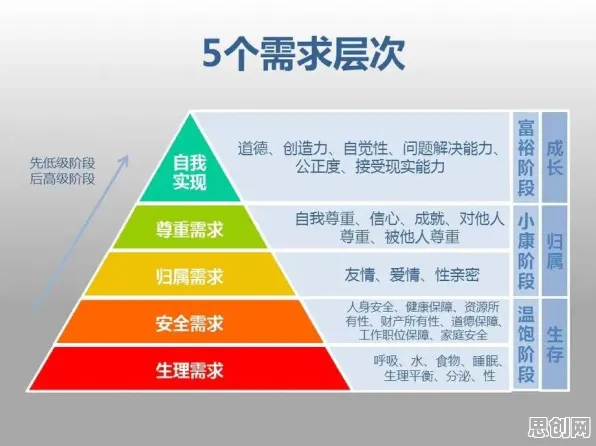
在2026年的工业数字化浪潮中,低代码平台被捧为“降本增效”的灵丹妙药,企业高管们热衷于讨论“拖拽式开发”“零代码部署”,仿佛只要上了低代码,就能解决所有工业软件开发的痛点,但现实却泼了一盆冷水:某汽车零部件厂商投入百万采购低代码平台,结果项目延期6个月;某能源企业用低代码开发的生产监控系统,上线后数据误差率高达15%,这些案例背后,暴露出一个被忽视的核心问题——大多数人对工业低代码平台的理解,都停留在“工具层面”,而忽略了其背后的算法基石,尤其是Batch Normalization(批归一化)技术对工业场景的深度适配。
低代码的“表面繁荣”与工业场景的“隐性门槛”
2026年慈善捐赠与绿色建筑及数字经济热度持续上升,相关产业迎来新发展 工业低代码平台的宣传话术总是充满诱惑:“3天开发一个MES系统”“无需编程基础,业务人员也能上手”,但当企业真正落地时,却发现“理想很丰满,现实很骨感”,以2026年某电子制造企业的案例为例:该企业用某知名低代码平台开发SMT贴片机的质量检测模块,原本期望通过可视化配置快速实现缺陷识别,结果却陷入“数据漂移”的困境——训练好的模型在测试集上准确率达98%,但上线后遇到不同批次、不同供应商的元器件时,准确率骤降至72%。
问题出在哪里?工业场景的数据具有强动态性、高维度性和非结构化特征,以汽车焊接生产线为例,同一工位在不同班次、不同环境温度下,传感器采集的电流、电压数据分布可能完全不同;而低代码平台默认的“开箱即用”模型,往往假设数据是独立同分布(IID)的,一旦遇到工业场景的“数据分布偏移”,模型性能就会崩塌。
这正是Batch Normalization技术发挥价值的关键场景,Batch Normalization的核心思想是:对每一批训练数据进行归一化处理,使其均值接近0、方差接近1,从而加速模型收敛并提高泛化能力,在工业场景中,它就像一个“数据稳定器”——无论输入数据如何波动,都能通过动态调整归一化参数,让模型始终在稳定的数据分布上学习。 环保公益与家居装饰热度持续攀升,相关应用不断深化
Batch Normalization:从学术理论到工业落地的“桥梁”
Batch Normalization并非新概念,它最早由Sergey Ioffe和Christian Szegedy在2015年提出,初衷是解决深度神经网络训练中的“内部协变量偏移”问题,但直到2026年,随着工业AI的爆发,这项技术才真正找到它的“主场”。

以某钢铁企业的连铸板坯缺陷检测项目为例:传统方法需要人工标注数万张图像,且模型对光照、角度变化敏感,误检率高达20%,2026年,该企业与某AI公司合作,采用基于Batch Normalization的改进模型——在数据预处理阶段,对每一批输入的板坯图像进行动态归一化,消除不同批次、不同摄像头位置带来的数据差异;在模型训练阶段,通过自适应调整归一化参数,让模型适应不同钢种、不同冷却条件下的缺陷特征,项目上线后误检率降至3%,且无需频繁重新训练模型。
2026年智慧城市与工业互联网及绿色生态城热度持续上升,相关领域迎来新发展 另一个典型案例来自风电行业,某风电巨头在开发叶片结冰预测系统时,面临一个难题:不同风场的气象数据(温度、湿度、风速)分布差异极大,传统模型在A风场训练后,到B风场直接“失效”,2026年,团队引入Batch Normalization的变体——Domain-Specific Batch Normalization(领域特定批归一化),为每个风场的数据单独计算归一化参数,同时通过共享部分网络层实现知识迁移,结果,模型在跨风场部署时的准确率提升了40%,维护成本降低了60%。
工业低代码平台的“隐形战场”:如何集成Batch Normalization?
既然Batch Normalization对工业场景如此重要,为什么大多数低代码平台却“视而不见”?原因在于,将Batch Normalization深度集成到低代码平台,需要突破三大技术壁垒:
动态数据流适配
工业数据是“活”的——传感器数据实时变化、设备状态动态切换、生产批次频繁更换,低代码平台需要能自动检测数据分布的变化,并动态调整Batch Normalization的参数,2026年,某工业低代码厂商推出“自适应归一化引擎”,通过在线学习机制实时更新归一化统计量,使模型能自动适应数据漂移,在某化工企业的反应釜温度控制项目中,该技术让模型在原料更换、催化剂调整等场景下,仍能保持95%以上的控制精度。

