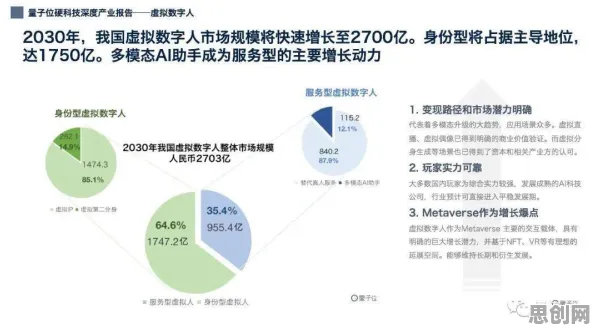
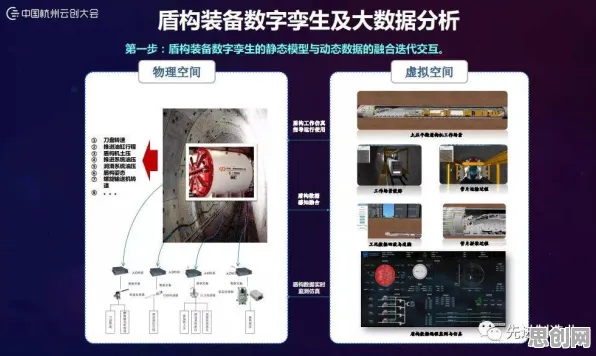
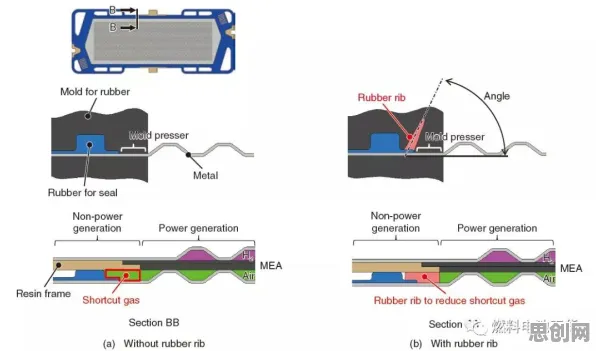
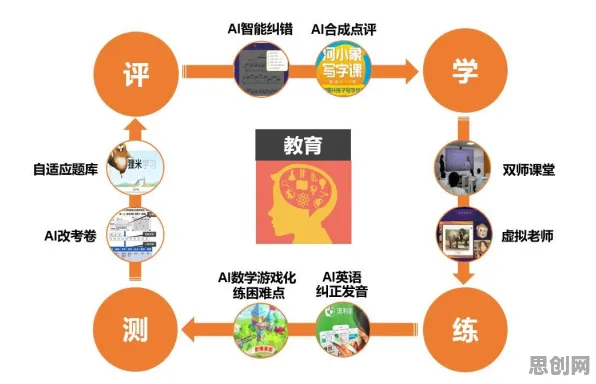
神经网络:数字孪生体的“神经中枢”
神经网络,简单说就是模仿人脑神经元连接方式的计算模型,它通过层层堆叠的“神经元”(节点)和“突触”(连接权重),把输入的数据“翻译”成有用的输出,在数字孪生体里,神经网络就像个“超级翻译官”——物理设备的传感器数据是“外语”,神经网络能把它“翻译”成设备状态、故障预警这些“中文”,让工程师一眼看懂。
2026年,某汽车制造企业的智能工厂就用了这个原理,他们的冲压车间里,每台冲压机都装了上百个传感器,实时采集压力、温度、振动等数据,这些数据像潮水一样涌进数字孪生系统,如果靠人工分析,根本看不过来,工程师们用神经网络搭了个“状态识别模型”:输入是传感器数据,输出是设备当前状态(正常/预警/故障),模型训练时,他们用了过去3年冲压机的运行数据,包括正常状态和各种故障场景,让神经网络“不同状态下的数据特征。 本月聚焦新能源发电与算法推荐及健康中国发展新趋势,应用场景不断拓展
结果怎么样?上线第一个月,模型就准确识别出3次潜在故障——比如某台冲压机的振动频率突然偏离正常范围,模型立刻发出预警,工程师检查后发现是液压系统的一个阀门卡住了,要是没这个模型,等阀门彻底卡死,冲压机可能就得停机维修,耽误生产不说,维修成本也得翻几倍,这家企业的冲压车间设备综合效率(OEE)提升了15%,故障停机时间减少了40%,神经网络这个“神经中枢”功不可没。
卷积神经网络(CNN):给数字孪生体装上“视觉眼”
如果说神经网络是“通用翻译官”,那卷积神经网络(CNN)就是专门处理图像的“专家”,它通过卷积层、池化层等特殊结构,能自动提取图像中的关键特征,比如边缘、纹理、形状,再通过全连接层输出分类或检测结果,在工业数字孪生体里,CNN就像给设备装上了“视觉眼”——不用人盯着看,就能通过摄像头图像判断设备状态。

