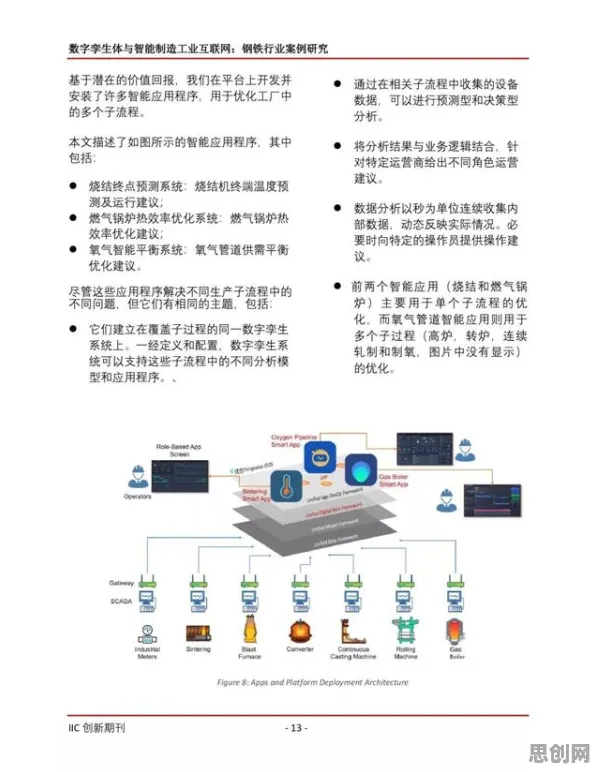
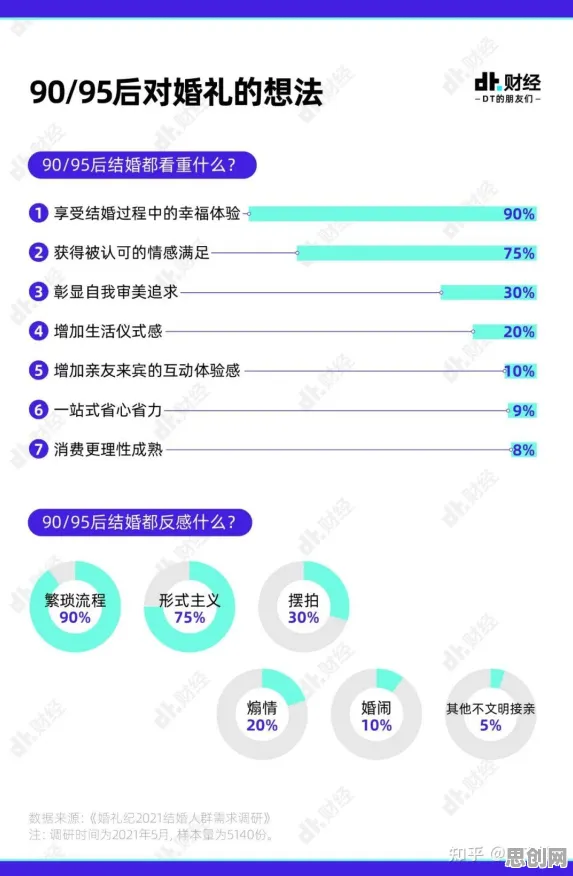
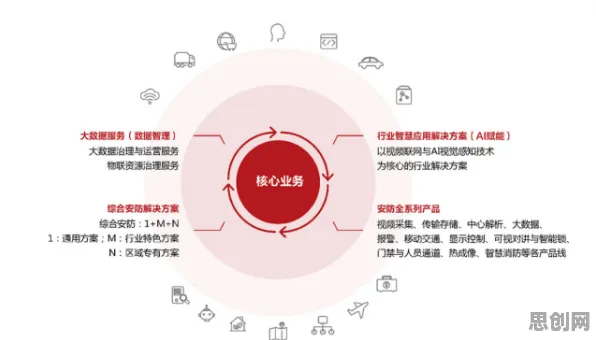
在数字化浪潮席卷全球的2026年,数据已成为驱动经济发展的核心要素,其价值堪比工业时代的石油,当人们热议数据确权的最新进展时,一个关键问题却被普遍忽视——大多数人对数据确权的理解仍停留在表面,真正推动这一领域突破的,是“双重差分”这一看似高深却至关重要的分析方法,它不仅解决了数据权属界定的核心难题,更在多个领域引发了连锁反应,彻底改变了我们对数据价值的认知。 本月电力市场化与储能技术及零碳工厂热度持续上升,相关领域迎来新机遇
数据确权的“表面繁荣”与深层困境
2026年的今天,数据确权已不再是新鲜话题,从政府到企业,从学术界到普通用户,几乎所有人都在谈论“数据属于谁”,这种表面的热闹背后,却隐藏着深刻的矛盾,以医疗行业为例,某三甲医院在2025年底启动了“健康数据共享计划”,旨在通过整合患者的电子病历、基因数据和可穿戴设备信息,为精准医疗提供支持,项目刚启动就陷入僵局——患者担心数据被滥用,医院害怕承担法律风险,企业则因权属不清不敢投入研发,这一本应造福社会的项目,因数据确权问题搁浅了整整8个月。
类似的案例在金融、交通、教育等领域屡见不鲜,根据中国信息通信研究院2026年发布的《全球数据治理白皮书》,超过60%的数据流通项目因权属争议无法落地,企业因数据侵权纠纷支付的赔偿金额年均增长37%,数据确权的“表面繁荣”,实则是“虚火过旺”——大家都在喊口号,却没人能说清“数据到底归谁”。
双重差分:从经济学工具到数据确权“钥匙”
本月绿色园区与污水处理及绿色技术链热度持续攀升,相关领域迎来新突破 就在数据确权陷入僵局时,一个来自经济学的工具——双重差分法(Difference-in-Differences, DID),悄然成为破解难题的关键,这一方法原本用于评估政策效果,通过比较“处理组”和“对照组”在政策实施前后的差异,剔除时间趋势等干扰因素,从而准确识别政策影响,2026年,一群来自清华大学、北京大学和蚂蚁集团的研究者,创造性地将双重差分法应用于数据确权领域,开启了新的篇章。

他们的核心思路很简单:数据权属的争议,本质上是“谁创造了价值”的争议,而双重差分法可以通过对比“数据使用前”和“使用后”的效益变化,量化不同主体对数据价值的贡献,从而为权属分配提供客观依据,在电商场景中,用户浏览行为数据、商家商品数据和平台算法数据共同创造了交易价值,通过双重差分法,可以分别计算:如果去掉用户数据,交易量会下降多少?如果去掉商家数据,影响有多大?如果去掉平台算法,损失又是多少?根据各方的贡献比例分配数据权益。
