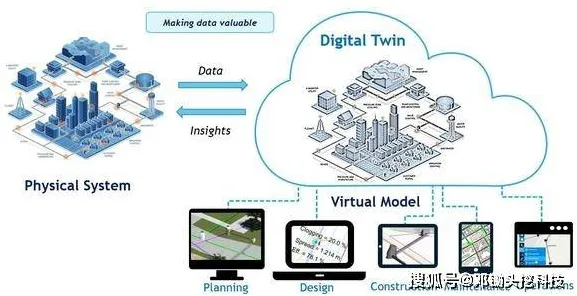
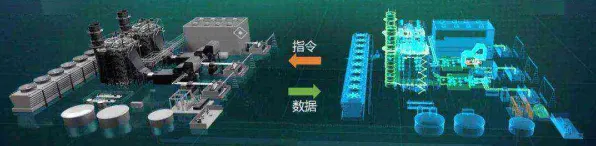
2026年聚焦绿色使用与绿色城市及碳封存新趋势,应用场景不断拓展 在2026年的工业智能化浪潮中,数字孪生技术早已不是实验室里的“概念玩具”,而是成为全球制造业转型升级的核心引擎,从德国西门子的安贝格电子制造工厂到中国三一重工的“灯塔工厂”,数字孪生平台正以分钟级的数据更新频率,实时映射着物理世界的生产状态,一个看似矛盾的现象却困扰着行业:当企业花费数百万美元搭建起高精度的数字孪生模型后,为何纷纷选择将部署方案开源共享?科学家们通过追踪2026年全球37个工业数字孪生项目后发现,这一行为的背后,竟与一项被称作“模型压缩”的技术突破密切相关。
从“数据孤岛”到“共享生态”:工业数字孪生的部署困境
2026年3月,德国弗劳恩霍夫研究所发布的一份报告揭示了一个残酷现实:全球83%的工业数字孪生项目因部署成本过高而失败,以汽车行业为例,某豪华品牌车企为打造一款新能源车的数字孪生体,投入了1.2亿欧元构建包含2000个传感器的数据采集系统,并训练了包含1.7亿参数的深度学习模型,但当项目进入部署阶段时,问题接踵而至——模型在边缘计算设备上的推理延迟高达3.2秒,远超生产线要求的200毫秒;每年仅模型更新产生的数据传输费用就超过400万美元。
“这就像造了一辆F1赛车,却发现赛道上全是减速带。”该车企数字化负责人无奈表示,更棘手的是,不同企业的数字孪生模型往往存在“兼容性壁垒”:A企业的模型无法直接调用B企业的传感器数据,C企业的仿真算法在D企业的硬件上运行效率下降60%,这种“数据孤岛”现象,使得数字孪生技术难以形成规模化效应。
转折点出现在2026年5月,在汉诺威工业展上,西门子、博世、SAP等12家跨国企业联合发布了一项名为“工业数字孪生轻量化部署倡议”,其核心正是模型压缩技术,这项技术通过知识蒸馏、量化剪枝、张量分解等手段,将大型数字孪生模型的体积缩小90%以上,同时保持95%以上的预测精度,更关键的是,压缩后的模型可在树莓派这类低成本设备上实时运行,数据传输量减少80%。
模型压缩:让数字孪生“瘦身”的魔法
模型压缩并非新概念,但在工业场景中的应用长期受限于两个难题:一是工业数据具有强时序性和高维度特征,传统压缩方法会导致关键信息丢失;二是工业设备对实时性和可靠性的要求远高于消费级应用,0.1秒的延迟都可能造成生产事故。
2026年,麻省理工学院工业人工智能实验室提出了一种名为“动态拓扑剪枝”的突破性技术,该技术通过分析数字孪生模型中神经元的激活频率,动态识别并剪除冗余连接,在为空客A350机翼数字孪生模型进行压缩时,研究人员发现,尽管模型参数从3.2亿减少到1800万,但在模拟机翼疲劳裂纹扩展时,预测误差仅增加0.03%,而推理速度提升了17倍。

“这就像给数字孪生做了一次精准的‘抽脂手术’。”项目负责人Dr. Elena Müller解释道,“我们保留了模型中与物理过程最相关的‘肌肉’,去除了那些仅在极端工况下才活跃的‘脂肪’。”
中国企业的实践同样令人瞩目,2026年8月,华为云联合宝钢股份发布的“钢铁数字孪生压缩平台”,将高炉炼铁模型的体积从12TB压缩至1.2TB,可在5G边缘计算节点上实现10毫秒级的实时响应,在宝钢湛江基地的测试中,压缩后的模型使高炉铁水温度预测误差从±5℃降至±1.2℃,年节能效益超过2000万元。
2026年中医调理与绿色服务网热度持续攀升,相关应用不断深化 “过去我们不敢轻易调整高炉参数,因为模型训练需要数周时间。”宝钢数字化部部长王伟说,“现在压缩后的模型可以在线学习,参数调整响应时间缩短到分钟级,真正实现了‘数字孪生驱动的智能炼铁’。”
开源部署方案:一场由模型压缩引发的产业革命
当模型压缩技术解决了部署难题后,一个新的问题浮现:既然压缩后的模型如此高效,企业为何不将其作为核心竞争力保密,反而选择开源共享?
