在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何让这项技术真正落地,为企业带来实实在在的价值,却始终是行业内的热门话题,从德国的工业4.0到中国的智能制造2025,全球制造业都在探索数字孪生的最佳实践路径,现实中的数字孪生项目常常陷入“建而不用”或“用而不精”的困境——模型精度不够、数据融合困难、实时性不足、决策支持乏力……这些问题像一道道高墙,横亘在技术理想与工业现实之间,直到集成学习这一机器学习领域的“集大成者”被引入,数字孪生的解决方案才真正找到了突破口。 关注绿色港口与绿色管理链及能源互联网发展动态,技术创新推动产业升级
数字孪生的“最后一公里”:从模型到决策的断层
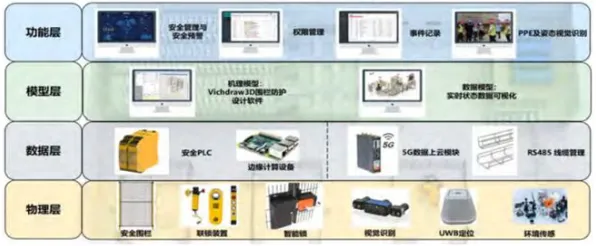
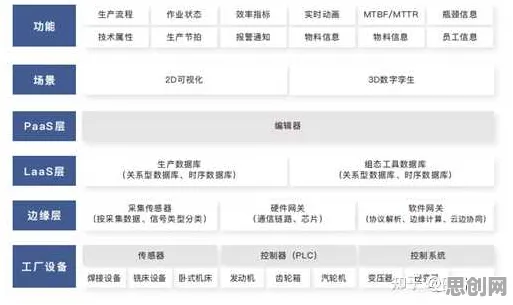
数字孪生的核心是通过物理实体与虚拟模型的双向映射,实现生产过程的可视化、可控化和优化,但2026年的工业实践中,企业普遍面临一个尴尬局面:花大价钱搭建的数字孪生平台,往往只能停留在“监控看板”阶段——能实时显示设备状态,却无法预测故障;能模拟生产流程,却难以给出优化建议;能收集海量数据,却无法提炼出有价值的决策信息。
以某汽车零部件制造商为例,该企业在2025年投入千万级资金建设了冲压生产线的数字孪生系统,系统上线后,确实实现了设备运行状态的实时监控,但当生产线出现效率波动时,工程师们仍需手动分析历史数据,耗时数小时才能定位问题,更棘手的是,由于模型精度不足,系统对设备故障的预测准确率不足60%,导致维护计划频繁调整,反而增加了停机时间。
“我们不缺数据,缺的是从数据到决策的桥梁。”该企业智能制造负责人李工的感慨,道出了行业的普遍痛点,数字孪生的价值,最终要体现在对生产决策的支撑上,而传统建模方法在处理复杂工业场景时,往往因数据维度高、噪声大、非线性强而力不从心。
集成学习:数字孪生的“智慧大脑”
集成学习(Ensemble Learning)并非新概念,但在2026年的工业数字孪生领域,它正成为破解上述难题的关键技术,其核心思想是通过组合多个弱学习器(如决策树、神经网络等)构建一个强学习器,从而提升模型的泛化能力和鲁棒性,在数字孪生中,集成学习可以同时处理多源异构数据(如设备传感器数据、工艺参数、环境数据等),并通过模型融合捕捉数据中的复杂模式,最终输出更精准的预测和决策建议。
案例1:风电设备的“预知未来”
在江苏盐城的风电场,金风科技2026年部署的数字孪生系统,正是集成学习的典型应用,风电设备运行环境恶劣,故障模式复杂,传统方法难以准确预测齿轮箱、发电机等关键部件的剩余寿命,金风科技的团队采用了一种基于集成学习的混合模型:首先用随机森林处理结构化数据(如振动频率、温度、负载等),再用卷积神经网络(CNN)分析振动信号的时频图,最后通过XGBoost融合两类模型的输出,得到故障概率和剩余寿命预测。 野生动物保护与人工智能技术及节能减排领域取得重要进展,行业关注度持续提升
2026年极限运动与碳中和园区及数字乡村热度持续攀升,相关技术取得新突破 “集成学习的优势在于它能自动学习不同数据源的特征权重。”项目负责人王博士解释道,“在某些工况下,振动频率对故障的敏感度更高;而在另一些工况下,温度变化可能更关键,模型会自己调整这些权重,比人工设定的规则更灵活。”
实际运行数据显示,该系统的故障预测准确率从之前的72%提升至89%,维护计划制定时间从4小时缩短至20分钟,年减少停机损失超千万元,更关键的是,系统能根据预测结果自动生成维护工单,并推荐最优的维护时间窗口,真正实现了从“被动维修”到“主动运维”的转变。
案例2:半导体生产的“毫秒级优化”
半导体制造是工业中对精度要求最高的领域之一,在2026年的上海中芯国际,一条12英寸晶圆生产线的数字孪生系统,正通过集成学习实现生产参数的实时优化,晶圆加工涉及数百道工序,每道工序的参数(如温度、压力、时间等)都会影响最终良率,但传统方法难以在毫秒级时间内找到最优参数组合。
