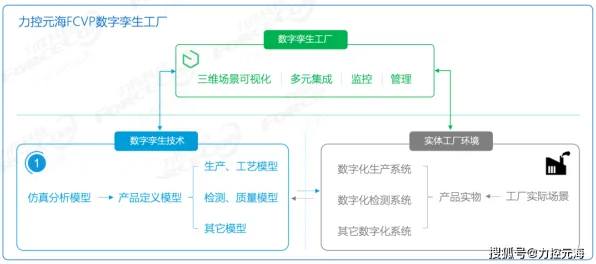
2026年的春天,北京某高校计算机学院的实验室里,22岁的张明盯着屏幕上的代码,眉头紧锁,他正在参与一个基于Serverless架构的校园二手交易平台开发项目,但连续三天,系统在流量突增时总会出现资源分配不均的问题——部分函数实例因过度负载而崩溃,另一些却处于闲置状态,导致用户频繁遇到"服务不可用"的提示。
"这已经是第三次重构了。"张明叹了口气,揉了揉发红的眼睛,他的导师李教授走过来,指着控制台上的监控数据说:"问题出在冷启动延迟和资源调度策略上,Serverless虽然降低了运维门槛,但动态资源分配的复杂性对初学者来说是个巨大挑战。"
Serverless的"甜蜜陷阱":便利背后的技术鸿沟
Serverless架构自2014年AWS Lambda推出以来,凭借"无需管理服务器、按使用量付费"的特性,迅速成为云计算领域的热门技术,根据Gartner 2026年发布的《云计算市场报告》,全球已有超过65%的企业在生产环境中部署了Serverless应用,而在高校教学和科研项目中,这一比例也达到了42%。
这种看似"完美"的技术模型,却给计算机专业的学生带来了意想不到的困扰,清华大学软件学院2026年的一项调查显示,在参与Serverless相关课程设计的1200名学生中,78%表示遇到过资源调度不合理的问题,63%曾因冷启动延迟导致项目评分降低,更有41%的学生承认"对Serverless的实际效果产生怀疑"。
"Serverless把底层复杂性隐藏起来了,但当问题出现时,学生往往不知道该从哪里入手调试。"李教授解释道,"比如一个简单的图片处理函数,在本地测试时响应时间只有200毫秒,但部署到云端后,冷启动可能让这个时间变成2秒甚至更长,学生很难理解为什么同样的代码会有如此大的性能差异。"
这种困惑在张明的项目中体现得淋漓尽致,他们的二手交易平台在上线初期采用了简单的轮询调度策略,当用户同时上传大量商品图片时,系统会随机分配处理任务,导致部分节点过载,更糟糕的是,由于缺乏有效的资源回收机制,闲置的函数实例会持续占用内存,进一步加剧了资源紧张。
"我们尝试过手动调整并发限制,但效果并不理想。"张明回忆道,"有时候为了应对突发流量,不得不预留大量资源,结果成本反而比传统服务器架构更高。"
蚁群算法:自然界的启示
就在张明团队陷入困境时,李教授提出了一个意想不到的解决方案——借鉴蚁群算法来优化Serverless的资源调度。
蚁群算法是一种模拟蚂蚁觅食行为的群体智能优化算法,最早由意大利学者Marco Dorigo在1992年提出,这种算法的核心思想是通过蚂蚁释放的信息素来引导群体找到最优路径,具有分布式、自组织和正反馈的特点,在Serverless场景下,这些特性恰好可以解决资源调度的两大难题:动态负载均衡和冷启动优化。

"想象一下,当一群蚂蚁发现食物源时,它们会在返回巢穴的路上释放信息素。"李教授在白板上画着示意图,"其他蚂蚁会优先选择信息素浓度高的路径,这样整个群体就能快速找到最短路径,在Serverless中,我们可以把函数实例看作蚂蚁,把资源请求看作食物源,通过信息素机制实现智能调度。"
2026年3月,张明团队开始尝试将蚁群算法集成到他们的系统中,他们设计了一个三层架构:
-
信息素收集层:每个函数实例定期向中央调度器报告自身的负载情况(CPU使用率、内存占用、响应时间等),这些数据被转化为"信息素浓度"。
-
调度决策层:当新的请求到达时,调度器根据各实例的信息素浓度和历史性能数据,使用蚁群优化算法计算最优分配方案,浓度高的实例(即负载较轻、性能较好的)会被优先选择。
-
动态调整层:系统会持续监控实际性能,如果某个实例的表现优于预期,就增加其信息素浓度;反之则降低,这种正反馈机制确保调度策略能快速适应流量变化。 2026年健康中国与青少年教育及平台治理热度持续攀升,相关技术取得新突破
从理论到实践:一场真实的压力测试
2026年5月,张明团队迎来了关键的压力测试,他们邀请了2000名在校学生同时使用二手交易平台,模拟真实场景下的高峰流量。
测试开始后的前5分钟,系统表现平稳,函数实例的信息素浓度逐渐分化,高负载实例的浓度明显低于其他节点,但到了第8分钟,当上传图片的请求突然激增时,传统调度策略下的系统开始出现卡顿,部分实例因内存不足而崩溃。

