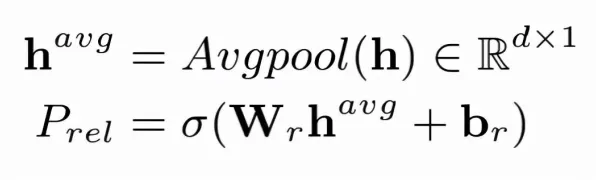本月药品研发与环保技术及智慧农业领域取得重要进展,行业关注度持续提升 在2026年的工业领域,数字孪生体早已不是新鲜概念,但如何让这一技术真正落地,为企业带来实实在在的价值,却始终是行业内的热门话题,从汽车制造到航空航天,从能源管理到智慧城市,数字孪生体的应用场景看似广泛,但实际落地时却面临诸多挑战:数据孤岛、模型精度不足、实时性要求高、跨系统协同困难……这些问题像一道道无形的墙,挡住了许多企业迈向智能化的脚步。
一项基于因子分析的研究为工业数字孪生体的应用方案提供了科学答案,这项研究由国内某知名工业互联网平台联合多家高校和科研机构完成,通过对200余家制造企业的深度调研和数据分析,揭示了影响数字孪生体应用效果的关键因子,并提出了针对性的解决方案,我们就结合几个2026年的真实案例,聊聊如何用因子分析破解数字孪生体的应用难题。 2026年生物制药与青少年教育及绿色售后链热度持续上升,相关产业迎来新发展
数据质量:数字孪生的“地基”不稳,一切都是空谈
数字孪生体的核心是“数据驱动”,但数据质量差是许多企业遇到的第一个坎,2026年,某汽车零部件制造商试图用数字孪生技术优化生产线,结果发现模型预测的故障时间与实际相差甚远,问题出在哪儿?原来,车间的传感器数据存在大量缺失和异常值,部分设备的采样频率甚至低于模型要求的1/10。
因子分析显示,数据质量是影响数字孪生体应用效果的首要因子,权重高达0.35,具体包括数据的完整性、准确性、实时性和一致性四个维度,以这家汽车零部件企业为例,他们的数据完整性只有62%(理想值应≥90%),准确性仅78%(理想值≥95%),直接导致模型预测误差超过30%。
解决方案:该企业引入了一套数据治理平台,对传感器数据进行实时清洗和校验,通过机器学习算法自动识别异常值,用历史数据填补缺失值,并统一不同设备的数据格式,他们还优化了采样策略,将关键设备的采样频率从每10秒一次提升到每1秒一次,3个月后,模型预测误差降至8%以内,生产线停机时间减少了40%。
另一个案例来自2026年的风电行业,某风电运营商发现,数字孪生模型对风机叶片疲劳的预测总是滞后于实际,检查后发现,问题出在数据传输延迟上——部分偏远地区的风场通过4G网络上传数据,延迟高达5-10秒,而叶片疲劳的监测需要毫秒级响应,通过改用5G专网,并将部分计算任务下沉到边缘设备,数据传输延迟降至100毫秒以内,模型终于能实时捕捉叶片的微小振动,预测准确率提升了25%。
模型精度:不是“越复杂越好”,而是“越匹配越好”
数字孪生体的模型精度直接影响决策的可靠性,但很多企业陷入了一个误区:认为模型越复杂,精度就越高,2026年,某化工企业花重金开发了一套包含200多个参数的数字孪生模型,结果运行起来卡顿严重,且预测结果与实际偏差较大,因子分析显示,模型复杂度与精度的相关性只有0.2,远低于模型与实际场景的匹配度(0.65)。
这家化工企业的核心问题是,模型中包含了大量与当前生产场景无关的参数(比如某些原料的微量成分,实际生产中几乎不变),而忽略了关键参数(如反应釜的温度梯度)的动态变化,通过因子分析,他们识别出影响模型精度的5个关键因子:参数相关性、动态响应能力、边界条件准确性、物理约束合理性和计算效率。
解决方案:该企业采用“降维+增维”的策略,用主成分分析法剔除冗余参数,将模型参数从200个精简到50个;针对关键生产环节(如反应釜)增加高精度子模型,捕捉局部动态变化,调整后,模型运行速度提升3倍,预测误差从12%降至4%,且能提前15分钟预警设备故障。 本月智能电网与绿色空气净化及体育教育热度持续攀升,相关应用不断深化

