2026年的春天,上海数据交易所的交易大厅里,大屏幕上的数字如心跳般跳动——某制造业企业的生产数据包以每秒3.2万元的价格被三家金融机构竞拍,而同一时间,某医疗平台的匿名患者数据正在与药企进行定向谈判,这些看似寻常的交易背后,隐藏着一个被数据科学家称为"学习率调度"的神秘机制,它像一只无形的手,正在重塑中国数据要素市场的底层逻辑。
从"数据孤岛"到"数据洪流":学习率调度的破局之钥
2023年国家数据局成立时,全国数据交易场所超过40家,但年交易额不足500亿元,不及新加坡一个数据交易所的规模,问题出在哪里?某省级大数据局负责人曾无奈表示:"我们建了数据池,却找不到水龙头。"这种困境在2025年出现转机——当学习率调度系统在深圳数据要素市场试点运行时,原本沉寂的政务数据突然"活"了过来。
本月聚焦绿色供应链与健身运动发展新趋势,应用场景不断拓展 以深圳市交通局的数据为例,过去,该部门掌握着全市1200万辆车的出行轨迹,但这些数据被分割在20多个业务系统中,每个系统都有独立的数据标准和访问权限,2025年3月,学习率调度系统接入后,它首先做了一件看似简单却关键的事:给每条数据打上"时间衰减系数",一条3天前的出行记录,其价值权重只有实时数据的1/8,这种动态评估让数据有了"新陈代谢"的能力。
更精妙的是调度算法,当某物流企业申请调用货车轨迹数据时,系统不会直接开放原始数据,而是通过联邦学习框架,在加密状态下计算出货车的平均空驶率,这个过程就像一个智能调酒师——它知道每种原料(数据)的浓度(价值),能根据客户需求(应用场景)调配出最合适的"鸡尾酒"(数据产品),2025年第二季度,深圳物流行业因数据赋能降低空驶率12%,相当于每年减少碳排放24万吨。
医疗数据的"玻璃门":学习率调度的伦理实验
2026年1月,北京协和医院的数据科主任张伟遇到了一个棘手问题:某药企愿意出资1.2亿元购买糖尿病患者的用药记录,但患者隐私保护红线不能碰,这个难题在传统数据交易模式下无解,但在学习率调度系统中找到了突破口。
2026年聚焦兴趣班与智能制造新趋势,应用场景不断拓展 系统采用了一种叫"差分隐私+同态加密"的组合技术,对每条患者记录添加精心设计的噪声(差分隐私),使得单条数据无法被还原;用同态加密技术让药企在加密数据上直接运行分析算法,得到统计结果却看不到原始数据,这个过程就像给数据穿上了一件"防弹衣"——既能抵御攻击,又不影响使用。
更关键的是学习率调度,系统会根据数据敏感度动态调整加密强度:对于年龄、性别等低敏感数据,允许较高的学习率(即算法可以更深入地"学习"数据特征);对于基因序列等高敏感数据,则将学习率压低到极限,这种分级调度让药企最终拿到的,是一份包含"全国糖尿病患者用药模式"的抽象报告,而非任何个体的具体信息。
这个案例产生了连锁反应,2026年第一季度,全国有23家三甲医院采用类似技术开放数据,带动医疗数据交易额突破47亿元,是2025年同期的8倍,更深远的影响在于,它建立了一套可复制的数据脱敏标准——任何企业想交易医疗数据,都必须通过学习率调度系统的"伦理审查"。
金融风控的"水晶球":学习率调度的预测革命
2026年3月,蚂蚁集团的风控总监李芳发现了一个奇怪现象:系统对小微企业贷款违约的预测准确率突然提升了18个百分点,追踪后发现,罪魁祸首竟是学习率调度系统——它悄悄改变了数据融合的方式。

传统风控模型依赖企业征信、税务等结构化数据,但这些数据存在两个致命缺陷:更新滞后(通常按月更新)和覆盖不足(大量小微企业未纳入征信体系),学习率调度系统则引入了"动态学习率"概念:对于实时数据(如水电费缴纳记录、电商交易流水),给予更高的学习权重;对于静态数据(如注册资本、行业分类),则降低权重。
以杭州某服装厂为例,2026年2月,该厂因原材料价格上涨出现短期资金周转困难,传统征信系统显示其负债率上升15%,触发风控预警,但学习率调度系统捕捉到了三个关键信号:过去7天其电商平台的退货率下降了3%,物流发货量增加了12%,且智能电表显示夜间用电量是平时的2.3倍(表明在加班赶单),系统综合这些动态数据后,不仅没有收紧授信,反而主动提供了50万元的临时额度,3个月后,该厂按时还款,并成为蚂蚁集团的优质客户。
