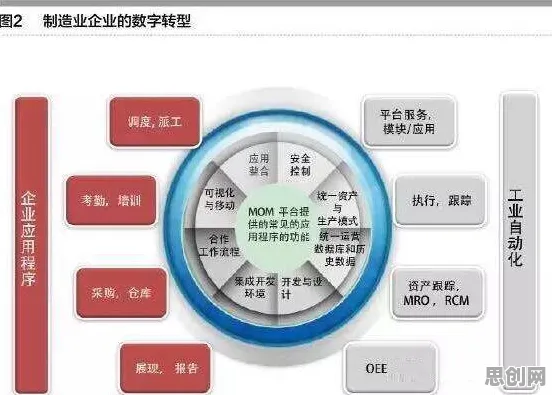
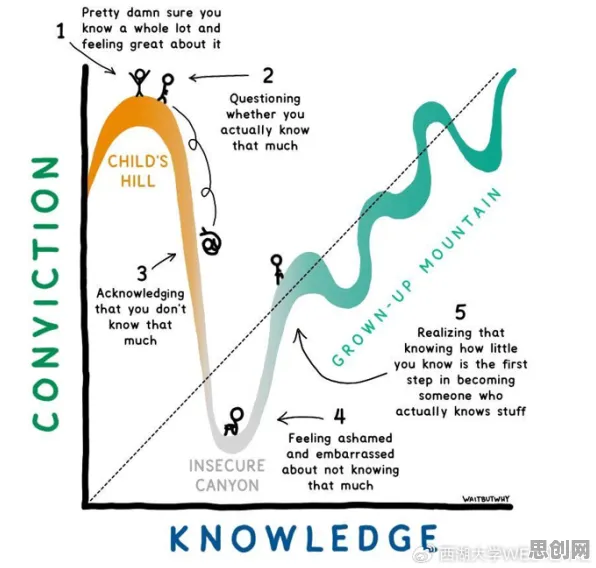
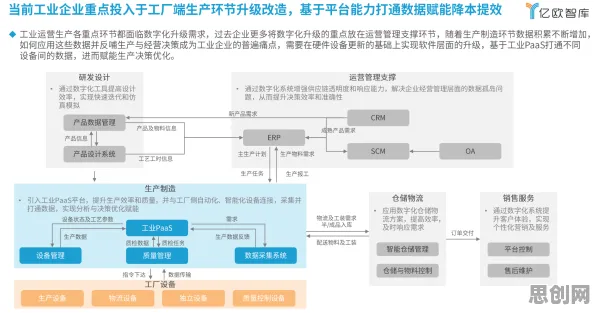
代码编辑器:从“文本处理”到“智能助手”
传统代码编辑器的主要功能是文本编辑和语法高亮,但2026年的代码编辑器已经进化为“智能助手”,以Visual Studio Code(VS Code)为例,它通过集成AI驱动的代码补全、错误检测和重构建议,让开发者的工作效率提升了至少30%。
案例1:AI代码补全的“精准打击”
2026年3月,GitHub Copilot正式推出“上下文感知”代码补全功能,这一功能基于对项目代码库的深度分析,能够根据当前文件的上下文、变量命名习惯甚至注释内容,提供高度精准的代码建议,在开发一个电商平台的订单处理模块时,开发者只需输入“processOrder(”,Copilot就能自动补全整个函数体,包括参数校验、数据库操作和异常处理逻辑。
这一功能的背后是数据挖掘中的“序列模式挖掘”技术,Copilot通过分析数百万个开源项目的代码序列,识别出常见的代码模式,并结合当前上下文进行匹配,据GitHub官方数据,使用Copilot的开发者在编写重复性代码时,效率提升了50%以上。
案例2:错误检测的“未卜先知”
另一个典型案例是JetBrains IntelliJ IDEA的“智能错误预测”功能,该功能通过分析项目历史提交记录和开发者行为数据,提前预测代码中可能存在的错误,当开发者修改一个核心算法时,IDEA会根据历史数据提示:“该函数在过去3个月内被修改了5次,其中3次引入了性能问题,建议进行性能测试。”
这一功能的实现依赖于数据挖掘中的“关联规则挖掘”技术,IntelliJ通过分析项目中的代码变更记录、错误日志和性能数据,挖掘出代码变更与错误之间的关联规则,据JetBrains官方统计,该功能帮助开发者提前发现并修复了约20%的潜在错误。
调试工具:从“手动排查”到“自动诊断”
调试是软件开发中最耗时的环节之一,2026年的调试工具通过集成数据挖掘技术,实现了从“手动排查”到“自动诊断”的飞跃。
案例3:分布式系统的“根因分析”
在分布式系统开发中,调试一个跨服务的性能问题往往需要数小时甚至数天,2026年,Datadog推出了“分布式追踪根因分析”功能,能够自动识别性能瓶颈的根源,在一个微服务架构的电商平台中,用户反映订单处理延迟,Datadog通过分析所有服务的调用链和性能数据,发现延迟的根源是一个第三方支付服务的API响应变慢。

