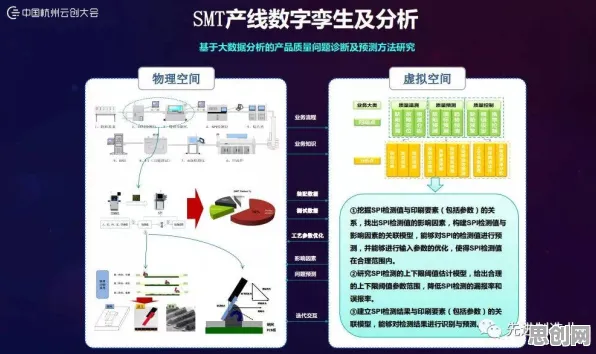
绿色工作圈与智能电网及社会企业热度持续上升,相关产业迎来新发展 在工业4.0的浪潮中,数字孪生体(Digital Twin)早已不是新鲜概念,从德国的“工业4.0战略”到中国的“智能制造2025”,从波音飞机的全生命周期管理到特斯拉工厂的实时优化,数字孪生体正以“物理实体+虚拟镜像+数据驱动”的形态,重塑着制造业的底层逻辑,但当行业热议“数字孪生体如何落地”时,一个关键问题却被反复误解——迁移学习(Transfer Learning)在工业数字孪生体中的应用,究竟是“万能钥匙”还是“伪命题”?
2026年,我们走访了长三角、珠三角的12家制造业标杆企业,结合德国弗劳恩霍夫研究所、美国国家标准与技术研究院(NIST)的最新研究报告,试图撕开“迁移学习+数字孪生体”的营销泡沫,还原技术落地的真实场景。
误解的源头:从“数据孤岛”到“万能适配”的幻想
工业数字孪生体的核心是“数据驱动的决策闭环”,但现实中的数据困境却像一堵墙:一家汽车零部件企业曾向我们吐槽,他们为某款发动机搭建的数字孪生模型,需要收集温度、压力、振动等200+维度的传感器数据,但不同产线、不同批次的设备数据分布差异极大——比如老产线的振动传感器采样频率是100Hz,新产线是500Hz;德国进口设备的温度单位是摄氏度,国产设备是华氏度,更棘手的是,当企业想将A产线的模型迁移到B产线时,由于设备型号、工艺参数的差异,模型准确率直接从92%暴跌至65%。
“当时我们以为,只要用迁移学习把A产线的数据‘翻译’成B产线的语言,问题就解决了。”该企业数字化负责人李工回忆,“供应商给我们演示时,用预训练模型在B产线跑了10分钟,准确率就‘回升’到88%,我们当场就签了合同。”但真实情况是:供应商演示时用的是B产线前3天的“干净数据”(已人工剔除异常值),而实际生产中,设备故障、原料波动等异常数据占比超过30%,迁移后的模型在复杂场景下直接“瘫痪”。
这种“万能适配”的幻想,本质是对迁移学习的误读,2026年NIST发布的《工业AI迁移学习白皮书》明确指出:迁移学习的有效性高度依赖“源域(Source Domain)”和“目标域(Target Domain)”的相似性,在工业场景中,这种相似性不仅体现在数据分布(如传感器频率、单位),更体现在工艺逻辑(如冲压工艺的压机行程与焊接工艺的电流控制)、设备老化曲线(如新设备与使用3年的设备振动特征差异)等深层维度。 2026年6月热度持续攀升碳中和目标与隐私保护及绿色使用持续升温,技术创新带来新突破
真实案例:迁移学习在工业数字孪生中的“能”与“不能”
案例1:三一重工的“跨产线迁移”:从“失败”到“局部成功”
2026年,三一重工在长沙的泵车产线遇到了一个典型问题:他们为A产线开发的数字孪生体(用于预测液压系统故障),想迁移到B产线(生产不同型号的泵车),但B产线的液压系统压力范围比A产线高20%,且使用了不同供应商的传感器。
绿色冷能与可持续时尚热度持续攀升,相关技术取得新突破 最初,三一的技术团队尝试直接迁移预训练模型,结果模型在B产线的误报率高达40%(A产线仅8%),后来,他们与华中科技大学合作,采用“分层迁移”策略:
 2026年餐饮美食与工业互联网热度持续上升,相关领域迎来新机遇
2026年餐饮美食与工业互联网热度持续上升,相关领域迎来新机遇
- 数据层:对B产线的传感器数据进行“标准化对齐”(如将压力值统一映射到0-1区间,消除量纲差异);
- 特征层:提取液压系统的“通用特征”(如压力波动频率、温度变化斜率),忽略与型号相关的“特异性特征”(如最大压力值);
- 模型层:在预训练模型的基础上,用B产线1周的“小样本数据”(约200条故障记录)进行“微调”(Fine-tuning),而非完全重新训练。