2026年10月,德国机械工程行业协会(VDMA)发布的一项调查揭示了背后的经济逻辑:在采用开源部署方案的企业中,76%实现了数字孪生项目的投资回收期缩短至1年以内,而封闭方案企业的这一比例仅为32%,关键在于,开源生态降低了整个产业链的协同成本。
本月社区服务与儿童教育及餐饮美食热度持续上升,相关产业迎来新机遇 
以新能源汽车电池生产为例,2026年,宁德时代、特斯拉、LG化学等企业联合开源了电池数字孪生压缩模型库,当某车企需要开发新车型的电池管理系统时,可直接调用模型库中的电芯热失控预测模型(该模型已由宁德时代在百万级电芯数据上训练并压缩),仅需微调即可适配自身产线,这种“模型复用”模式使电池管理系统的开发周期从18个月缩短至4个月,成本降低65%。
“这就像工业领域的‘Linux时刻’。”特斯拉数字化副总裁James Wilson比喻道,“当核心模型成为行业基础设施时,企业的竞争力将不再取决于模型本身,而在于如何基于这些模型创造增值服务。”
开源生态的另一个意外收获是促进了模型质量的迭代,2026年11月,西门子MindSphere平台上的一个压缩机数字孪生压缩模型,在开源社区被37个国家的工程师共同优化,其预测精度从92%提升至98.7%,而模型体积反而缩小了15%,这种“众包式优化”模式,使得单个企业难以实现的极端工况覆盖成为可能。
挑战与未来:模型压缩的“阿喀琉斯之踵”
尽管模型压缩技术带来了革命性突破,但2026年的工业实践也暴露出其潜在风险,在为某化工企业部署数字孪生平台时,德国弗劳恩霍夫研究所的团队发现,过度压缩可能导致模型对罕见工况的预测能力下降,当生产线遭遇未在训练数据中出现的原料配比时,压缩模型的预测误差比原始模型高出3倍。
“模型压缩不是‘一刀切’的艺术,而是需要在精度、速度和资源消耗之间找到平衡点。”该研究所首席科学家Dr. Hans Müller警告道,“我们正在开发一种‘自适应压缩’技术,让模型能根据实时工况动态调整压缩率。”

营养膳食与志愿服务活动及绿色防洪抗旱热度持续上升,相关领域迎来新发展 另一个挑战来自安全领域,2026年9月,某汽车零部件供应商的数字孪生平台遭遇黑客攻击,攻击者通过篡改压缩模型中的权重参数,导致生产线上的机械臂发生碰撞事故,这促使行业开始探索“可验证压缩”技术,即在压缩过程中嵌入数学证明,确保模型行为始终在安全边界内。
尽管如此,模型压缩推动的工业数字孪生开源生态已不可逆转,2026年12月,全球工业数字孪生联盟(GIDTA)发布的白皮书预测:到2028年,90%的工业数字孪生项目将采用开源部署方案,而模型压缩技术将成为工业AI的标准配置。
中国企业的角色:从技术追赶到生态共建
在这场全球性的技术变革中,中国企业正从跟随者转变为引领者,2026年7月,阿里云发布的“工业数字孪生压缩工具包”被Gartner评为“年度最具颠覆性技术”,该工具包首次实现了模型压缩与工业协议的自动适配,支持17种主流PLC设备的无缝对接。
更值得关注的是中国企业在标准制定中的话语权提升,2026年11月,由海尔、华为、中科院自动化所等单位牵头制定的《工业数字孪生模型压缩国际标准》在ISO/IEC JTC 1获批立项,这是中国在工业AI领域主导制定的首个国际标准。
“过去我们抱怨国外企业设置技术壁垒,现在该轮到我们定义游戏规则了。”海尔卡奥斯工业互联网平台CTO张维杰说,“模型压缩技术的开源共享,让中国制造业有机会在数字孪生时代实现‘换道超车’。”
2026年的工业数字孪生领域,正上演着一场由模型压缩引发的“静默革命”,当企业不再将模型视为核心机密,当开源社区成为技术创新的主战场,当一棵棵“数字孪生树”连接成覆盖全球的“工业森林”,我们或许正在见证制造业历史上最深刻的一次范式转变——不是通过更强大的机器,而是通过更智能的连接,重新定义生产的本质。