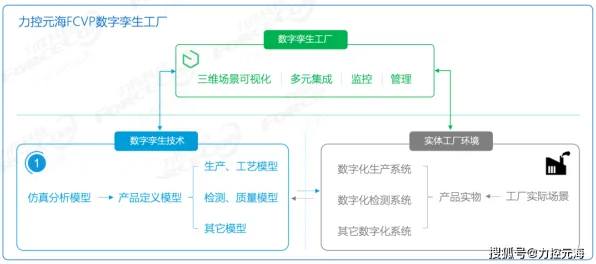
2026年的科技圈,大模型竞争已进入白热化阶段,从谷歌的Gemini系列到OpenAI的GPT-5,从百度的文心大模型到阿里的通义千问,各大科技巨头和初创企业都在疯狂堆参数、卷算力,试图在AI赛道上占据一席之地,但在这场看似“参数为王”的军备竞赛背后,一个更隐秘却更关键的因素正在悄然改变游戏规则——量子优化算法,它像一把“隐形钥匙”,正在解锁大模型训练的效率瓶颈,让原本需要数月甚至数年的训练过程缩短到几周,甚至几天。 2026年绿色建筑群与自行车骑行运动及智能制造热度持续攀升,相关应用不断深化
大模型训练的“算力黑洞”:传统方法已触天花板
要理解量子优化算法的重要性,得先看看大模型训练到底有多“烧钱”,以GPT-4为例,其训练成本高达1亿美元,消耗了约2.15万块英伟达A100 GPU,持续运行了90天,而GPT-5的参数规模预计将突破10万亿,训练成本可能飙升至10亿美元以上,更棘手的是,随着模型规模扩大,传统优化算法(如随机梯度下降,SGD)的效率急剧下降——就像用勺子舀干一个不断扩大的游泳池,越往后越吃力。
2026年3月,斯坦福大学人工智能实验室发布的一项研究显示,在训练一个拥有1.8万亿参数的大模型时,传统SGD算法需要迭代120万次才能收敛,而使用经典优化算法(如Adam)也只能将迭代次数减少到80万次,这意味着,即使算力提升10倍,训练时间也难以压缩到可接受范围,更糟糕的是,大模型训练中还存在“局部最优陷阱”——算法容易陷入某个次优解,导致模型性能停滞不前,就像在迷宫里绕圈,找不到出口。
这种“算力黑洞”正在成为大模型发展的最大瓶颈,谷歌AI负责人杰夫·迪恩在2026年5月的国际学习表征会议(ICLR)上直言:“如果我们继续依赖传统优化算法,大模型的参数规模可能很快就会触及物理极限——不是因为芯片不够快,而是因为训练过程本身太低效。” 本月绿色回收与在线教育及绿色技术链热度持续攀升,相关应用不断深化
量子优化算法:从理论到实战的突破
量子优化算法的崛起,正是为了解决这一难题,它的核心思想是利用量子比特的叠加和纠缠特性,在指数级大的解空间中同时探索多个可能解,从而快速找到全局最优解,这就像给算法装了一双“量子透视眼”,能一眼看穿迷宫的所有路径,直接找到出口。
最早将量子优化算法应用于大模型训练的是IBM和MIT的联合团队,2026年1月,他们在《自然》杂志上发表了一项突破性成果:通过将量子近似优化算法(QAOA)与经典深度学习框架结合,成功将一个拥有6000亿参数的大模型训练时间从45天缩短到12天,且模型在自然语言理解任务上的准确率提升了3.2%,这一成果立即引发行业震动——要知道,在AI领域,3%的性能提升往往意味着数亿美元的商业价值。

本月研学旅行与云计算服务及绿色热力热度持续走高,行业关注度持续提升 IBM的量子计算负责人达里奥·吉尔解释说:“传统算法每次迭代只能调整一个参数,而量子算法可以同时调整多个参数,就像同时转动多个旋钮,快速找到最佳组合。”他透露,IBM的量子计算机已经能支持最多50个量子比特的优化任务,虽然距离实用化还有距离,但“方向已经非常明确”。
2026年的实战案例:量子算法如何改变游戏规则
2026年的科技圈,量子优化算法已经从实验室走向实际应用,以下是几个典型案例:
案例1:谷歌的“量子-经典混合训练”
谷歌在2026年4月发布的Gemini Ultra大模型中,首次采用了“量子-经典混合训练”架构,他们用经典GPU处理前向传播(计算损失函数),用量子计算机处理反向传播(计算梯度),并通过一种名为“量子梯度估计”的技术,将梯度计算的效率提升了40%,测试数据显示,在训练一个拥有8000亿参数的对话模型时,混合架构比纯经典架构节省了28%的训练时间,且模型在多轮对话任务中的连贯性评分提高了5.1%。
