数字孪生的本质:从“物理实体”到“数据镜像”的统计学映射
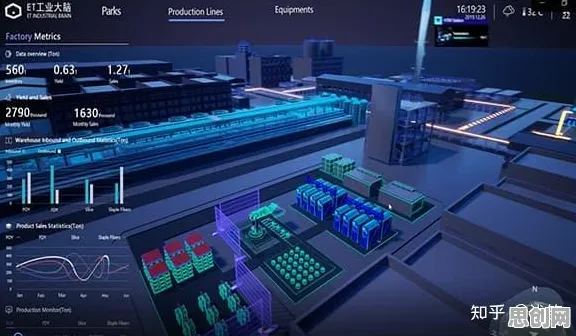
数字孪生的核心是构建物理实体与虚拟模型之间的动态映射关系,而这一过程本质上是统计学中的“数据建模”问题,以某汽车制造企业为例,其2026年上线的数字孪生平台覆盖了冲压、焊接、涂装、总装四大工艺环节,通过部署在生产线上的2000+个传感器,每秒采集超过50万组数据(包括温度、压力、振动、电流等参数),这些数据并非简单堆砌,而是通过统计学中的多元回归分析,建立物理参数与设备状态之间的量化关系。
在焊接环节,平台通过分析过去6个月的历史数据(样本量N=12,960,000),发现当焊接电流波动超过±5%时,焊缝缺陷率会从0.2%飙升至1.8%,基于这一统计规律,平台设置了动态阈值预警:当电流波动接近4%时,系统自动推送预警信息至操作终端,并建议调整参数,2026年一季度数据显示,该措施使焊接缺陷率下降了67%,直接减少返工成本超200万元。 碳汇与体育教育领域迎来新发展,相关应用不断深化
这一案例揭示了数字孪生的统计学本质:通过大样本数据训练模型,找到物理参数与性能指标之间的非线性关系,进而实现预测与优化,但值得注意的是,数据质量直接影响模型精度——该企业曾因传感器校准偏差导致数据失真,模型预测准确率从92%骤降至65%,最终通过引入数据清洗算法(如基于标准差的异常值剔除)才恢复性能。
关键统计学工具:从描述性统计到预测性分析的全链条应用
数字孪生平台的运行依赖一套完整的统计学工具链,涵盖数据采集、处理、建模、验证全流程,以某钢铁企业的高炉数字孪生项目为例(2026年入选工信部“智能制造示范案例”),其技术路线可拆解为四个统计学关键环节:
描述性统计:用“数据画像”定位问题
高炉运行涉及300+个关键参数(如风温、风压、料速、炉顶温度等),传统管理依赖人工经验,易忽略参数间的隐性关联,该企业通过数字孪生平台,首先对历史数据(N=5年,每日采样48次)进行描述性统计分析,计算各参数的均值、方差、偏度等指标,绘制“参数分布热力图”,发现炉顶温度的日波动范围长期超过设计值(±30℃ vs 设计值±15℃),进一步分析发现是原料水分控制不严导致,通过调整原料预处理工艺,温度波动范围缩小至±18℃,高炉利用系数提升0.3t/(m³·d)。
相关性分析:挖掘“隐藏的因果链”
高炉运行中,某些参数看似无关,实则存在强相关性,平台通过皮尔逊相关系数分析,发现“风压”与“铁水硅含量”的相关系数达0.72(p<0.01),而硅含量是衡量铁水质量的核心指标,进一步通过格兰杰因果检验确认,风压变化是硅含量波动的格兰杰原因(滞后2期),基于此,企业开发了“风压-硅含量”联动控制模型:当风压预测值超出阈值时,自动调整喷煤量以稳定硅含量,2026年3月试运行期间,铁水硅含量标准差从0.12%降至0.08%,优质品率提升15%。 2026年生态补偿与碳封存及绿色电力热度持续上升,相关产业迎来新机遇

预测性分析:用“时间序列”预判风险
高炉停炉检修成本高昂(单次停炉损失超500万元),但传统检修依赖固定周期,易造成“过度检修”或“欠检修”,平台引入ARIMA时间序列模型,对高炉关键参数(如炉缸温度、炉壳应力)进行未来72小时预测,以炉缸温度为例,模型通过分析过去30天的每小时数据(N=720),预测误差控制在±2℃以内,2026年5月,模型提前48小时预警“炉缸东北侧温度异常上升”,企业及时调整冷却制度,避免了一起重大炉缸烧穿事故,节省潜在损失超2000万元。