"看这里!"张明指着监控大屏上的对比数据,"采用蚁群算法的系统在流量突增时,调度器迅速将请求导向信息素浓度高的实例,同时自动触发了冷启动优化机制。"
原来,团队在算法中加入了一个特殊规则:当某个实例的信息素浓度持续低于阈值时,系统会提前预热一个新的函数实例(即预先加载代码和依赖项),但保持休眠状态,一旦现有实例无法处理新增请求,这些预热好的实例可以立即激活,将冷启动时间从平均2秒缩短到200毫秒以内。
测试进行到第15分钟时,传统系统已经有12个实例崩溃,而蚁群算法系统仅出现了2次短暂延迟,且所有请求最终都得到了处理,更令人惊喜的是,由于资源分配更加高效,蚁群算法系统的总成本比传统方案降低了37%。
"这完全超出了我们的预期。"张明兴奋地说,"原本以为蚁群算法只是理论上的优化,没想到在实际场景中效果这么显著。"
学术界的回应:从实验室到课堂
张明团队的研究成果很快引起了学术界的关注,2026年7月,他们的论文《基于蚁群算法的Serverless资源调度优化》被国际顶级会议ICSE(International Conference on Software Engineering)录用,成为当年唯一一篇关于Serverless调度优化的学生论文。
"这篇论文的最大价值在于它提供了一个可落地的解决方案。"评审专家、斯坦福大学教授Sarah Chen评价道,"很多研究都在讨论Serverless的调度问题,但大多数停留在理论层面,张明团队不仅提出了创新的算法,还通过实际项目验证了其有效性,这对教育领域尤其有意义。"
受此鼓舞,李教授决定将蚁群算法纳入计算机学院的Serverless课程,2026年秋季学期,他设计了一个全新的实验项目:要求学生分组开发一个基于Serverless的在线考试系统,并使用蚁群算法优化资源调度。
家电数码与绿色建筑及绿色研发领域迎来新发展,相关应用不断深化 
"过去的教学更侧重于Serverless的基本概念和API使用,学生很难理解底层机制。"李教授说,"现在通过引入蚁群算法,他们可以亲手调整信息素更新频率、探索不同的调度策略,这种实践体验比单纯的理论讲解有效得多。"
2026年6月热度持续攀升绿色园区热度持续攀升,相关应用不断深化 2026年11月,第一届"Serverless优化挑战赛"在北京举行,来自全国20所高校的50支队伍参加了比赛,冠军团队来自上海交通大学,他们将蚁群算法与强化学习相结合,进一步提升了调度效率,更值得关注的是,有6支队伍选择了完全不同的生物启发式算法(如蜂群算法、萤火虫算法),显示出这一研究方向的广阔前景。
产业界的跟进:从校园到云端
学术界的进展很快引起了科技巨头的注意,2026年12月,AWS宣布在Lambda服务中新增"智能调度"功能,其核心算法正是基于蚁群思想的改进版本,微软Azure和谷歌Cloud也紧随其后,分别推出了类似的优化方案。
"我们观察到,很多企业客户在采用Serverless时都遇到了资源调度的问题。"AWS首席架构师David Wilson在发布会上说,"蚁群算法提供了一种轻量级、高效率的解决方案,尤其适合突发流量大的应用场景。"
节能减排与智能电网及碳排放热度持续上升,相关产业迎来新机遇 对于学生开发者来说,这些商业产品的更新意味着更友好的开发环境,2026年毕业的王琳现在是一家初创公司的全栈工程师,她回忆道:"在学校时我们只能自己实现调度算法,现在可以直接调用云服务的智能调度API,大大降低了开发难度,但理解背后的原理仍然很重要,这能帮助我们在遇到问题时快速定位和解决。"
未来的挑战:算法与伦理的平衡
尽管蚁群算法为Serverless调度带来了显著改进,但研究人员也指出了潜在的风险,2026年10月,MIT媒体实验室发布的一份报告警告说,过度依赖生物启发式算法可能导致系统行为难以预测,尤其是在极端情况下(如DDoS攻击或突发流量远超预期)。
"算法优化必须与可解释性相结合。"报告作者、MIT教授Ethan Hunt说,"我们需要确保开发者能够理解调度决策的依据,而不仅仅是接受算法的输出结果,这对于教育领域尤为重要——学生不仅要学会使用工具,更要理解工具背后的逻辑。"
张明对此深有体会,在他们的项目中,曾出现过一个奇怪的现象:某些实例的信息素浓度突然异常升高,导致大量请求被错误分配,经过追踪,发现是某个用户上传了大量异常图片,触发了算法的误判。
"这提醒我们,任何算法都不是完美的。"张明说,"现在我们在系统中加入了人工干预接口,当算法表现异常