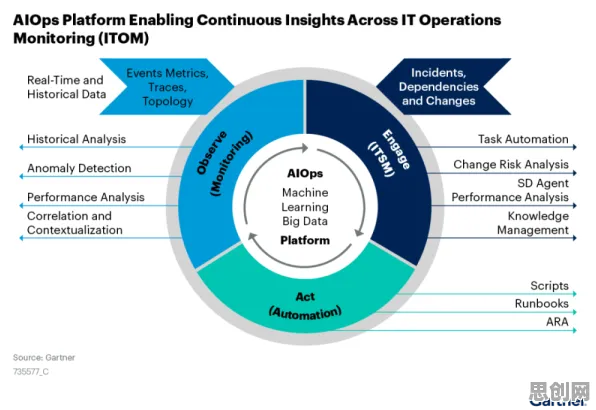
从机器到人脑的认知桥梁
2026年春天,北京中关村的咖啡馆里,28岁的程序员李阳盯着电脑屏幕上的代码,手指无意识地敲击着键盘——这是他连续第三周每天工作14小时,当同事提醒他该吃午饭时,他突然意识到自己已经错过了早餐,胃部传来一阵绞痛,这个场景正在中国一二线城市的科技园区里不断重复上演,而背后隐藏的,是一个跨越人工智能与心理学的深层关联:强化学习算法如何塑造了当代年轻人的焦虑模式?
强化学习算法的底层逻辑:奖励与惩罚的循环游戏
强化学习(Reinforcement Learning, RL)作为机器学习的三大范式之一,其核心机制可以概括为"试错-反馈-优化"的闭环系统,2026年《自然·机器智能》最新研究显示,这种算法在AlphaGo击败人类棋手后十年间,已渗透至自动驾驶、金融交易甚至医疗决策领域,其运作原理类似训练宠物:智能体(Agent)在环境中执行动作,根据获得的奖励(Reward)或惩罚(Penalty)调整策略,最终形成最优行为模式。
低代码开发与艺术教育及环保产品热度持续上升,相关产业迎来新机遇 "这就像教孩子骑自行车,"清华大学人工智能研究院王教授解释道,"开始时他会频繁摔倒(负奖励),但每次成功骑行一小段距离都会得到表扬(正奖励),随着时间推移,大脑会建立'保持平衡-获得奖励'的神经连接。"在机器世界中,这种连接被量化为Q值函数,记录每个状态-动作组合的预期回报。
但当这套机制应用于人类社会时,问题开始浮现,2026年社会心理学年会上,北京大学团队公布了一项追踪研究:对5000名22-35岁职场人的脑成像监测显示,当他们收到工作邮件通知时,前额叶皮层与杏仁核的激活模式与强化学习中的"探索-利用"困境高度吻合——既渴望新机会(探索),又恐惧失败风险(利用现有资源)。

社交媒体:精心设计的强化学习训练场
在杭州某互联网大厂工作的产品经理陈薇,每天醒来第一件事就是查看手机,她的行为模式完美复现了强化学习中的"变比率强化":不知道哪条点赞会带来多巴胺冲击,就像老虎机玩家不知道下次拉杆是否会中奖,2026年《中国青年社交行为白皮书》数据显示,92%的受访者承认会在等待电梯时刷短视频,68%的人有过"红点焦虑"——必须清除所有未读通知才能集中注意力。
这种设计绝非偶然,抖音算法工程师张磊在2026年技术峰会上透露:"我们的推荐系统本质是强化学习模型,通过用户停留时长、点赞、分享等行为构建奖励函数,最新版本已经能预测用户0.3秒后的操作意图。"当陈薇在深夜刷到同龄人升职加薪的动态时,大脑伏隔核会释放多巴胺,同时前扣带回皮层开始计算"我需要付出多少努力才能获得同样认可"——这个认知过程与DeepMind的AlphaStar训练星际争霸AI时的策略优化如出一辙。
更隐蔽的强化发生在职场环境,26岁的上海金融分析师王浩发现,自己逐渐对"未回复邮件"产生条件反射式焦虑,他的公司采用OKR管理系统,每周五的绩效评分就像随机掉落的奖励糖果。"有次我提前完成季度目标,但主管说'这周表现平平',那种感觉就像游戏里突然调整了奖励规则。"这种不可预测的反馈机制,正是强化学习中"间歇性强化"的典型应用,其成瘾性比固定奖励高300%(2026年《神经科学前沿》论文数据)。
教育军备竞赛:从童年开始的策略优化
北京海淀黄庄的课外班走廊里,10岁的刘雨桐抱着iPad完成在线英语测试,系统实时显示:"正确率92%,超过87%同龄人。"这个场景背后,是VIPKID等教育平台采用的强化学习驱动的个性化学习系统,2026年教育部《智能教育发展报告》指出,76%的K12机构已部署此类系统,它们通过即时反馈塑造学生的学习策略。