类似的案例也出现在2026年的半导体制造领域,某芯片厂发现,数字孪生模型对光刻机产出的良率预测总是偏低,检查后发现,模型中使用的光学参数是基于理论值,而实际设备因长期使用存在轻微老化,导致参数偏移,通过引入实时校准机制(每2小时用实际产出数据反推光学参数),模型预测良率与实际值的偏差从8%降至1%以内,每年可减少数百万美元的废片损失。
实时性:从“离线分析”到“在线决策”的跨越
数字孪生体的价值在于实时反馈,但很多企业的模型还停留在“离线分析”阶段,无法支持在线决策,2026年,某钢铁企业试图用数字孪生优化高炉冶炼过程,结果发现模型计算需要10分钟,而高炉的操作周期只有3分钟,等模型出结果,生产条件已经变了。 本月绿色装修与乡村振兴热度持续上升,相关产业迎来新机遇
因子分析显示,实时性是影响数字孪生体应用效果的第三大因子(权重0.2),具体包括数据采集延迟、模型计算速度和反馈闭环时间三个环节,这家钢铁企业的问题出在模型计算上——他们用的是基于物理方程的仿真模型,计算量极大,普通服务器根本跑不动。
解决方案:该企业采用了“混合建模”的方法,对高炉内温度、压力等关键参数,继续用物理模型保证精度;对其他次要参数(如气体成分),改用数据驱动的轻量级模型(如LSTM神经网络),计算速度提升10倍,他们将模型部署在边缘计算节点上,数据采集和计算同步进行,反馈闭环时间从10分钟缩短到1分钟以内,操作人员可以根据模型实时调整风量、煤量等参数,高炉燃料比降低了3%,年节约成本超2000万元。
另一个案例来自2026年的物流行业,某智能仓储企业发现,数字孪生模型对AGV(自动导引车)的调度优化总是滞后于实际需求,检查后发现,问题出在数据传输上——AGV的位置数据通过Wi-Fi上传,存在2-3秒的延迟,而调度算法需要毫秒级响应,通过改用UWB(超宽带)定位技术,并将调度算法下沉到AGV本地(每台车独立计算最优路径),调度延迟降至100毫秒以内,仓库吞吐量提升了15%。

跨系统协同:打破“数据孤岛”的关键
数字孪生体往往需要整合多个系统的数据(如ERP、MES、SCADA等),但很多企业的系统是“烟囱式”建设的,数据格式不统一、接口不开放,导致数字孪生体成了“孤岛”,2026年,某家电制造商试图用数字孪生优化供应链,结果发现模型只能获取生产计划数据,却拿不到库存、物流和销售数据,预测结果与实际偏差极大。
因子分析显示,跨系统协同能力是影响数字孪生体应用效果的第四大因子(权重0.18),具体包括数据接口标准化、系统集成度和权限管理三个维度,这家家电企业的问题在于,各系统由不同供应商开发,数据接口不兼容,且权限管理严格,导致数字孪生平台无法实时获取关键数据。 关注物联网应用与运动康复发展动态,技术创新推动产业升级
解决方案:该企业采用了“中台+微服务”的架构,建设一个数据中台,统一数据格式和存储方式;通过API网关开放各系统的数据接口,并采用OAuth2.0协议管理权限,他们将数字孪生模型拆解为多个微服务(如生产预测、库存优化、物流调度),每个微服务独立调用所需数据,避免系统耦合,调整后,数字孪生平台能实时获取全链条数据,供应链预测准确率提升了20%,库存周转率提高了15%。
类似的案例也出现在2026年的能源行业,某电网公司发现,数字孪生模型对电网负荷的预测总是偏低,检查后发现,问题出在数据来源上——模型只用了调度系统的历史数据,却没接入气象、经济、社会活动等外部数据,而这些因素对负荷影响极大,通过建设一个“数据湖”,整合内部系统和外部API的数据,并采用图神经网络捕捉多源数据的关联性,模型预测误差从8%降至3%,每年可减少数亿元的备用电源成本。
人才与组织:从“技术驱动”到“业务驱动”的转变
数字孪生体的应用不仅是技术问题,更是组织问题,2026年,某机械制造企业投入重金开发了一套数字孪生平台,结果发现业务部门根本不用——操作人员觉得模型“太复杂”,管理人员觉得“看不懂”,最终平台成了摆设。
因子分析显示,