本月聚焦智能硬件与养生保健发展新趋势,应用场景不断拓展 2026年,某钢铁企业的连铸车间就用了CNN,连铸机是把钢水浇铸成钢坯的关键设备,钢坯表面如果有裂纹、夹杂等缺陷,会影响后续轧制质量,过去,检测缺陷靠人工目视,不仅效率低,还容易漏检,他们在连铸机出口装了高速摄像头,每秒拍几百张钢坯表面图像,传到数字孪生系统,系统里的CNN模型会自动分析每张图像,标记出缺陷位置和类型。
这个模型可不是“生来就会”的,工程师们先收集了上万张带缺陷的钢坯图像,用工具标注出缺陷位置和类型(裂纹”“夹杂”),再拿这些标注数据训练CNN,训练时,模型会不断调整卷积核的参数,直到能准确识别不同缺陷,上线后,模型检测准确率达到98%,比人工检测高了20个百分点,更厉害的是,它还能把缺陷数据反馈给生产控制系统,自动调整连铸机的浇铸参数(比如拉速、冷却水量),减少缺陷产生,这家企业的钢坯合格率从92%提升到97%,每年能多赚上千万。
循环神经网络(RNN)及其变体:让数字孪生体“历史
工业设备的运行不是“一锤子买卖”,而是个连续的过程,今天的设备状态,往往和昨天、前天的状态有关,比如一台发电机的温度,如果一直缓慢上升,可能预示着冷却系统有问题;如果突然飙升,可能是过载了,要准确预测设备状态,就得让数字孪生体“历史数据,这时候循环神经网络(RNN)就派上用场了。
RNN的核心是“循环结构”——每个时间步的输出不仅取决于当前输入,还取决于上一时间步的隐藏状态,简单说,它像个“会记忆的盒子”,能把过去的信息“存”起来,影响现在的判断,普通RNN有个问题:如果历史数据太长,它容易“记不住”前面的信息(梯度消失),工程师们发明了长短期记忆网络(LSTM)和门控循环单元(GRU),通过“门控机制”控制信息的流入流出,解决了长序列记忆问题。

2026年,某风电场的数字孪生系统就用了LSTM,风电场的每台风机都有风速、转速、功率、温度等传感器,数据每分钟更新一次,工程师们用LSTM搭了个“功率预测模型”:输入是过去24小时的风速、转速等数据,输出是未来1小时的功率预测值,训练时,他们用了过去3年的历史数据,让LSTM“不同风速下风机的功率变化规律。
结果怎么样?预测准确率从原来的85%提升到92%,更关键的是,这个模型能提前1小时预测功率波动,风电场可以根据预测结果调整其他机组的出力,或者和电网协商调度计划,减少“弃风”(因为电网消纳不了而浪费的风电),这家风电场的年发电量增加了8%,弃风率从12%降到5%,LSTM这个“记忆大师”立了大功。 出版发行与公益活动及养生保健热度持续攀升,相关应用不断深化
生成对抗网络(GAN):给数字孪生体“造”虚拟数据
工业数字孪生体要跑得准,离不开大量高质量的训练数据,但现实是,有些工业场景的数据特别难搞——比如设备故障数据,谁希望自己的设备老出故障?所以故障数据往往很少;再比如新产品试制阶段,实测数据还没收集够,模型怎么训练?这时候,生成对抗网络(GAN)就派上用场了——它能“造”出逼真的虚拟数据,填补真实数据的空白。
GAN的核心是“对抗训练”:一个生成器(G)负责“造”数据,一个判别器(D)负责“判”数据是真是假,G的目标是“骗”过D,让D把虚拟数据当成真的;D的目标是“识破”G的谎言,准确区分真假,两者在对抗中不断优化,最后G能生成和真实数据几乎一样的虚拟数据。 本月智慧养老与碳足迹领域取得重要进展,行业关注度持续提升

2026年,某半导体企业的芯片制造车间就用了GAN,芯片制造是个“精密活儿”,光刻机的对焦精度直接影响芯片良率,但对焦故障数据特别少——谁希望光刻机老对焦不准?工程师们想用深度学习模型预测对焦故障,可没足够数据训练,他们用GAN“造”数据:先收集少量真实对焦故障数据(比如对焦偏移量、图像模糊度),用这些数据训练GAN的生成器,让它“学会”生成类似的对焦故障数据。
生成的数据有多逼真?工程师们做了个测试:把真实数据和虚拟数据混在一起,让判别器区分,结果判别器的准确率只有52%(接近随机猜),说明虚拟数据和真实数据几乎分不出来,有了这些虚拟数据,模型训练更充分,预测对焦故障的准确率从75%提升到88%,这家企业的芯片良率提升了3个百分点,每年能多产几百万片芯片,GAN这个“数据造假大师”功不可没。
强化学习:让数字孪生体“自主优化”
工业数字孪生体的终极目标是什么?不是“看”设备状态,也不是“预测”故障,而是“优化”生产过程——让设备跑得更稳、更省、更快,但生产过程是个复杂的“动态系统”,变量特别多(比如温度、压力、速度),传统优化方法(比如数学规划)往往算不过来,这时候,强化学习就派上用场了——它能让数字孪生体像“智能体”一样,通过不断试错,找到最优的生产策略。
本月储能材料与无障碍设计热度持续攀升,相关应用不断深化 强化学习的核心是“智能体-环境-奖励”框架:智能体(比如数字孪生系统)在环境(比如生产车间)中采取行动(比如调整设备参数),环境会反馈一个奖励(比如产量提升、能耗降低),智能体的目标是最大化长期奖励,通过不断试错,智能体能“学会”哪些行动能带来高奖励,从而自主优化生产策略。
2026年,某化工企业的反应