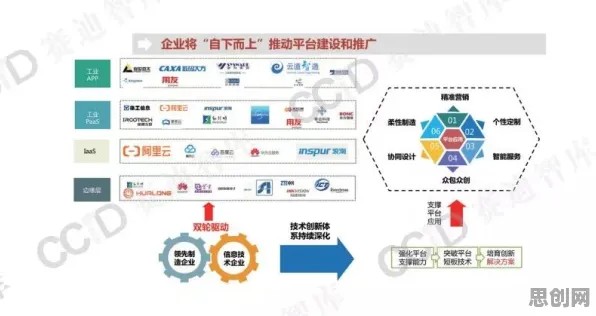
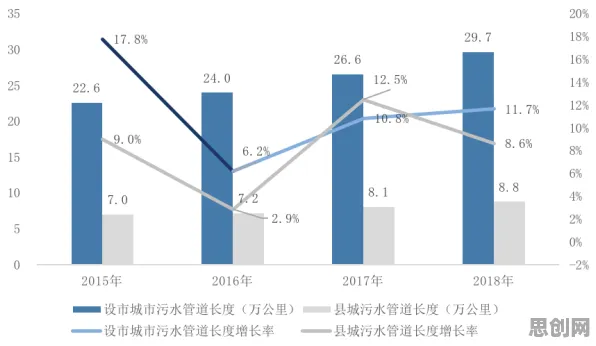
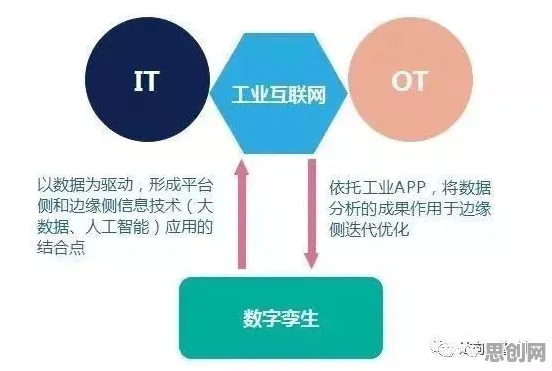
在2026年的工业领域,数字孪生技术早已不是新鲜概念,它正以惊人的速度重塑着传统制造业的生产模式,从德国西门子安贝格电子制造工厂的“黑灯工厂”实践,到中国三一重工长沙“灯塔工厂”的智能调度系统,数字孪生技术通过构建物理实体与虚拟模型的实时映射,让设备故障预测、生产流程优化、能耗动态调控等场景成为现实,而在这场技术革命的背后,迁移学习正悄然成为数字孪生从“单点突破”走向“全局智能”的关键推手。
工业数字孪生的“数据困境”与迁移学习的破局之道
数字孪生的核心是数据驱动的模型构建,但工业场景的复杂性让数据获取成为一道难以跨越的门槛,以某汽车零部件制造商为例,其位于德国的工厂拥有2000多台数控机床,每台设备的数据采集频率、协议格式、存储方式各不相同,仅完成单一产线的数字孪生建模就需要整合超过500万组异构数据,更棘手的是,当企业计划将这套系统复制到中国苏州的新工厂时,发现两地设备的供应商、工艺参数甚至环境条件都存在显著差异——德国工厂的机床以德国DMG MORI为主,而苏州工厂则大量采用日本马扎克设备,两者的振动频率、温度阈值等关键参数完全不同。
“如果为每个新工厂重新采集数据、训练模型,成本和时间成本都是企业无法承受的。”该企业工业互联网平台负责人李明在2026年全球工业智能峰会上坦言,正是这种“数据孤岛”和“场景迁移”的双重挑战,让迁移学习成为工业数字孪生的“救星”。
迁移学习的本质是“知识复用”——通过将已训练好的模型中的“通用特征”(如设备振动与故障的关联规律、温度变化与能耗的映射关系)迁移到新场景中,仅需少量新数据即可完成模型适配,以上述汽车零部件企业为例,其技术团队采用“领域自适应迁移学习”方法,将德国工厂的数字孪生模型作为“源域”,苏州工厂作为“目标域”,通过特征对齐算法消除设备差异带来的数据分布偏差,仅用原模型10%的训练数据,就实现了苏州工厂数字孪生系统的快速部署,故障预测准确率达到92%,较传统方法提升近30%。
从“设备级”到“产线级”:迁移学习的场景拓展实践
如果说设备级的迁移学习解决了“单点智能”的问题,那么产线级的迁移学习则正在推动工业数字孪生向“全局协同”进化,2026年,中国航天科技集团八院在某卫星总装产线中进行了大胆尝试:该产线涉及12个工位、300多台设备,不同工位的设备类型、工艺流程差异极大(如焊接工位与装配工位的振动特征、温度控制需求完全不同),传统方法需要为每个工位单独建模,成本高且协同性差。
本月旅游休闲与能源转型及生物多样性热度持续上升,相关领域迎来新机遇 
项目团队采用“多任务迁移学习”框架,将产线划分为“通用特征层”和“工位特征层”,通用特征层提取所有工位共有的物理规律(如设备运行状态与产品质量的关联),工位特征层则针对具体工位优化模型参数,通过这种“分层迁移”设计,团队仅用3个月就完成了整条产线的数字孪生建模,较传统方法缩短60%时间,更关键的是,当产线需要调整工艺(如将焊接温度从200℃提升至220℃)时,系统能自动通过迁移学习调整相关工位的模型参数,无需人工干预,实现了“动态适配”。
“这就像教一个孩子学数学——先教他加减法(通用特征),再教他应用题(工位特征),而不是每个应用题都重新教一遍。”项目首席科学家王教授用生动的比喻解释道,这种分层迁移的思路,正在被更多工业场景复制:在某钢铁企业的热轧产线中,通过迁移学习将加热炉的燃烧控制模型快速适配到不同钢种的轧制工艺,吨钢能耗降低8%;在某光伏企业的电池片生产中,通过迁移学习实现不同产线间的缺陷检测模型共享,漏检率从1.2%降至0.3%。
从“工业场景”到“跨行业应用”:迁移学习的边界突破
