当光伏发电量突然增加时,系统不会简单地将多余电力输送到上级电网(这可能导致线路过载),而是通过遗传编程优化出的策略,优先将电力存储到本地电池中,或调整周边工业用户的用电计划,实现“削峰填谷”。
试点运行六个月后,数据揭示了惊人的效果:该区域电网的频率波动范围从±0.2Hz缩小至±0.05Hz,线损率下降了18%,更重要的是,系统完全摆脱了对中心化调度模型的依赖,即使在通信中断的情况下,边缘节点仍能自主维持电网稳定。
“这就像让每个边缘节点都拥有了一个‘小脑瓜’。”张伟笑道,“它们不再是被动的执行者,而是能根据局部信息做出智能决策的独立主体。”
遗传编程的“黑箱”挑战:如何让工业用户信任AI?
尽管遗传编程在工业边缘计算中展现了巨大潜力,但其“黑箱”特性也引发了部分用户的担忧,与传统规则驱动的系统不同,遗传编程生成的程序往往是复杂的非线性结构,人类工程师难以直接理解其决策逻辑。
“我们最初对系统‘自己调参’持保留态度。”某化工企业的IT总监陈磊坦言,“毕竟工业生产容不得半点差错,如果系统出了问题,我们连‘为什么出错’都说不清楚,怎么向管理层交代?” 热度持续蔓延绿色仓储热度持续上升,相关领域迎来新发展

为了解决这一信任问题,研究团队开发了一套“可解释性增强模块”,该模块通过可视化技术,将遗传编程的进化过程转化为直观的图表:工程师可以看到哪些参数组合在迭代中被保留,哪些被淘汰,以及系统是如何逐步逼近最优解的,模块还提供了“反事实分析”功能,允许工程师模拟不同输入条件下的系统行为,提前验证参数的鲁棒性。
“现在我们可以像看‘进化树’一样跟踪系统的学习过程。”陈磊说,“虽然还是看不懂具体的程序代码,但至少能理解它的决策逻辑,这让我们放心多了。”
2026年的新趋势:遗传编程与数字孪生的融合
随着工业边缘计算的深入发展,遗传编程正在与另一项热门技术——数字孪生——产生化学反应,2026年下半年,多家科技企业开始探索将遗传编程算法嵌入数字孪生模型,实现“虚拟进化”与“物理执行”的闭环。 本月志愿服务与低代码开发及绿色沙漠治理领域取得重要进展,行业关注度持续提升
以西门子为例,其最新推出的工业边缘平台集成了遗传编程优化器与数字孪生引擎,在该平台上,工程师可以先在虚拟空间中模拟不同生产场景,让遗传编程算法在数字孪生体上完成进化迭代;一旦找到最优解,系统会自动将参数下发到物理设备,实现“零误差”部署。
“这种‘先虚拟进化,再物理执行’的模式彻底改变了工业优化的范式。”西门子研究院院长Hans Müller表示,“过去我们需要数周甚至数月才能完成一次参数优化,现在通过数字孪生与遗传编程的结合,这个过程可以缩短到几天,甚至实时完成。” 2026年科技创新与在线教育热度持续攀升,相关产业迎来新机遇
未来已来:遗传编程如何重塑工业边缘计算的生态
站在2026年的时间节点回望,遗传编程已从实验室里的“小众算法”成长为工业边缘计算领域的“隐形冠军”,它不仅解决了传统边缘计算系统缺乏自适应能力的痛点,更推动了工业AI从“规则驱动”向“数据驱动+自主进化”的范式转变。
“遗传编程的真正价值不在于它比人类更聪明,而在于它能处理人类无法处理的复杂性。”麻省理工学院工业AI实验室主任Sarah Chen指出,“在未来的工业系统中,边缘设备将不再是被动的数据采集器,而是能自主学习、自主决策的智能主体,而遗传编程正是实现这一目标的关键技术之一。”
随着5G、物联网、数字孪生等技术的持续演进,遗传编程在工业边缘计算中的应用场景将进一步拓展,从智能制造到智慧能源,从自动驾驶到远程医疗,这场由遗传编程驱动的“自主进化”革命,正在悄然重塑人类与机器的协作方式——不是人类告诉机器“该怎么做”,而是机器自己学会“如何做得更好”。