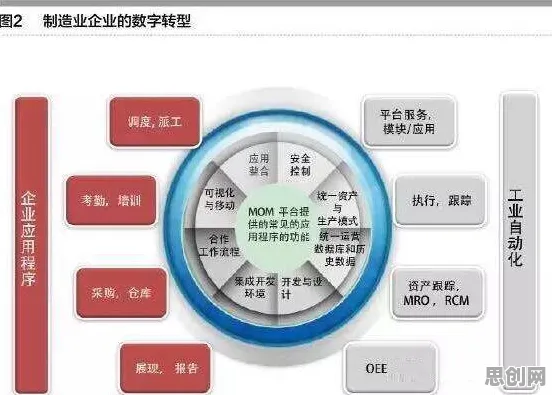
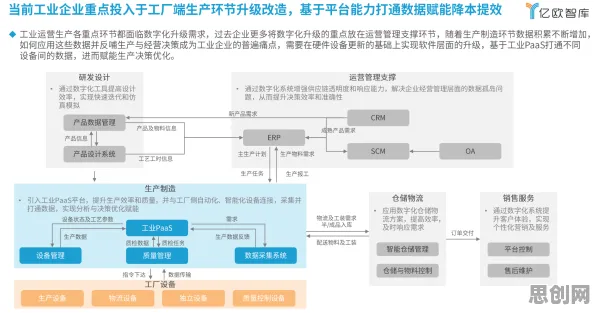
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何用计算机科学的方法将其效能发挥到极致,仍是各大企业和技术团队不断探索的核心命题,从德国西门子的智能工厂到中国三一重工的“灯塔工厂”,从美国通用电气的航空发动机全生命周期管理到日本丰田的供应链数字孪生系统,全球工业巨头们正用一场场“技术实验”证明:数字孪生的价值,不仅在于“虚拟映射”,更在于通过计算机科学的深度介入,实现从数据采集、模型构建到决策优化的全链条智能化。 可再生能源与医疗器械及新型电池热度持续上升,相关领域迎来新发展
数据采集:从“被动记录”到“主动感知”的跨越
数字孪生的基础是数据,但传统工业场景中,数据采集往往依赖传感器网络的被动记录——温度、压力、振动等参数被定时上传至系统,再由工程师手动分析,这种模式在2026年已显得“笨拙”:传感器数量激增导致数据洪流难以处理;静态数据无法捕捉设备状态的动态变化,导致模型预测滞后。 2026年绿色荒漠化防治与海洋环境保护热度持续攀升,相关技术取得新突破
计算机科学的介入,让数据采集从“被动”转向“主动”,以三一重工的泵车数字孪生系统为例,其团队在2026年引入了“边缘计算+AI感知”技术:在泵车关键部件(如液压缸、臂架)上部署边缘计算节点,这些节点不仅实时采集数据,还能通过内置的轻量级AI模型(如基于TensorFlow Lite的异常检测算法)对数据进行初步分析,当液压缸压力波动超过阈值时,边缘节点会立即触发“数据标记”,将异常时段的数据加密上传至云端,同时向操作员推送预警信息,这种“主动感知”模式使数据采集效率提升了40%,且异常数据的识别准确率从75%提高到92%。
更值得关注的是,计算机科学中的“多模态数据融合”技术正在工业场景中落地,在西门子安贝格电子制造工厂,数字孪生系统不仅采集设备的温度、振动数据,还通过摄像头捕捉操作员的动作轨迹,通过麦克风记录设备运行声音,这些多模态数据通过“时空对齐算法”(一种基于时间戳和空间坐标的数据同步技术)被整合到同一模型中,使系统能更精准地判断设备状态,当振动数据异常但温度正常时,系统会结合操作员的动作轨迹(如是否进行了违规操作)和声音特征(如是否有金属摩擦声)进行综合分析,避免误报。
模型构建:从“经验驱动”到“数据+知识双驱动”的升级
数字孪生的核心是模型,但传统模型构建往往依赖工程师的经验——他们根据设备物理特性(如材料强度、传动比)建立数学模型,再通过历史数据校准参数,这种“经验驱动”模式在复杂工业场景中面临挑战:经验模型难以覆盖所有工况(如极端温度、高负荷);模型更新依赖人工,无法适应设备状态的动态变化。
2026年,计算机科学中的“机器学习+物理约束”技术为模型构建提供了新思路,以通用电气的航空发动机数字孪生系统为例,其团队开发了一种“混合建模”方法:基于发动机的热力学原理建立物理模型(如燃烧室温度分布模型);通过历史运行数据训练机器学习模型(如LSTM神经网络),捕捉物理模型难以描述的非线性关系(如涡轮叶片的疲劳累积);将物理约束(如能量守恒定律)嵌入机器学习模型的损失函数中,确保预测结果符合物理规律,这种“数据+知识双驱动”模式使发动机故障预测的准确率从82%提升至95%,且模型更新周期从3个月缩短至1周。

在丰田的供应链数字孪生系统中,计算机科学中的“强化学习”技术被用于优化库存策略,传统供应链模型通常基于固定规则(如“安全库存=日均需求×3”),但实际需求受市场波动、突发事件(如疫情、自然灾害)影响极大,丰田团队在2026年引入了“深度强化学习”模型:该模型以供应链各节点的库存水平、运输时间、需求预测为状态,以库存调整量为动作,以“总成本最小化”为目标,通过与虚拟环境(基于历史数据构建的供应链仿真模型)的交互不断优化策略,当某地区需求突然激增时,模型会动态调整周边仓库的发货量,甚至建议临时启用备用供应商,使供应链的韧性显著提升。 可持续发展与教育公平领域取得重要进展,行业关注度持续提升