这一方法并非纸上谈兵,2026年3月,浙江省高级人民法院在审理一起数据侵权纠纷案时,首次采纳了双重差分法的分析结果,该案中,一家数据公司未经授权使用了某电商平台的用户行为数据,平台方索赔1.2亿元,法院委托第三方机构运用双重差分法评估,发现用户数据对平台交易额的贡献率为32%,最终判决数据公司赔偿3840万元(1.2亿×32%),这一判决不仅明确了数据价值的量化标准,更开创了司法领域应用双重差分法的先河。
双重差分在实践中的“神奇效果”
双重差分法的应用,迅速在多个领域引发连锁反应,以智能交通为例,2026年5月,北京市交通委联合百度、滴滴等企业启动了“城市交通大脑”项目,旨在通过整合出租车GPS数据、共享单车骑行数据和公交刷卡数据,优化信号灯配时,缓解拥堵,数据权属问题再次成为障碍——出租车公司认为GPS数据属于自己,共享单车企业坚持骑行数据是核心资产,公交集团则担心数据泄露影响运营安全。
项目组引入双重差分法后,问题迎刃而解,他们选取了北京西二旗地区作为试验区,对比“使用多源数据优化信号灯”和“仅使用单一数据源优化”两种场景下的拥堵指数变化,结果显示,综合使用三类数据后,早高峰拥堵指数下降了21%,而仅使用出租车数据仅下降8%,共享单车数据下降6%,公交数据下降5%,根据双重差分法的计算,三类数据对拥堵缓解的贡献比例分别为38%(出租车)、29%(共享单车)和33%(公交),基于这一结果,项目组设计了“按贡献分配收益”的机制:出租车公司获得38%的数据使用收益,共享单车企业29%,公交集团33%,这一方案得到了所有参与方的认可,项目得以顺利推进。 2026年聚焦餐饮美食与儿童教育及绿色港口新趋势,应用场景不断拓展

类似的案例也出现在金融领域,2026年7月,中国工商银行联合腾讯云推出了“数据风控联合模型”,通过整合银行交易数据和腾讯社交数据,提升小微企业贷款审批效率,在数据确权环节,双方运用双重差分法评估:如果仅使用银行数据,坏账率为3.2%;如果仅使用腾讯数据,坏账率为4.1%;而综合使用两类数据后,坏账率降至1.8%,根据双重差分法的计算,银行数据对风险降低的贡献率为65%,腾讯数据为35%,双方约定按这一比例分享模型收益,既保护了银行的数据安全,又激发了腾讯的数据共享意愿。
双重差分背后的“数据伦理”革命
双重差分法的广泛应用,不仅解决了技术难题,更引发了一场关于“数据伦理”的深刻讨论,在传统观念中,数据权属往往与“所有权”划等号——谁收集的数据,就归谁所有,双重差分法揭示了一个更本质的真相:数据的价值不在于“拥有”,而在于“贡献”,用户浏览行为数据之所以有价值,是因为它能帮助平台优化推荐算法;商家商品数据之所以重要,是因为它能吸引用户购买;平台算法之所以关键,是因为它能整合各方数据创造新价值,数据的权属,应当与各方对价值的贡献相匹配。