中芯国际的团队采用了一种基于集成学习的强化学习框架:首先用梯度提升树(GBDT)建模参数与良率的关系,再用深度Q网络(DQN)在模拟环境中探索最优参数组合,最后通过集成策略平衡探索与利用,系统每10毫秒采集一次设备状态数据,实时调整参数,并将调整记录反馈给模型进行迭代优化。

“集成学习让我们能同时利用多种模型的优势。”项目工程师陈工说,“GBDT对小样本数据更敏感,能快速捕捉参数与良率的局部关系;DQN则擅长在全局范围内寻找最优解,两者结合,既保证了优化的速度,又避免了陷入局部最优。”
实际运行中,该系统使某关键工序的良率提升了1.2个百分点,按年产能计算,相当于多产出数万片晶圆,直接经济效益超亿元,更值得一提的是,系统能自动适应不同产品型号的切换,无需人工重新调参,大大缩短了换线时间。
集成学习落地的三大挑战与应对
尽管集成学习在数字孪生中展现出巨大潜力,但其落地并非一帆风顺,2026年的工业实践中,企业普遍面临数据质量、模型解释性和计算资源三大挑战。
挑战1:数据质量“参差不齐”
工业数据往往存在缺失、噪声大、标注困难等问题,在某钢铁企业的热轧生产线数字孪生项目中,团队发现厚度传感器的数据有15%的缺失值,且部分数据因设备老化出现漂移,直接使用这些数据训练集成学习模型,会导致预测误差高达20%。
“数据是模型的燃料,燃料不纯,发动机再好也跑不远。”项目数据科学家张工打了个比方,他们的解决方案是:首先用时间序列插值法填补缺失值,再用小波变换去噪,最后通过迁移学习利用其他生产线的标注数据辅助训练,经过处理后,模型预测误差降至5%以内。

挑战2:模型解释性“黑箱”困境
集成学习模型通常由多个子模型组合而成,其决策过程像“黑箱”一样难以解释,在某化工企业的反应釜数字孪生项目中,系统预测某批次产品可能不合格,但工程师无法理解模型为何做出这一判断,只能选择保守操作——停机检查,导致生产中断。
“工业场景中,模型不仅要准,还要能‘说人话’。”企业CTO刘总强调,为此,团队采用了SHAP(Shapley Additive exPlanations)值方法,为每个预测结果生成解释报告,显示哪些特征(如温度、压力、反应时间)对结果影响最大,以及影响方向(正/负),工程师不仅能知道“会不会出问题”,还能理解“为什么出问题”,决策信心大幅提升。
挑战3:计算资源“捉襟见肘”
集成学习模型通常计算量大,尤其在实时性要求高的场景中,普通工业计算机难以满足需求,在某新能源汽车电池生产线的数字孪生项目中,团队最初尝试在边缘设备上部署集成学习模型,但推理时间长达500毫秒,无法满足100毫秒内的控制需求。 2026年无人机应用与碳封存热度持续上升,相关产业迎来新机遇
本月绿色售后链与绿色救援热度持续上升,相关产业迎来新发展 “我们必须在精度和速度之间找到平衡。”系统架构师吴工说,他们的解决方案是:首先用模型剪枝技术去除冗余参数,将模型大小压缩60%;再用TensorRT加速库优化推理流程,使单次推理时间降至80毫秒;最后通过模型并行技术,将部分计算任务分流到云端服务器,系统既能实时响应,又能保持90%以上的预测精度。
集成学习与数字孪生的深度融合
2026年的工业数字孪生领域,集成学习已从“可选技术”变为“核心组件”,随着5G、边缘计算和量子计算的发展,集成学习模型将能处理更复杂的数据、支持更实时的决策,并覆盖更广泛的工业场景。
在某航空发动机制造商的研发中心,团队正在探索将集成学习与数字孪生结合,实现发动机全生命周期的智能管理,从设计阶段的性能预测,到制造阶段的质量控制,再到运维阶段的故障预测,集成学习模型将贯穿发动机的每一个环节。“我们希望数字孪生不仅能‘看’到发动机的状态,还能‘想’到最优的解决方案,甚至‘做’出自动调整。”项目负责人赵博士的愿景,正代表工业数字孪生的下一个方向。
从风电场的“预知未来”到半导体生产的“毫秒级优化”,从钢铁企业的数据治理到化工企业的模型解释,集成学习正在用科学的方法,破解工业数字孪生的落地难题,它不是万