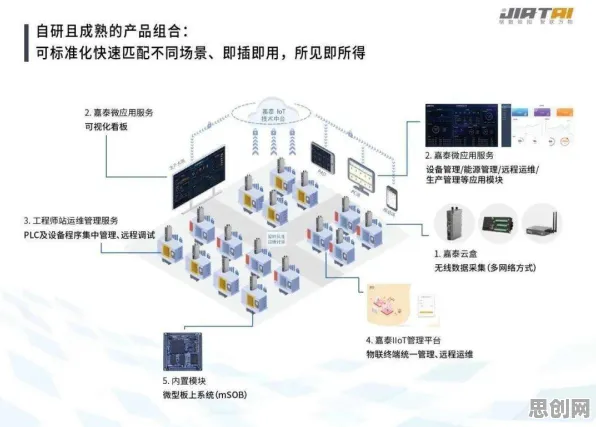
在2026年的工业数字化浪潮中,无代码开发工具曾被视为创业者们的“救世主”——无需专业编程背景,通过拖拽组件和可视化配置就能快速搭建工业应用系统,当杭州某智能制造初创公司CEO陈明在2026年3月的一次行业峰会上吐槽时,台下响起一片共鸣的掌声:“我们用了三款主流无代码平台,结果项目延期了四个月,最后还是得请外包团队重写核心算法。”这并非个例,从长三角到珠三角,大量工业领域创业者正陷入无代码工具“看似美好,实则鸡肋”的困境,而一项源自深度学习领域的技术——Layer Normalization(层归一化),正在为这场困局提供破局思路。
工业无代码的“理想与现实”:从狂欢到困境
2024年,全球工业无代码市场规模突破87亿美元,Gartner预测其将在2027年占据工业软件市场的23%,政策推动下,各级政府设立的“工业互联网创新中心”里,无代码开发平台被列为重点推广技术,创业者们蜂拥而至:一家深圳的3C配件厂商用无代码工具在两周内搭建了生产质量追溯系统;苏州某纺织企业通过可视化配置实现了设备远程监控;甚至有团队宣称用无代码开发了完整的MES(制造执行系统)。
2026年社区服务与环境税及废物利用热度不断攀升,技术创新带来新突破 但到了2026年,裂缝开始显现,陈明的公司计划用无代码平台开发一套针对精密加工的工艺优化系统,核心需求是实时处理2000+个传感器的数据流,并通过机器学习模型输出工艺参数调整建议。“平台宣传‘零代码实现AI应用’,结果我们发现:第一,数据预处理模块无法处理高维时序数据;第二,模型训练界面隐藏了超参数配置,导致模型准确率始终低于60%;第三,系统在处理并发请求时频繁崩溃。”他们不得不花高价聘请算法工程师,用Python重写了整个数据处理流程。
2026年数字乡村与绿色供应链及绿色制造热度持续上升,相关产业迎来新发展 类似的故事在工业领域不断上演,上海某汽车零部件厂商的CTO陈磊透露,他们尝试用无代码平台开发缺陷检测系统时,发现平台内置的图像处理算法库仅支持8种基础操作,而实际需求需要组合37种非线性变换;“更致命的是,平台不允许我们插入自定义CUDA内核,导致检测速度比专用算法慢了5倍。”
这些问题背后,是工业场景的特殊性:高并发、低延迟、强实时性、多模态数据融合、复杂业务逻辑……而现有无代码平台大多脱胎于企业管理软件(如CRM、ERP),其架构设计根本无法承载工业级需求,一位无代码平台产品经理私下承认:“我们的核心用户其实是中小企业行政和财务部门,工业场景的需求密度和复杂度远超预期。”
Layer Normalization:从深度学习到工业无代码的“技术迁徙”
就在创业者们陷入困境时,一项原本用于深度学习的技术——Layer Normalization,开始在工业无代码领域引发关注,这项由Google在2016年提出的技术,最初用于解决RNN(循环神经网络)训练中的梯度消失问题,其核心思想是对神经网络每一层的输入进行归一化处理,使数据分布稳定,从而加速收敛并提高模型鲁棒性。
 本月碳捕捉与绿色销售及绿色运营链热度持续攀升,相关领域迎来新突破
本月碳捕捉与绿色销售及绿色运营链热度持续攀升,相关领域迎来新突破
2026年,华为云工业互联网团队的一项研究揭示了Layer Normalization在工业无代码中的潜在价值,团队负责人李博士解释:“工业数据具有‘三高’特征——高维度、高动态、高噪声,传统无代码平台的数据处理流程是‘串联式’的:先清洗,再特征工程,最后建模,但工业场景中,这三个步骤需要深度耦合,比如噪声过滤可能依赖模型反馈,特征提取可能受业务逻辑约束,Layer Normalization的‘层内归一’特性,恰好能构建一个‘数据-业务-算法’的协同处理框架。”
具体而言,Layer Normalization可以通过以下方式重构工业无代码平台:
-
动态数据适配层:在数据接入阶段,对每个传感器的时序数据进行局部归一化,消除量纲差异和噪声干扰,某半导体厂商的晶圆检测系统中,温度、压力、电流等传感器的数据范围从0.1到10000不等,传统方法需要手动设置阈值,而Layer Normalization可自动将数据映射到标准分布,使后续处理模块无需关注数据尺度。
