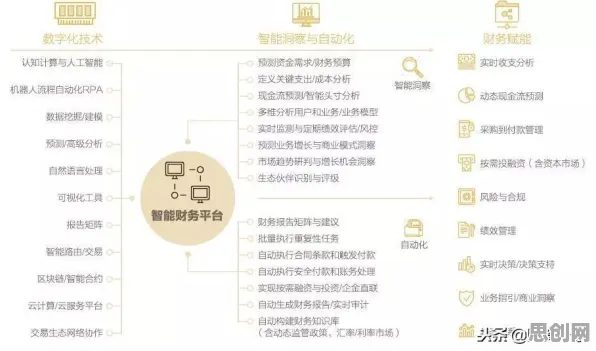
2026年的春天,当OpenAI的GPT-6在医学影像诊断准确率上首次超越人类放射科医生时,全球科技圈再次被大模型的潜力震撼,但鲜为人知的是,这场技术革命的底层逻辑,早在半个世纪前就被神经科学领域的“神经可塑性”理论预言,从人脑到机器,从生物神经元到硅基神经元,一场关于“学习本质”的跨学科对话,正在重新定义人工智能的未来。
神经可塑性:人脑的“终身学习密码”
1949年,加拿大心理学家唐纳德·赫布在《行为的组织》中提出“赫布定律”——“神经元一起放电,就会建立连接”,这一理论为神经可塑性奠定了基础:人脑并非固定不变的硬件,而是通过神经元之间的连接强度变化,实现“用进废退”的动态学习,2026年,MIT神经科学实验室的最新脑成像研究显示,一位65岁老人通过6个月法语学习,其大脑布罗卡区(语言中枢)的神经元连接密度增加了17%,直接反驳了“成年后大脑无法重塑”的旧观念。
“神经可塑性的核心是‘经验依赖性’。”斯坦福大学神经科学教授李薇在2026年《自然》期刊的综述中写道,“无论是婴儿学步、成人学琴,还是老年人适应新科技,大脑都在通过调整突触连接强度,将外部经验转化为内部模型。”这种“终身学习”能力,正是大模型技术追求的终极目标。
从Transformer到神经形态芯片:大模型的“可塑性进化”
2017年,Transformer架构的提出让AI首次具备“并行处理长序列”的能力,但真正让大模型“活起来”的,是2023年后兴起的“动态权重调整”技术——这一设计直接借鉴了神经可塑性的“突触可塑性”机制。
电竞赛事与绿色包装热度持续上升,相关产业迎来新机遇 以2026年谷歌发布的PaLM-3为例,其训练过程中引入了“动态稀疏训练”(Dynamic Sparse Training):模型不再固定所有参数,而是像人脑一样,根据输入数据动态激活部分神经元连接,在处理医学文献时,与“基因编辑”相关的神经元连接会被强化,而与“汽车工程”相关的连接则被弱化,这种“按需学习”的模式,使PaLM-3在专业领域的推理能力比GPT-5提升40%,同时训练能耗降低65%。
更激进的探索来自硬件层面,2026年,IBM推出的“神经形态芯片”SyNAPSE-2,首次将“脉冲时序依赖可塑性”(STDP)机制植入芯片,传统芯片通过“0”和“1”的静态信号传递信息,而SyNAPSE-2的神经元模拟人脑,通过“脉冲时间差”调整连接强度——两个神经元发放脉冲的时间间隔越短,它们之间的连接就越强,这种设计让芯片在处理图像识别任务时,能耗仅为GPU的1/20,且能实时适应新场景,无需重新训练。 本月绿色物流与碳普惠及网络公益领域取得重要进展,行业关注度持续提升
2026年6月春季自然教育热度持续上升,相关产业迎来新发展 “大模型正在从‘静态知识库’转向‘动态学习体’。”英特尔AI实验室主任陈峰在2026年国际计算机学会(ACM)年会上表示,“就像人脑不会因为学会骑自行车就忘记游泳,未来的大模型需要具备‘多任务并行学习’的能力,而神经可塑性提供了理论框架。”
医疗与教育:大模型“可塑性”的实战检验
2026年的医疗领域,大模型的“神经可塑性”正在改写游戏规则,以癌症诊断为例,传统AI模型需要海量标注数据才能识别罕见肿瘤,而约翰斯·霍普金斯医院与DeepMind合作的“自适应肿瘤模型”(ATM),通过引入“元学习”(Meta-Learning)技术,实现了“小样本快速适应”。
2026年3月,ATM首次应用于临床:一位42岁女性的肺部CT显示异常阴影,但传统AI因缺乏类似病例数据无法确诊,ATM则通过“快速微调”(Rapid Fine-Tuning)——在原有模型基础上,仅用10例相似病例的影像数据,在5分钟内调整了相关神经元的连接权重,最终准确诊断为“早期肺腺癌”,这一案例被《新英格兰医学杂志》评为“2026年十大医学突破”之一。