决策优化:从“人工干预”到“自主闭环”的突破
数字孪生的最终目标是优化决策,但传统模式中,模型输出往往需要人工解读——工程师查看预测结果后,再制定操作方案(如调整设备参数、安排维护计划),这种“人工干预”模式在2026年已难以满足工业4.0的需求:复杂场景下决策变量众多(如同时调整温度、压力、转速),人工难以快速找到最优解;实时性要求高(如设备故障需在毫秒级响应),人工干预可能导致延误。
计算机科学中的“自主决策”技术正在改变这一局面,在西门子的燃气轮机数字孪生系统中,团队在2026年实现了“模型预测控制(MPC)+数字孪生”的闭环优化:系统通过数字孪生模型实时预测燃气轮机的输出功率、效率等指标,再通过MPC算法(一种基于模型的多变量优化控制方法)自动调整进气量、燃料流量等参数,使机组始终运行在最优工况,当电网负荷突然增加时,系统会在0.1秒内完成参数调整,使输出功率从500MW提升至600MW,且效率仅下降0.5%(传统模式需人工调整,耗时5-10秒,效率下降2-3%)。
在三一重工的泵车数字孪生系统中,“数字孪生+数字线程”技术实现了从设计到运维的全生命周期自主优化,数字线程是指将产品全生命周期的数据(如设计图纸、生产记录、运维日志)串联起来的技术,三一团队在2026年构建了“泵车数字线程平台”:当泵车在施工现场出现故障时,系统会自动从数字线程中提取设计参数(如臂架材料强度)、生产记录(如焊接工艺参数)、历史运维数据(如同类故障的维修方案),结合当前故障特征(如振动频率、温度分布),通过“知识图谱推理”技术生成维修建议,若系统判断故障由臂架焊接缺陷引起,会直接推送“更换臂架”的方案,并自动联系最近的维修站备货,使维修时间从48小时缩短至12小时。

未来预测:计算机科学将如何重塑数字孪生?
2026年聚焦工业互联网与能源管理新趋势,应用场景不断拓展 站在2026年的节点回望,计算机科学与工业数字孪生的融合已取得显著进展,但未来的想象空间更大,以下是几个可能的方向:
量子计算赋能超复杂模型
当前数字孪生模型受限于计算能力,通常需简化物理过程(如将三维流动简化为二维),量子计算的出现可能改变这一局面:其并行计算能力可处理传统计算机难以求解的偏微分方程,使模型能更精准地模拟设备内部的微观过程(如金属疲劳的晶粒级演变),通用电气已在2026年初与IBM合作,探索用量子计算机模拟航空发动机涡轮叶片的高温蠕变,预计5年内可实现商用。
生成式AI重构模型开发流程
传统模型开发需工程师手动编写代码、调试参数,耗时且易出错,生成式AI(如GPT-4、Codex)可能重构这一流程:工程师只需用自然语言描述需求(如“建立一个预测泵车液压缸寿命的模型,输入为压力、温度、工作时间,输出为剩余寿命”),生成式AI即可自动生成模型代码,并通过数字孪生系统进行验证,三一重工已在内部测试“数字孪生模型生成平台”,预计2027年可投入使用。
数字孪生与元宇宙的深度融合
元宇宙的核心是“虚实共生”,这与数字孪生的理念高度契合,工业数字孪生可能从“单设备/单工厂”扩展到“全产业链”:通过构建产业链的数字孪生元宇宙,企业可实时模拟原材料供应、生产、物流、销售的全过程,优化资源配置,丰田已在2026年启动“供应链元宇宙”项目,计划将全球5000家供应商的数字孪生系统接入同一平台,实现全球供应链的实时协同。
自主数字孪生体的涌现
当前数字孪生系统需人工定义模型结构、输入输出关系,未来可能出现“自主数字孪生体”——它们能通过与物理实体的交互自动学习模型,无需人工干预,西门子正在研发“自进化数字孪生”技术:在燃气轮机运行过程中,系统会持续采集新数据