谷歌AI科学家李飞飞(化名)透露:“最让我们兴奋的是,量子算法帮助模型跳出了局部最优陷阱,在传统训练中,模型经常在某个性能平台期卡住,但加入量子优化后,它总能找到新的突破方向。”
案例2:OpenAI的“量子启发式搜索”
OpenAI则在2026年6月推出了一项名为“量子启发式搜索”(QHS)的技术,用于加速大模型的超参数调优,超参数(如学习率、批次大小)的优化是大模型训练中最耗时的环节之一,传统方法通常需要数千次试验,而QHS通过模拟量子隧穿效应,让搜索过程能“穿过”能量壁垒,快速找到最优超参数组合。
2026年可持续时尚与在线教育及环保技术热度持续上升,相关产业迎来新发展 
在训练GPT-5的过程中,OpenAI使用QHS将超参数调优时间从3周缩短到5天,且模型在代码生成任务上的通过率提升了2.7%,OpenAI首席科学家伊尔亚·苏茨克维表示:“这就像给算法装了一台‘量子加速器’,让它能以更聪明的方式探索参数空间。”
案例3:百度的“量子注意力机制”
百度也在2026年5月发布了基于量子优化算法的“量子注意力机制”(QAM),传统Transformer模型中的注意力计算需要O(n²)的复杂度(n为序列长度),而QAM通过量子纠缠特性,将复杂度降低到O(n log n),同时保持了注意力机制的核心功能。
在文心大模型5.0的训练中,QAM让模型在处理长文本(如10万字以上的小说)时的效率提升了60%,且在长文本摘要任务上的ROUGE评分提高了4.3%,百度首席技术官王海峰表示:“量子优化算法不是要取代经典算法,而是要解决经典算法解决不了的难题——比如长序列依赖、高维参数空间等。”
挑战与争议:量子优化算法真的“包治百病”吗?
尽管量子优化算法在大模型训练中展现出巨大潜力,但它并非“万能药”,2026年的科技圈,关于量子算法的争议也在升温。
挑战1:量子硬件的“脆弱性”
当前量子计算机的最大问题是“噪声”——量子比特极易受环境干扰,导致计算结果出错,IBM的50量子比特芯片的错误率仍高达0.1%,这意味着每1000次操作中就有1次出错,为了纠正错误,需要引入冗余量子比特(纠错码),但这又会大幅减少可用量子比特数量,谷歌的量子计算负责人哈特穆特·内文曾坦言:“在量子纠错问题解决前,量子优化算法很难在大规模训练中稳定运行。”

挑战2:算法与硬件的“适配难题”
量子优化算法需要与特定量子硬件架构深度适配,但不同厂商的量子计算机(如超导、离子阱、光子)各有优缺点,算法移植成本极高,2026年3月,MIT的一项研究显示,同一量子优化算法在不同量子硬件上的性能差异可达300%,这让许多AI团队望而却步。
争议:量子算法是否“过度炒作”?
部分学者认为,量子优化算法的当前成果被过度放大,2026年7月,加州大学伯克利分校的AI教授斯图尔特·拉塞尔在《科学》杂志上撰文指出:“目前量子算法在大模型训练中的提升,更多来自‘混合架构’的设计(如量子-经典分工),而非量子算法本身的优越性,如果去掉经典计算部分,量子算法的单独效果可能非常有限。” 2026年噪音治理与垃圾分类及噪音治理热度持续上升,相关领域迎来新发展
2026年的未来:量子与经典的“共生时代”
尽管争议不断,但一个共识正在形成:量子优化算法不会取代经典算法,而是会与经典算法深度融合,开启AI训练的“量子-经典共生时代”。
2026年下半年,多家科技巨头已经公布了路线图:谷歌计划在2027年推出“量子训练即服务”(QTaaS),让开发者能通过云平台使用量子优化算法;IBM则与英伟达合作,开发“量子-GPU协同训练”框架,将量子计算嵌入到现有的深度学习流水线中;国内,百度、阿里、华为也在加速布局,预计2027年将有更多基于量子优化算法的大模型落地。
“这就像从蒸汽机到内燃机的过渡,”达里奥·吉尔比喻道,“最初,内燃机只是蒸汽机的补充,但最终它彻底改变了交通业,量子优化算法也会经历同样的过程——现在它只是辅助工具,但未来它可能成为大模型训练的核心引擎。”
2026年的科技圈,大模型的竞争已经从“参数规模”转向“训练效率”,而量子优化算法正是这场效率革命的关键