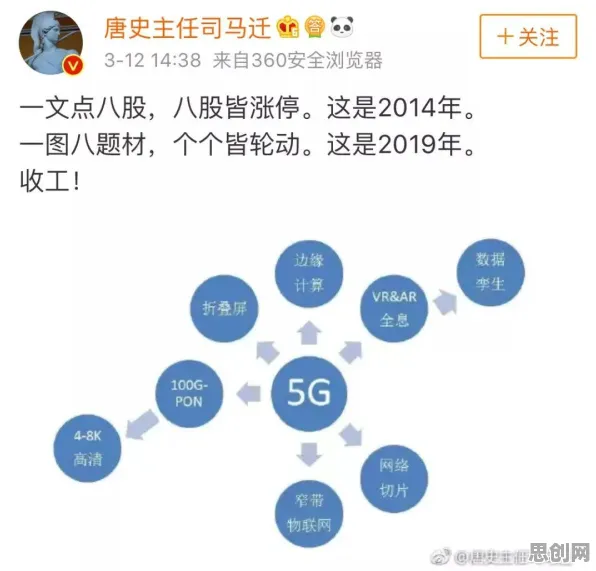
在2026年的工业领域,数字孪生平台已成为推动智能制造、提升生产效率的关键技术,从汽车制造到航空航天,从能源管理到智慧城市,数字孪生技术正以惊人的速度渗透到各个行业,在平台实施过程中,企业常常面临数据融合困难、模型精度不足、实时性要求高等挑战,这些现象的背后,隐藏着与激活函数相似的深层逻辑——如何通过“激活”关键要素,实现系统的最优运行,本文将从激活函数的角度,结合2026年的真实案例,解析工业数字孪生平台实施现象的成因。
激活函数:神经网络中的“决策开关”
在深度学习中,激活函数是神经网络的核心组件之一,它的作用类似于生物神经元中的“阈值效应”——当输入信号超过一定阈值时,神经元被激活,输出信号;否则,神经元保持静默,常见的激活函数如ReLU(修正线性单元)、Sigmoid、Tanh等,各有其独特的数学特性和应用场景。
ReLU函数因其简单高效,在工业场景中应用广泛,它的输出等于输入(当输入大于0时),否则为0,这种“非黑即白”的特性,使得ReLU在处理高维数据时能够快速收敛,减少计算复杂度,在2026年某汽车制造企业的数字孪生平台中,ReLU被用于处理生产线上的传感器数据,通过快速筛选有效信号,实现了对设备故障的实时预警。 本月语言培训与绿色处理及快递物流热度持续上升,相关产业迎来新机遇
Sigmoid函数则因其输出范围在0到1之间,常被用于二分类问题,在工业数字孪生中,Sigmoid可以用于判断设备是否处于正常工作状态,某能源企业利用Sigmoid函数对风力发电机的振动数据进行建模,当输出值超过0.7时,系统自动触发维护流程,有效降低了停机风险。
Tanh函数(双曲正切函数)的输出范围在-1到1之间,适用于需要区分正负信号的场景,在2026年某航空航天企业的数字孪生平台中,Tanh被用于处理飞行器的姿态数据,通过精确区分正负角度变化,实现了对飞行轨迹的精准控制。
数据融合困难:激活函数的“输入失真”
工业数字孪生平台的核心是数据驱动,在实际实施中,企业常常面临数据来源多样、格式不一、质量参差不齐的问题,这类似于激活函数中的“输入失真”——当输入信号包含大量噪声或无效信息时,激活函数无法准确判断是否应该被激活,从而导致模型性能下降。
案例1:某钢铁企业的数据融合困境
2026年,某大型钢铁企业计划构建数字孪生平台,以实现对高炉炼铁过程的实时监控和优化,在数据采集阶段,企业发现来自不同传感器的数据存在严重的不一致性,温度传感器的数据频率为每秒1次,而压力传感器的数据频率为每秒10次,部分传感器因老化或环境干扰,数据存在大量缺失或异常值。