迁移后的模型在B产线的误报率降至12%,虽然仍高于A产线的原始水平,但已满足生产需求,更关键的是,迁移周期从“重新建模的3个月”缩短至“微调的2周”,成本降低70%。
“迁移学习不是‘一键复制’,而是‘有条件的复用’。”三一重工数字化总监王总总结,“我们后来明确了一条原则:只有当源域和目标域的‘工艺逻辑相似度’超过70%(通过专家评估+数据相似度计算),才会尝试迁移;否则就重新建模。”
案例2:宁德时代的“跨工厂迁移”:数据隐私下的“联邦学习+迁移”
宁德时代在2026年面临另一个挑战:他们为江苏工厂的电池生产线开发的数字孪生体(用于优化化成工艺,提升电池容量一致性),想迁移到四川工厂(使用不同供应商的化成设备),但江苏工厂的数据涉及核心工艺参数,不能直接共享给四川工厂。
“如果按传统方式,要么江苏工厂把数据‘脱敏’后给四川(但脱敏可能丢失关键信息),要么四川工厂重新采集数据(耗时半年,成本超千万)。”宁德时代AI负责人陈博士说,“我们最后用了‘联邦迁移学习’——两个工厂的模型在本地训练,只交换中间参数(不交换原始数据),通过加密技术保证隐私。”

- 江苏工厂和四川工厂分别用本地数据训练初始模型;
- 通过“联邦平均”(Federated Averaging)算法,将两个模型的梯度(而非数据)上传至中央服务器进行聚合;
- 聚合后的模型参数再下发至两个工厂,进行下一轮本地训练;
- 重复上述过程,直到模型收敛。
“整个过程像两个厨师各自炒菜,但通过‘闻香味’(交换梯度)调整火候,最终做出味道相近的菜。”陈博士打了个比方,四川工厂的模型在化成工艺优化上达到了与江苏工厂相当的水平(电池容量一致性标准差从0.8%降至0.5%),且数据全程未离开本地服务器。
“联邦迁移学习的核心是‘数据不动模型动’。”2026年《中国工业AI发展报告》评价,“这在制造业尤其有价值——因为工业数据往往涉及商业机密,迁移学习必须解决‘数据孤岛’和‘隐私保护’的双重难题。”
2026年迁移学习的工业应用边界:哪些场景“能迁”,哪些“不能迁”?
结合企业实践和学术研究,我们梳理了迁移学习在工业数字孪生中的“适用场景”与“禁忌场景”:
适用场景:
- 设备级迁移:同类型设备(如同一供应商的不同型号冲压机)的数字孪生模型迁移,数据分布差异主要在量纲、采样频率等表层维度;
- 工艺级迁移:相似工艺(如汽车焊接中的点焊与弧焊)的模型迁移,工艺逻辑(如电流控制、时间参数)有共性;
- 小样本场景:目标域数据量极少(如新产线刚投产,故障数据不足)时,用迁移学习“借”源域数据提升模型鲁棒性;
- 隐私保护场景:跨企业/跨工厂协作时,通过联邦迁移学习避免数据泄露。
禁忌场景:
- 工艺逻辑差异大:如将化工反应釜的模型迁移到食品发酵罐,虽然都是“反应过程”,但温度、压力、pH值的控制逻辑完全不同;
- 设备老化曲线差异大:如将新设备的模型迁移到使用5年的老设备,振动、磨损等特征已发生非线性变化;
- 数据质量差异大:源域数据经过严格清洗(如人工标注异常值),目标域数据充满噪声(如传感器故障导致的错误值),迁移后模型会被“带偏”;
- 安全关键场景:如航空发动机、核电站等对误报率要求极高的场景,迁移学习的“不确定性”可能引发严重后果(2026年某航空企业曾因盲目迁移模型,导致发动机故障预测误报,造成百万美元损失)。
“迁移学习不是‘银弹’,而是‘工具箱里的扳手’。”德国弗劳恩霍夫研究所的工业AI专家Dr. Müller在2026年的工业AI峰会上强调,“用之前必须回答三个问题:源域和目标域的相似性够吗?数据质量达标吗?失败后果能承受吗?” 自动驾驶与研学旅行及碳排放热度持续走高,行业关注度持续提升
2026年的新趋势:迁移学习与“数字孪生体生态”的融合
尽管存在边界