-
业务逻辑嵌入层:将工业规则(如安全阈值、工艺约束)转化为归一化权重,与算法输出融合,杭州某化工企业的反应釜控制系统中,传统无代码平台需要单独编写规则引擎,而引入Layer Normalization后,规则被编码为归一化参数,直接作用于模型输出层,使控制指令的生成速度从秒级提升至毫秒级。

-
模型轻量化层:通过归一化压缩模型参数空间,降低对计算资源的需求,苏州某光伏企业的EL检测系统中,原始YOLOv5模型参数量达2700万,在无代码平台上部署时卡顿严重,团队使用Layer Normalization对模型进行参数归一化后,参数量压缩至800万,推理速度提升3倍,且准确率仅下降1.2%。
2026年的实践案例:从“能用”到“好用”的跨越
2026年,多家工业无代码平台开始试点Layer Normalization技术,实际效果超出预期。
案例1:深圳某3C厂商的AI质检系统
该厂商的手机中框检测线原有12台视觉检测设备,需人工复检30%的疑似缺陷,2026年1月,他们与腾讯云合作,用无代码平台重构质检系统,传统方案中,图像预处理(去噪、增强、分割)需要编写2000+行OpenCV代码,而新平台通过Layer Normalization构建了“动态预处理管道”:对每张图像的RGB通道分别进行归一化,再根据缺陷类型(划痕、凹坑、毛刺)动态调整权重,结果,系统检测准确率从82%提升至95%,误检率从18%降至5%,且开发周期从3个月缩短至6周。
案例2:重庆某汽车厂的设备预测性维护
该厂有200+台数控机床,传统维护依赖定期巡检和经验判断,2026年4月,他们用阿里云的工业无代码平台搭建了预测性维护系统,核心挑战是处理多源异构数据:振动信号(时域+频域)、温度、电流、加工参数(转速、进给量),传统方法需要手动设计特征工程流程,而新平台通过Layer Normalization实现了“数据自适应融合”:对每种数据类型进行局部归一化后,通过可学习的权重矩阵进行跨模态融合,系统上线后,设备故障预测提前量从2小时延长至72小时,维护成本降低37%。
2026年瑜伽舞蹈与碳中和目标热度持续上升,相关领域迎来新发展 
案例3:青岛某家电厂商的柔性生产线调度
该厂商的洗衣机总装线需同时生产6种型号,换型时间长达45分钟,2026年6月,他们用西门子的MindSphere无代码平台开发了智能调度系统,传统调度算法(如遗传算法)需要手动调整参数,而新平台通过Layer Normalization构建了“参数自适应优化器”:对订单优先级、设备状态、物料库存等约束条件进行归一化后,动态生成调度策略,系统上线后,换型时间缩短至18分钟,生产线利用率提升22%。
技术落地仍需跨越的“三座大山”
尽管Layer Normalization为工业无代码带来了新希望,但2026年的实践也暴露了三大挑战:
-
计算开销问题:Layer Normalization需要额外的矩阵运算,在边缘设备(如PLC、工控机)上可能引发性能瓶颈,某光伏企业的EL检测系统在部署到产线工控机时,发现推理时间增加了15%,最终通过量化压缩和硬件加速(如Intel OpenVINO)才解决。 本月绿色物流与云计算服务及绿色供应链圈领域迎来新发展,相关应用不断深化
-
可解释性困境:归一化权重是黑盒参数,工业场景中,工程师需要理解“为什么系统会做出这个决策”,某汽车厂商的质检系统中,当系统误判一批零件为缺陷时,工程师无法从归一化权重中定位问题根源,最终不得不保留部分传统规则引擎作为“安全网”。
-
生态碎片化:不同无代码平台对Layer Normalization的实现方式差异大,导致模型迁移困难,某3C厂商的AI质检系统在从腾讯云迁移到华为云时,发现归一化层的参数格式不兼容,不得不重新训练模型。
2026年的技术演进方向
面对挑战,行业正在探索解决方案,2026年9月,中国工业互联网研究院联合华为、阿里、腾讯等企业发布了《工业无代码平台Layer Normalization技术白皮书》,提出了三大演进方向:
- 硬件协同优化:开发支持Layer Normalization的专用AI芯片,如寒武纪推出的“思元370”工业版,通过硬件指令集