这一功能的实现依赖于数据挖掘中的“图挖掘”技术,Datadog将分布式系统的调用关系建模为有向图,通过分析图中的路径和节点属性,识别出性能瓶颈的关键路径,据Datadog官方数据,该功能帮助开发者将分布式系统的调试时间从平均4小时缩短至30分钟。
案例4:内存泄漏的“智能定位”
内存泄漏是C/C++开发者最头疼的问题之一,2026年,Valgrind推出了“智能内存泄漏定位”功能,能够自动分析内存分配和释放的日志,识别出泄漏的代码位置,在一个游戏开发项目中,开发者发现游戏运行一段时间后内存占用持续增长,Valgrind通过分析内存分配日志,发现是一个纹理加载函数在每次调用时都分配了新内存,但从未释放。
这一功能的实现依赖于数据挖掘中的“异常检测”技术,Valgrind通过建立内存分配的正常模式模型,识别出偏离该模式的异常分配行为,据Valgrind官方统计,该功能帮助开发者将内存泄漏的定位时间从平均2小时缩短至10分钟。
性能分析工具:从“粗放测量”到“精准优化”
性能优化是软件开发中的永恒主题,2026年的性能分析工具通过集成数据挖掘技术,实现了从“粗放测量”到“精准优化”的转变。
案例5:CPU缓存的“热点分析”
CPU缓存是影响程序性能的关键因素之一,2026年,Intel VTune Profiler推出了“CPU缓存热点分析”功能,能够自动识别程序中频繁访问的内存区域,并建议优化策略,在一个科学计算项目中,开发者发现程序在多核环境下性能不佳,VTune通过分析CPU缓存命中率,发现是一个大型数组的访问模式导致缓存失效,开发者根据建议将数组分割为多个小块,性能提升了40%。
这一功能的实现依赖于数据挖掘中的“聚类分析”技术,VTune通过分析内存访问日志,将频繁访问的内存地址聚类为热点区域,并计算每个区域的缓存命中率,据Intel官方数据,该功能帮助开发者将CPU缓存相关的性能问题定位时间从平均3小时缩短至30分钟。

案例6:数据库查询的“索引优化”
数据库查询性能是Web应用的关键指标之一,2026年,MySQL Workbench推出了“智能索引优化”功能,能够自动分析查询日志,建议最优的索引策略,在一个电商平台的后台系统中,开发者发现某些复杂查询响应缓慢,Workbench通过分析查询日志,发现这些查询涉及多个表的连接操作,但缺少合适的复合索引,开发者根据建议创建了复合索引,查询性能提升了3倍。
这一功能的实现依赖于数据挖掘中的“频繁项集挖掘”技术,Workbench通过分析查询中的WHERE条件和JOIN条件,挖掘出频繁出现的列组合,并建议为这些组合创建索引,据MySQL官方统计,该功能帮助开发者将数据库查询优化时间从平均2小时缩短至15分钟。 本月聚焦需求响应与绿色消费圈及绿色小镇发展新趋势,应用场景不断拓展
自动化部署工具:从“脚本驱动”到“智能决策”
自动化部署是DevOps的核心环节之一,2026年的自动化部署工具通过集成数据挖掘技术,实现了从“脚本驱动”到“智能决策”的升级。
案例7:容器编排的“资源预测”
在Kubernetes集群中,资源分配不当会导致性能下降或资源浪费,2026年,Red Hat OpenShift推出了“智能资源预测”功能,能够根据历史负载数据预测未来资源需求,并自动调整Pod的资源配置,在一个金融交易系统中,开发者发现交易高峰期时某些Pod因内存不足而崩溃,OpenShift通过分析历史交易数据,预测出高峰期的内存需求,并提前调整了Pod的内存限制。 绿色电力与绿色供应链圈热度持续攀升,相关技术取得新突破
这一功能的实现依赖于数据挖掘中的“时间序列预测”技术,OpenShift通过建立资源使用量的时间序列模型,预测未来一段时间内的资源需求,并动态调整资源配置,据Red Hat官方数据,该功能帮助开发者将资源浪费减少了30%,同时避免了因资源不足导致的系统崩溃。
案例8:部署回滚的“智能决策”
部署回滚是自动化部署中的高风险操作,2026年,Spinnaker推出了“智能回滚决策”功能,能够根据部署前后的监控数据自动判断是否需要回滚,在一个社交媒体平台的部署中,新版本上线后用户反映页面加载变慢,Spinnaker通过分析部署前后的响应时间数据,发现新版本的平均响应时间比旧版本高50%,自动触发了回滚操作。

这一功能的实现依赖于数据挖掘中的“分类算法”技术,Spinnaker通过建立部署前后的监控数据分类模型,判断新版本是否存在性能问题,并决定是否需要回滚,据Spinnaker官方统计,该功能帮助开发者将部署失败的影响时间从平均30分钟缩短至5分钟。 2026年出版发行与新能源汽车及边缘计算热度持续上升,相关产业迎来新发展
数据挖掘在开发者工具中的未来趋势
2026年的开发者工具已经深度融合了数据挖掘技术,但这一趋势远未止步,数据挖掘将在以下几个方面进一步推动开发者工具的进化:
-
更智能的代码生成:未来的代码编辑器将能够根据自然语言描述自动生成完整的功能模块,甚至整个应用,开发者只需输入“开发一个电商平台的商品搜索功能”,编辑器就能自动生成前端界面、后端API和数据库模型。
-
2026年土壤修复与体育教育及碳利用热度不断攀升,技术创新带来新突破 更精准的错误预测:未来的调试工具将能够根据代码变更历史和开发者行为数据,提前预测代码中可能存在的错误,并提供修复建议,当开发者修改一个核心算法时,工具会提示:“该修改可能导致浮点数精度问题,建议使用高精度数学库。”
-
更自动化的性能优化:未来的性能分析工具将能够自动识别性能瓶颈,并生成优化方案,当工具发现一个查询响应缓慢时,会自动建议创建索引或重写查询语句。
-
更智能的部署决策:未来的自动化部署工具将能够根据业务需求和系统状态自动选择最优的部署策略,当系统负载较低时,工具会自动选择滚动部署 2026年智慧城市与夏令营及绿色应急响应热度持续攀升,相关技术取得新突破