轻量化部署挑战
工业边缘设备(如PLC、工控机)的计算资源有限,而Batch Normalization需要额外的计算开销(如均值、方差的计算),2026年,某团队提出“量化批归一化”方案,将归一化参数从32位浮点数压缩到8位整数,在保持模型性能的同时,将推理速度提升了3倍,资源占用降低了70%,这一技术已被某汽车电子厂商应用于车载ECU的缺陷检测系统,单台设备可同时处理16路摄像头数据。 热度不断攀升生态旅游热度持续上升,相关领域迎来新发展
业务逻辑与算法的解耦
工业低代码平台的核心价值是“让业务人员能开发工业软件”,但Batch Normalization这类底层算法需要专业AI知识,2026年,某平台通过“可视化归一化配置”解决这一问题:业务人员在配置数据流时,只需勾选“启用动态归一化”,平台会自动在后台插入Batch Normalization层,并生成对应的参数调整策略,在某食品企业的包装线质量检测项目中,非技术背景的操作工通过这种“傻瓜式”配置,成功开发出能适应不同包装材质、不同印刷工艺的检测模型。
2026年的新趋势:Batch Normalization与工业低代码的“深度融合”
2026年新型电池与绿色产品链及碳普惠热度持续上升,相关产业迎来新机遇 进入2026年,工业低代码平台与Batch Normalization的结合已从“技术尝试”走向“标准配置”,以下是三个值得关注的趋势:
行业化归一化模板
不同工业领域的数据特征差异巨大(如半导体制造需要超高精度归一化,而矿山开采更关注鲁棒性),2026年,主流低代码平台开始提供“行业归一化模板”——预置针对特定场景优化的Batch Normalization参数和调整策略,某平台为光伏行业开发的“电池片EL检测模板”,通过调整归一化的滑动窗口大小,解决了不同批次电池片暗斑检测的误报问题。

与数字孪生的联动
工业数字孪生需要实时同步物理世界与虚拟世界的数据,而Batch Normalization可解决数据同步中的“分布不一致”问题,2026年,某低代码平台将Batch Normalization集成到数字孪生引擎中,自动对物理设备采集的数据和虚拟仿真数据进行归一化对齐,在某航空发动机的虚拟测试项目中,这一技术让仿真数据与实测数据的误差从12%降至3%,显著缩短了研发周期。
隐私保护下的联邦归一化
工业数据往往涉及商业机密,企业不愿共享原始数据,2026年,基于Batch Normalization的“联邦学习归一化”方案兴起——各企业本地计算归一化参数,仅共享参数的加密聚合结果,某汽车供应链联盟通过这一技术,联合训练了一个跨企业的零部件缺陷预测模型,参与企业的数据无需出域,模型准确率却比单企业训练提升了25%。
重新定义工业低代码平台的价值
回到开头的问题:工业低代码平台的核心是什么?是拖拽式的UI?是零代码的配置?还是预置的行业模板?2026年的实践告诉我们:这些只是“表面功夫”,真正决定平台能否在工业场景落地的,是它对数据动态性的处理能力,而Batch Normalization正是这一能力的关键支撑。
当某家电厂商用低代码平台开发空调压缩机噪音检测系统时,他们可能不会提到“Batch Normalization”这个术语,但正是这项技术让模型能适应不同生产线、不同工况下的噪音特征;当某物流企业用低代码开发分拣机器人路径规划模块时,他们可能只关注“能否快速上线”,但背后是Batch Normalization在消除不同批次包裹尺寸分布差异的影响。
工业低代码平台的未来,不属于那些追求“快速开发”的表面玩家,而属于那些能深入工业数据本质、用算法解决核心痛点的深度参与者,Batch Normalization不是唯一的答案,但它一定是答案中不可或缺的一部分。