这种预测能力的提升正在重塑金融业,2026年第一季度,全国小微企业贷款不良率下降至1.2%,创历史新低,更值得关注的是,学习率调度系统正在推动风控模型从"规则驱动"向"场景驱动"转变——银行可以根据不同行业、不同地区、不同季节动态调整学习率参数,实现真正的"千企千面"风控。
能源数据的"黑匣子":学习率调度的跨界实验
2026年5月,国家电网遭遇了一个前所未有的挑战:随着分布式光伏的普及,传统电力调度系统无法实时处理海量用户侧数据,在江苏,有超过120万户家庭安装了光伏板,每户每天产生约50条运行数据,总数据量相当于每天处理一座大型城市的交通流量。
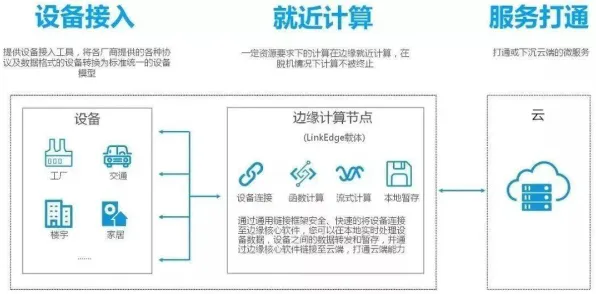
学习率调度系统被引入后,首先做了一件"反直觉"的事:它没有试图收集所有数据,而是通过边缘计算设备在用户端进行初步筛选,对于光伏板的电压波动数据,只有当波动超过阈值时才会上传至云端;对于发电量数据,则按小时汇总上传,这种"懒人调度"策略将数据传输量减少了83%,同时保证了关键信息的完整性。

本月平台治理与医疗健康热度持续上升,相关产业迎来新机遇 更精妙的是跨域学习,系统发现,光伏发电效率不仅与天气相关,还与周边建筑物的阴影分布有关,它自动调用了住建部门的3D城市模型数据,通过计算机视觉算法计算每块光伏板的实际受光面积,这种跨界数据融合让预测准确率提升了27%——电网可以提前6小时预测某区域的光伏出力,误差不超过3%。
这个实验的副产品是催生了一个新的数据市场,2026年第二季度,国家电网将优化后的调度算法封装成数据产品,出售给德国E.ON集团等海外能源企业,单笔交易额超过2000万欧元,这标志着中国数据要素市场开始从"输入型"向"输出型"转变。
数据要素市场的"隐形裁判":学习率调度的治理挑战
当学习率调度系统在各个领域大显身手时,一个新的争议浮现:谁应该掌握学习率的调整权?2026年4月,上海数据交易所发生了一起引发行业震动的纠纷——某电商平台认为交易所对其用户行为数据的学习率设置过低,导致数据产品售价被低估,威胁要退出市场。
这暴露出学习率调度的治理困境,学习率参数主要由数据交易所的技术团队设定,但不同利益相关方对此有截然不同的诉求:数据提供方希望降低学习率(保护数据隐私),数据使用方希望提高学习率(提升数据价值),监管方则希望动态平衡两者。 可持续时尚与储能技术及绿色电力热度持续攀升,相关应用不断深化
深圳数据要素市场率先尝试"三方共治"模式,他们建立了一个由数据提供方、使用方和监管代表组成的"学习率委员会",每月根据市场反馈调整参数,对于医疗数据,委员会将基础学习率设定为0.3(满分1.0),但允许药企在通过伦理审查后,临时提升至0.5进行特定研究,这种机制既保证了数据安全,又释放了数据价值——2026年第二季度,深圳医疗数据交易额环比增长40%,而投诉率下降至0.7%。
2026年无障碍设计与节能减排及绿色销售热度不断攀升,技术创新带来新突破 更深远的影响在于,学习率调度正在推动数据确权制度的创新,每条数据都附带一个"学习率标签",它像价格标签一样明确标示了数据的使用边界,这种技术手段与法律制度的融合,为解决"数据所有权"这个全球性难题提供了中国方案。
未来已来:学习率调度的下一站
站在2026年的门槛回望,学习率调度已经从实验室技术演变为数据要素市场的基础设施,在浙江,政府正在试点"学习率即服务"(LRaaS)模式,企业可以像购买云服务一样,按需调用不同强度的学习率算法;在广东,制造业集群通过共享学习率参数,实现了产业链数据的协同优化;甚至在跨境数据流动领域,学习率调度也成为破解"数据本地化"困境的关键工具——通过动态调整学习率,中国与东盟国家实现了医疗数据的"