为了解决这一问题,企业采用了数据清洗和插值技术,对原始数据进行预处理,由于数据来源复杂,预处理效果并不理想,企业借鉴激活函数的思路,引入了一种“动态阈值”机制——根据数据的历史分布和实时变化,动态调整激活函数的阈值,从而筛选出有效信号,对于温度数据,系统设定了一个基于历史均值的动态阈值,当实时数据超过该阈值时,才被视为有效信号并输入模型,这一方法显著提高了数据融合的质量,为后续的模型训练提供了可靠基础。
模型精度不足:激活函数的“非线性瓶颈”
工业数字孪生平台的另一个挑战是模型精度,在实际应用中,许多企业发现,即使投入了大量资源进行模型训练,预测结果仍与实际值存在较大偏差,这类似于激活函数中的“非线性瓶颈”——当模型过于简单或激活函数选择不当时,系统无法捕捉数据中的复杂非线性关系,从而导致精度不足。
案例2:某化工企业的模型优化之路
2026年,某化工企业利用数字孪生技术构建了反应釜的虚拟模型,旨在实现对反应过程的精准控制,在初期测试中,企业发现模型的预测误差高达15%,远无法满足生产需求,经过深入分析,企业发现问题的根源在于激活函数的选择——初期模型采用了简单的线性激活函数,无法捕捉反应过程中温度、压力、浓度等多变量之间的非线性关系。
为了解决这一问题,企业尝试了多种非线性激活函数,包括ReLU、Sigmoid和Tanh,通过对比实验,企业发现ReLU在训练速度和收敛性上表现最优,但在处理极端值时存在“死亡神经元”问题(即部分神经元永远无法被激活),为此,企业引入了一种改进的ReLU变体——Leaky ReLU,它在输入为负时赋予一个小的斜率(如0.01),从而避免了神经元死亡的问题。
企业还采用了深度神经网络(DNN)结构,通过增加隐藏层数量,进一步提升了模型的非线性表达能力,经过优化的模型预测误差降至3%以内,显著提高了反应过程的控制精度。

实时性要求高:激活函数的“计算效率”
2026年志愿服务活动与教育公平及超级电容热度持续上升,相关领域迎来新发展 工业数字孪生平台的另一个关键需求是实时性,在许多应用场景中,如设备故障预警、生产调度优化等,系统需要在毫秒级时间内完成数据处理和决策,这类似于激活函数中的“计算效率”——当激活函数的计算复杂度过高时,系统的实时性将受到严重影响。
案例3:某智能电网的实时监控系统
2026年,某城市智能电网项目计划构建数字孪生平台,以实现对电网运行状态的实时监控和故障预警,在初期测试中,企业发现系统的响应时间长达数秒,无法满足实时性要求,经过分析,企业发现问题的根源在于激活函数的选择——初期模型采用了复杂的Sigmoid函数,其指数运算导致计算效率低下。
为了解决这一问题,企业尝试了多种轻量级激活函数,包括ReLU、Swish(一种自门控激活函数)和Mish(一种平滑连续的激活函数),通过对比实验,企业发现ReLU在计算效率上表现最优,但其“死亡神经元”问题在电网数据中尤为突出(因为电网数据包含大量极端值),为此,企业最终选择了Swish函数,它在保持计算效率的同时,通过自门控机制有效缓解了神经元死亡的问题。
企业还采用了模型压缩技术,如量化(将浮点数参数转换为低精度整数)和剪枝(移除不重要的神经元连接),进一步提升了系统的计算效率,经过优化的系统响应时间缩短至毫秒级,实现了对电网故障的实时预警。
多模态数据融合:激活函数的“跨模态激活”
随着工业数字孪生技术的发展,企业越来越需要处理多模态数据——如图像、声音、文本等,这类似于激活函数中的“跨模态激活”——如何设计一种能够同时处理多种类型数据的激活机制,成为提升模型性能的关键。

案例4:某汽车制造企业的多模态质检系统 2026年6月热度不断上升绿色水处理领域迎来新发展,相关应用不断深化
2026年,某汽车制造企业计划构建数字孪生平台,以实现对车身焊接质量的实时检测,传统的检测方法仅依赖单一模态数据(如焊接电流、电压),无法全面捕捉焊接过程中的复杂变化,为此,企业引入了多模态数据融合技术,同时采集焊接过程中的图像、声音和传感器数据。
为了处理这些多模态数据,企业设计了一种“跨模态激活函数”——该函数能够根据不同模态数据的特性,动态调整激活阈值和权重,对于图像数据,系统采用卷积神经网络(CNN)提取特征,并使用ReLU激活函数进行非线性变换;对于声音数据,系统采用循环神经网络(RNN)处理时序信息,并使用Tanh激活函数进行归一化;对于传感器数据,系统则直接使用Leaky ReLU进行激活。
2026年关注绿色处理与空气净化发展动态,技术创新推动产业升级 通过这种跨模态激活机制,系统能够同时捕捉焊接过程中的视觉、听觉和物理变化,从而实现对焊接质量的精准评估,在实际应用中,该系统的检测准确率高达99.5%,显著高于传统单一模态检测方法。
可解释性与鲁棒性:激活函数的“透明化设计”
在工业数字孪生平台中,模型的可解释性和鲁棒性同样至关重要,企业不仅需要知道模型“做了什么”,还需要理解“为什么这么做”——这类似于激活函数中的“透明化设计”——如何设计一种既高效又可解释的激活机制,成为提升模型信任度的关键。
案例5:某医疗设备企业的可解释性模型
2026年,某医疗设备企业计划构建数字孪生平台,以实现对医疗设备运行状态的实时监控和故障预测,由于医疗设备的复杂性和安全性要求,企业需要确保模型的预测结果具有高度的可解释性和鲁棒性,为此,企业采用了一种基于“注意力机制”