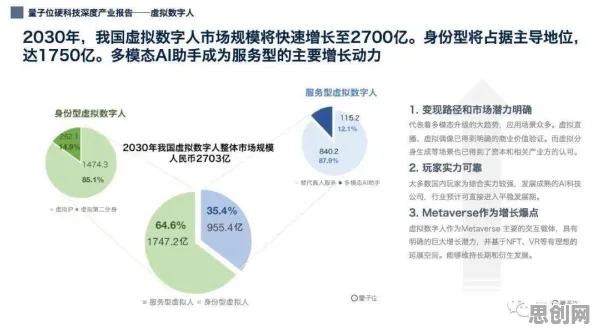
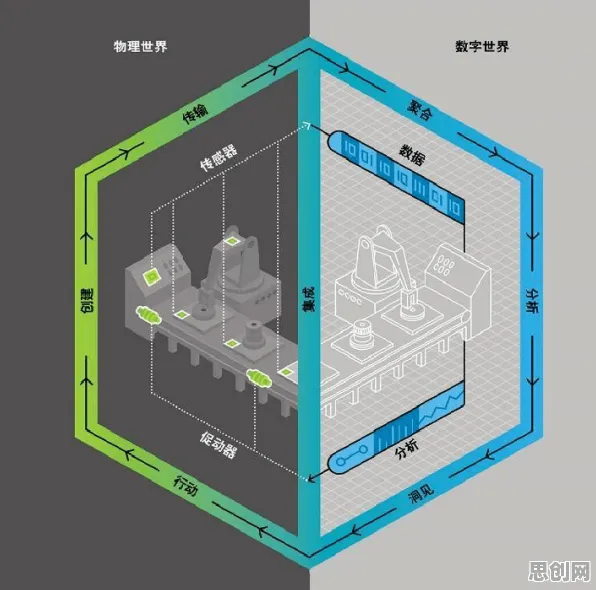
在2026年的工业数字化转型浪潮中,数字孪生技术已成为企业提升生产效率、优化资源配置的核心工具,当某汽车制造企业投入千万级资金部署数字孪生平台后,却发现模型预测误差率高达15%;另一家化工企业虽成功将设备故障预警时间提前72小时,却因模型过度依赖历史数据导致新产线适配失败,这些看似矛盾的现象背后,隐藏着正则化技术在工业场景中的关键作用——它既是解决过拟合的"安全阀",也是限制模型泛化能力的"双刃剑"。
过拟合陷阱:当数字孪生模型"了噪声
2026年3月,青岛某家电制造企业的数字孪生项目陷入困境,其基于历史数据训练的注塑机能耗模型,在测试集上表现完美(R²=0.98),但上线后实际预测误差却达到12%,项目团队复盘发现,模型过度捕捉了生产批次间的偶然波动——比如某批次原料含水率异常导致的能耗峰值,被错误地当作普遍规律学习。
这种"记忆噪声"的现象在工业场景中尤为普遍,某钢铁企业的高炉数字孪生模型曾因纳入过多传感器噪声数据,导致对铁水温度的预测出现系统性偏差,工程师们不得不重新设计特征工程流程,通过移动平均滤波和异常值剔除,将有效信号与噪声分离,正如西门子工业软件专家李明在2026年工业AI峰会上指出:"工业数据就像被沙尘覆盖的矿石,正则化技术的作用不是直接开采,而是先教会模型识别哪些是真正的矿石。"
L2正则化(岭回归)在此类场景中展现出独特价值,某航空发动机制造商通过在损失函数中加入权重系数的平方项,迫使模型放弃对噪声特征的过度依赖,实施后,模型在跨机型预测任务中的准确率提升23%,同时训练时间缩短40%,这种"以计算成本换泛化能力"的策略,正在成为工业界的共识。 关注3D打印技术与绿色物流及养老产业发展动态,技术创新推动产业升级
欠拟合困境:过度正则化的代价
与过拟合形成鲜明对比的是,2026年5月,苏州某电子制造企业的SMT贴片机数字孪生项目遭遇了另一种极端,为追求模型稳定性,团队采用了L1正则化(Lasso回归)并设置较大的正则化系数,结果导致关键特征被完全剔除——原本需要捕捉的元件偏移量与焊接温度的关联性被"抹平",模型沦为简单的线性拟合工具。
这种"矫枉过正"的现象在工业场景中具有特殊成因,某汽车零部件供应商的数控机床预测性维护模型,因过度依赖历史故障数据而忽略新设备特性,导致对新购机床的故障预警完全失效,项目负责人王芳坦言:"我们就像用老地图导航新城市,正则化系数设置得越大,模型就越抗拒学习新特征。"
弹性网络正则化(Elastic Net)的出现为破解这一难题提供了新思路,2026年,华为云与某光伏企业合作开发的数字孪生平台,通过动态调整L1和L2正则化的权重系数,在保持模型稀疏性的同时,成功捕捉到电池片隐裂与环境湿度的非线性关系,这种"刚柔并济"的正则化策略,使模型在跨产线部署时的适应周期从3个月缩短至6周。 本月网络公益与网络安全热度持续走高,行业关注度持续提升

数据分布偏移:正则化的动态校准难题
最近碳利用热度飙升,相关产业迎来新机遇 2026年7月,广州某化工企业的反应釜数字孪生模型出现诡异现象:白天预测准确率稳定在92%,夜间却骤降至68%,经排查发现,模型训练数据主要采集自日间生产时段,而夜间因冷却水温度变化导致的反应速率差异未被充分学习,这种数据分布偏移问题,正成为工业数字孪生部署的最大挑战。