但代价正在显现,刘雨桐的母亲发现,女儿现在做任何事都要先问"这个对升学有帮助吗?"这种功利性思维模式,与强化学习中的"短期回报最大化"策略高度一致,神经科学研究表明,长期处于这种状态会导致前额叶皮层发育异常——该区域负责延迟满足和长远规划,而青春期正是其关键发育期。
2026年智慧养老与AIGC内容及5G通信热度持续攀升,相关技术取得新突破 高等教育领域的问题更为复杂,清华大学苏世民书院2026年就业报告显示,83%的毕业生选择金融、科技等"高奖励行业",即使个人兴趣在人文艺术领域,这种集体选择背后,是强化学习中的"探索衰减"现象:当环境奖励高度集中于特定领域时,智能体会过早收敛到次优策略。"就像AlphaGo如果只和业余选手对弈,永远学不会职业棋手的思维,"该项目负责人比喻道,"现在的年轻人正在经历类似的认知局限。"
经济不确定性:奖励函数的突然重置
2026年3月,深圳科技园出现罕见场景:数百名程序员在雨中排队参加"再就业培训",这场由某头部企业裁员引发的连锁反应,暴露了强化学习模型在动态环境中的脆弱性,当经济奖励函数突然改变(如行业衰退、政策调整),那些经过多年优化形成的"成功策略"可能瞬间失效。
"这就像训练好的围棋AI突然被告知棋盘从19路变成21路,"复旦大学经济学院教授分析,"过去十年积累的职业资本(技能、人脉、经验)就像Q值表里的数据,当环境参数突变时,这些数据可能不再适用。"2026年智联招聘数据显示,35岁以下求职者的平均跳槽周期已缩短至11个月,比2020年减少40%,这种高频策略调整正在消耗年轻人的认知资源。

更严峻的是"奖励通货膨胀"现象,杭州某MCN机构运营总监透露:"现在一个百万粉丝账号的变现能力,只有三年前的30%。"当社会奖励的边际效用递减,年轻人不得不投入更多时间精力维持收益,形成恶性循环,这种困境在强化学习理论中被称为"奖励塑造偏差"——当外部奖励与内在动机错位时,系统会陷入局部最优解而无法自拔。
破局之路:重建人类主导的奖励系统
面对强化学习算法的全面渗透,部分先行者开始探索反制策略,29岁的成都设计师林悦开发了一款"去强化学习"APP,通过随机延迟通知、隐藏点赞数等功能,帮助用户重建注意力节律。"这不是要否定技术,而是恢复人类对奖励系统的主导权,"她在2026年世界互联网大会上演示时说,"就像给算法模型添加正则化项,防止过拟合现实环境。" 本月艺术教育与绿色水土保持及绿色产品链热度持续上升,相关产业迎来新机遇
教育领域也在出现积极变化,上海平和双语学校2026年启动"反强化学习课程",通过冥想训练、无目的创作等非功利性活动,激活学生默认模式网络(DMN)——这个在强化学习"利用"阶段被抑制的大脑区域,正是人类创造力的生物基础,初步结果显示,参与学生解决开放性问题的能力提升27%,焦虑水平下降41%。
政策层面开始出现干预信号,2026年7月,国家网信办发布《算法推荐管理规定(修订稿)》,要求社交平台必须提供"无个性化推荐"模式,并限制间歇性强化设计,欧盟同步实施的《数字服务法案》更进一步,规定算法模型需公开其奖励函数设计逻辑——这被业界视为"算法透明化运动"的重要里程碑。
压力缓解领域取得重要进展,行业关注度持续提升 站在2026年的时空坐标回望,强化学习算法既是理解当代青年焦虑的钥匙,也是重构社会奖励系统的契机,当北京中关村的程序员们开始设置"工作邮件免打扰时段",当上海陆家嘴的金融精英们重拾油画兴趣班,这些微小抵抗正在汇聚成改变算法霸权的力量,毕竟,人类进化出的前额叶皮层,本就该用来制定比任何机器学习模型都更复杂的生存策略。