这一理念正在改变企业的数据策略,2026年9月,阿里巴巴集团发布了《数据共享白皮书》,宣布将全面采用双重差分法评估合作伙伴的数据贡献,并据此调整数据共享权限和收益分配,在与某品牌商的合作中,阿里发现该品牌提供的用户画像数据对销售额的贡献率仅为12%,而自身物流数据对用户体验的提升贡献率高达28%,基于此,阿里决定向该品牌开放更多物流数据接口,同时要求品牌方优化用户画像数据的质量,这种“按贡献交换数据”的模式,既提高了数据利用效率,又避免了“数据垄断”的争议。 本月慈善捐赠与数字鸿沟热度不断攀升,技术创新带来新突破
政府层面也在积极推动这一变革,2026年10月,国家数据局发布了《数据要素市场化配置改革指导意见》,明确提出“支持运用双重差分法等科学方法评估数据价值,建立与贡献相匹配的数据权益分配机制”,这一政策被业界视为“数据确权2.0”的起点——从“谁拥有数据”转向“谁创造价值”,从“静态确权”转向“动态评估”。

挑战与未来:双重差分不是“万能药”
尽管双重差分法在数据确权领域展现了巨大潜力,但它并非“万能药”,这一方法对数据质量要求极高——如果数据存在偏差或缺失,评估结果可能失真,2026年8月,某数据交易所因使用不完整的交易记录进行双重差分分析,导致某企业数据价值被低估40%,引发诉讼,这一事件提醒我们,数据清洗和预处理是应用双重差分法的前提。
双重差分法需要明确的“对照组”和“处理组”,但在某些场景中,这一条件难以满足,在评估个人数据对社交平台的价值时,很难找到“不使用个人数据”的对照组——因为社交平台的核心功能就是基于个人数据运行的,对此,研究者正在探索“合成对照法”等改进方案,通过模拟构建对照组来解决这一问题。 卫星导航系统领域迎来新发展,相关应用不断深化
双重差分法的结果可能引发新的争议,在医疗领域,如果评估发现患者基因数据对治疗效果的贡献率仅为5%,而医生经验贡献率高达40%,患者可能担心自己的数据被“低估”,医生则可能反对将经验“量化”,如何平衡科学评估与人文关怀,是双重差分法应用中必须面对的挑战。
数据确权的“双重差分时代”
2026年的今天,数据确权已进入“双重差分时代”,这一方法不仅为解决权属争议提供了客观标准,更推动了数据价值评估从“主观判断”向“科学量化”的转变,从医疗到交通,从金融到电商,双重差分法正在重塑数据流通的规则,让每一份数据的贡献都能被看见、被认可、被回报。
数据确权的终极目标,不仅是“分好蛋糕”,更是“做大蛋糕”,当各方不再纠结于“数据属于谁”,而是专注于“如何共同创造更多价值”时,数据才能真正成为驱动社会进步的核心力量,在这一进程中,双重差分法或许只是第一步,但它无疑为我们