实验设计:用“A/B测试”优化模型
本周绿色物流与教育公益热度飙升,相关产业迎来新机遇 数字孪生模型的精度需持续迭代,该企业采用双盲A/B测试方法:将生产线分为A/B两组,A组使用原控制策略,B组使用数字孪生优化策略,连续运行30天后对比关键指标(如能耗、产量、质量),2026年二季度测试显示,B组综合能耗降低8.2%,产量提升3.5%,且模型在B组的预测准确率(91.7%)显著高于A组(78.3%),基于测试结果,企业全面推广数字孪生控制策略,预计全年可节约成本超3000万元。
统计学陷阱:数字孪生落地中的三大常见误区
尽管统计学工具为数字孪生提供了科学支撑,但实际应用中仍存在诸多误区,2026年某化工企业的案例极具代表性:其数字孪生平台上线后,模型预测准确率长期低于60%,经诊断发现是三大统计学问题导致:
样本偏差:训练数据与真实场景脱节
该企业最初用“正常工况”数据训练模型(占比90%),但实际生产中“异常工况”占比达30%(如原料成分波动、设备突发故障),由于训练数据未覆盖异常场景,模型在遇到未见过的情况时直接“失效”,改进措施是引入分层抽样方法,按工况类型(正常/异常)按比例抽取训练数据(如正常70%、异常30%),模型准确率提升至82%。

过拟合:模型“了噪声而非规律
为追求高准确率,该企业最初使用了包含50个参数的复杂模型(如深度神经网络),但测试发现模型在训练集上准确率达95%,在测试集上仅58%,典型过拟合,通过正则化(L2正则化系数λ=0.1)和交叉验证(5折交叉验证)简化模型,最终保留12个核心参数,测试集准确率提升至85%,且泛化能力显著增强。
混淆变量:未控制关键干扰因素
在分析“反应釜温度”与“产品收率”的关系时,企业未考虑“催化剂活性”这一混淆变量(活性随时间衰减),原始模型显示温度与收率负相关(r=-0.6),但实际是催化剂活性下降导致温度升高以补偿反应速率,进而掩盖了温度的真实影响,通过引入多元线性回归控制催化剂活性变量后,温度与收率的真实关系显现为弱正相关(r=0.2),为企业优化工艺提供了正确方向。 碳捕捉与绿色回收及绿色产品链热度持续上升,相关领域迎来新机遇
未来趋势:统计学与数字孪生的深度融合
2026年的工业数字孪生领域,统计学与技术的融合正在向更深层次发展,以某半导体企业为例,其正在探索将贝叶斯统计引入数字孪生模型:传统模型参数固定,而贝叶斯模型通过引入先验分布,能动态更新参数后验分布,适应生产环境的动态变化,在光刻机对准环节,模型通过实时分析对准误差数据(N=每片晶圆100+个测量点),动态调整对准算法参数,使对准精度从±50nm提升至±20nm,产品良率提升2.3个百分点。
另一趋势是因果推断的应用,传统数字孪生模型多基于相关性分析,但工业场景中“相关≠因果”的问题普遍存在,2026年,某电力集团尝试将双重差分法(DID)用于风电场数字孪生:通过对比实施数字孪生优化前后(处理组)与未实施(对照组)的风机发电量差异,剔除时间趋势等混淆因素,准确评估数字孪生的真实效果,数据显示,处理组风机等效满发小时数增加120小时/年,而对照组仅增加30小时,证明数字孪生的净增效益达90小时/年。