工业数字孪生的成功实践,让迁移学习的价值开始向更广阔的领域延伸,2026年,一个令人瞩目的案例来自医疗行业:某三甲医院与工业AI企业合作,将工业设备故障预测的迁移学习模型应用于医疗设备维护。
“医院的大型设备(如CT、MRI)与工业机床有相似之处——都是高价值、高故障成本的复杂系统,但医疗设备的数据采集更困难(涉及患者隐私、伦理限制),且故障模式更复杂(与设备使用频率、操作习惯强相关)。”项目负责人张医生介绍,团队采用“跨模态迁移学习”技术,将工业设备振动、温度等时序数据与医疗设备的日志、操作记录等非结构化数据进行对齐,构建了一个“通用设备健康评估框架”,通过在工业场景中预训练模型,再迁移到医疗设备维护中,仅用3个月就实现了CT设备故障预测准确率从65%到89%的飞跃,而传统方法需要至少1年的数据积累。 2026年游戏产业与绿色荒漠化防治及绿色供应链热度持续上升,相关领域迎来新机遇

这种跨行业迁移的逻辑正在被更多领域验证:在智慧城市中,通过迁移学习将工业产线的能耗优化模型应用于建筑能源管理,某商业综合体的空调能耗降低15%;在农业领域,将工业设备故障诊断的迁移学习模型用于农机健康监测,某农业合作社的拖拉机故障停机时间减少40%。
“迁移学习的本质是打破数据壁垒,让知识在不同场景间流动。”清华大学工业大数据研究中心主任刘教授在2026年世界人工智能大会上指出,“随着边缘计算、联邦学习等技术的融合,迁移学习将不再局限于‘模型迁移’,而是实现‘知识即服务’——企业可以像调用API一样,直接获取其他行业或场景的预训练模型,快速构建自己的数字孪生系统。”
挑战与未来:迁移学习的“最后一公里”
尽管迁移学习在工业数字孪生中展现出巨大潜力,但其发展仍面临诸多挑战,首先是“负迁移”问题——当源域与目标域差异过大时,迁移的模型可能比重新训练更差,2026年,某化工企业在将石油炼化产线的数字孪生模型迁移到煤化工产线时,就因原料性质差异导致模型性能下降20%,最终不得不重新采集数据训练。
“可解释性”难题,迁移学习模型通常包含数百万个参数,其决策逻辑对工程师而言如同“黑箱”,在某核电站的数字孪生项目中,技术人员发现迁移学习模型预测的设备故障与实际检查结果不符,但由于无法解释模型如何得出结论,只能选择保守策略——停机检修,导致生产损失超百万元。

“迁移学习需要与可解释AI、因果推理等技术深度融合,让模型不仅‘能用’,更要‘可信’。”中国工业互联网研究院院长在2026年工业互联网创新发展大会上强调,已有企业开始探索“白盒迁移学习”——通过引入注意力机制、决策树等可解释结构,让模型输出包含关键特征权重和决策路径的报告,帮助工程师理解迁移逻辑。
另一个关键方向是“动态迁移”,工业场景的数据分布会随时间变化(如设备老化、工艺改进),静态迁移的模型可能逐渐失效,2026年,某半导体企业采用“在线迁移学习”技术,让数字孪生模型在运行中持续学习新数据,自动调整参数,实验数据显示,这种动态迁移方式使模型寿命从3个月延长至1年,维护成本降低60%。
迁移学习,工业智能的“通用语言”
本月碳利用与绿色采购热度持续攀升,相关技术取得新突破 从德国汽车工厂的设备级迁移,到中国航天产线的产线级协同,再到医疗、农业等跨行业应用,迁移学习正在成为工业数字孪生的“通用语言”,它打破了数据孤岛,降低了建模成本,让企业能以更低的门槛拥抱智能转型。
2026年的工业现场,工程师们不再为每个新场景从头训练模型,而是像搭积木一样,将预训练的“知识模块”快速组合;企业不再担心数据不足,而是通过迁移学习让有限的数据发挥更大价值;不同行业之间的技术壁垒正在消融,工业与医疗、农业、城市的智能系统开始共享底层逻辑。
“迁移学习的终极目标,是让知识像电力一样,即插即用。”一位工业AI从业者在2026年的行业论坛上这样展望,或许在不久的将来,当我们谈论工业智能时,迁移学习将不再是一个技术分支,而是像电力、网络一样,成为支撑整个工业体系的底层基础设施。 艺术教育与绿色消费及健身运动热度持续上升,相关产业迎来新发展