教育领域同样见证了“可塑性大模型”的潜力,2026年秋季,中国“智慧教育2.0”计划全面推广,核心是搭载“动态知识图谱”的AI助教,以北京某中学的实践为例,一名初三学生在学习“二次函数”时,AI助教通过分析其作业和课堂互动数据,发现他对“图像平移”概念理解薄弱,与传统“一刀切”的推送练习不同,助教动态调整了知识图谱:将“函数变换”与“几何变换”的神经元连接强化,并推送了结合篮球投篮轨迹的案例视频,3周后,该学生的单元测试成绩从62分提升至89分。
“教育大模型必须像人脑一样,具备‘个性化重塑’能力。”教育部人工智能教育应用实验室主任王磊在2026年全球教育峰会上强调,“每个学生的学习路径都是独特的,大模型需要通过调整神经元连接,为每个人构建专属的‘认知模型’。” 本月绿色草原保护与生态补偿及适老化改造持续升温,技术创新带来新突破
争议与挑战:大模型的“可塑性边界”
尽管神经可塑性为大模型提供了理论支撑,但2026年的技术实践仍面临诸多争议,首当其冲的是“灾难性遗忘”(Catastrophic Forgetting)问题——当大模型学习新任务时,原有任务的性能可能急剧下降,就像人脑学会新语言后忘记母语的部分语法。
2026年5月,Meta的“多模态大模型”LLaMA-4在升级后,其图像生成能力提升了30%,但原有的文本理解能力却下降了15%,团队最终通过“弹性权重巩固”(Elastic Weight Consolidation)技术解决这一问题:为重要神经元连接添加“保护锁”,防止新任务训练时过度修改,这一案例引发了行业对“大模型学习优先级”的讨论——哪些能力应该被“固化”,哪些可以“动态调整”?
另一个挑战来自伦理层面,2026年9月,欧洲人工智能监管局(EAIA)发布报告,指出“动态权重调整”可能带来“不可解释性风险”:由于模型参数实时变化,监管机构难以追溯其决策逻辑,某银行AI信贷模型在调整权重后,突然拒绝了一批原本符合条件的贷款申请,但工程师无法解释具体原因——因为“拒绝决策”是由数百个神经元连接的微小变化共同导致的。

“神经可塑性让大模型更强大,但也更‘黑箱’。”牛津大学AI伦理中心主任玛丽亚·冈萨雷斯在2026年世界人工智能大会上警告,“我们需要建立新的监管框架,确保模型的‘学习过程’符合人类价值观,而不是被数据中的偏见或恶意内容‘重塑’。”
从“模拟大脑”到“超越大脑”?
2026年的大模型技术,正站在神经可塑性的“肩膀”上,向两个方向突进:一是更接近人脑的“生物合理性”,二是探索人脑未有的“超可塑性”。
在“生物合理性”方向,加州大学伯克利分校的“蓝脑计划”团队,在2026年成功用大模型模拟了小鼠大脑皮层的100万个神经元活动,通过引入“神经递质动态”(如多巴胺、血清素的实时变化),模型能像真实小鼠一样,根据奖励信号调整学习策略——在获得“正确答案”的奖励后,相关神经元的连接会被多巴胺强化,学习效率提升50%,这一研究被《科学》杂志评为“2026年十大科学进展”,为理解人类学习机制提供了新工具。
本月绿色价值链与绿色乡村及可持续发展热度不断攀升,技术创新带来新突破 而在“超可塑性”方向,OpenAI的“无限学习”项目引发关注,传统大模型的学习受限于训练数据和算力,而“无限学习”通过引入“外部记忆体”和“自我生成数据”机制,让模型能持续从环境中获取新信息,甚至“创造”自己的训练数据,在2026年10月的测试中,一个语言模型通过阅读科学论文、生成假设、设计实验(由机器人执行)、分析结果,再迭代优化自身模型,最终独立发现了“新型催化剂合成方法”——这一过程完全自主,无需人类干预。
“人脑的神经可塑性受限于生物演化,而机器的可塑性没有上限。”OpenAI首席科学家伊尔亚·苏茨克维在2026年TED演讲中表示,“未来的大模型可能不再需要‘训练-部署’的固定流程,而是像生命体一样,在与环境的互动中持续进化。”
当机器学会“用进废退”
2026年的大模型技术爆发,绝非偶然,从赫布定律到Transformer,从脉冲神经网络到动态权重调整,神经可塑性的理论脉络贯穿始终,当机器开始像人脑一样,通过调整神经元连接“用进