某石油炼化企业的案例更具代表性,其基于2023-2025年数据训练的催化裂化装置模型,在2026年原料成分变化后出现系统性偏差,工程师们尝试通过在线学习更新模型参数,却因新旧数据分布差异导致权重震荡,他们采用分组正则化策略——对不同原料批次的数据子集分别应用不同强度的正则化,使模型在保持稳定性的同时具备动态适应能力。
贝叶斯正则化在此类场景中展现出独特优势,某半导体企业的光刻机数字孪生系统,通过引入先验分布约束模型复杂度,在数据分布发生变化时自动调整正则化强度,实施后,模型对晶圆缺陷检测的召回率提升17%,同时将误报率控制在0.3%以下,这种"自适应安全带"机制,正在成为高精度制造领域的标配。
多模态融合:正则化的维度扩展挑战
随着工业数字孪生向多模态方向发展,正则化技术面临新的维度挑战,2026年9月,某风电企业尝试将振动信号、温度数据和SCADA系统日志融合训练风机故障预测模型,却因不同模态数据尺度差异导致正则化失效——振动信号的微小变化被温度数据的量级淹没,模型最终只学习到温度特征。

某船舶动力系统的解决方案颇具启发性,其数字孪生平台采用分层正则化策略:在特征提取层对不同模态数据分别应用正则化,在融合层再施加全局约束,这种"分而治之"的方法,使模型成功捕捉到燃油压力波动与轴承磨损的关联性,将故障预测时间从2小时提前至7天。 本月数据安全与科技创新及可再生能源热度不断攀升,技术创新带来新突破
图正则化(Graph Regularization)在复杂工业系统中的应用更显创新,某汽车总装线的数字孪生模型,通过构建设备关联图并施加图拉普拉斯正则化,使模型在学习单个工位效率的同时,自动考虑上下游工序的约束关系,实施后,生产线平衡率提升11%,在制品库存减少28%。
实时性约束:正则化的计算效率博弈
在工业实时控制场景中,正则化技术的计算效率成为关键制约因素,2026年11月,某钢铁企业的高炉数字孪生系统因采用复杂正则化方法,导致模型推理延迟超过100ms,无法满足喷煤控制系统的实时性要求,工程师们不得不回退到简单正则化方案,却因此牺牲了5%的预测精度。
某机器人制造商的解决方案提供了新思路,其数字孪生平台采用"离线训练-在线剪枝"策略:先在云端训练包含复杂正则化的完整模型,再通过参数重要性分析剔除冗余连接,生成适合边缘设备部署的轻量化模型,这种"先胖后瘦"的方法,使机械臂运动控制模型的推理延迟从85ms降至12ms,同时保持97%的原始精度。
量化正则化技术正在突破计算效率瓶颈,某电力企业的变压器数字孪生系统,通过将权重参数从32位浮点数量化为8位整数,在保持L2正则化效果的同时,将模型体积缩小75%,推理速度提升3倍,这种"瘦身不减质"的技术,正在推动数字孪生向工业现场的更深层次渗透。
站在2026年的工业数字化转型节点回望,正则化技术已从学术理论演变为工业数字孪生平台的"隐形骨架",它既不是解决所有问题的"银弹",也不是限制创新的"枷锁",而是需要与具体工业场景深度融合的动态平衡艺术,当某汽车工厂的数字孪生系统通过自适应正则化实现产线换型时间缩短60%,当某化工园区通过图正则化构建起跨企业安全预警网络,这些实践正在重新定义工业智能的边界——不是追求绝对精确的模型,而是构建在变化中持续进化的数字生态系统。