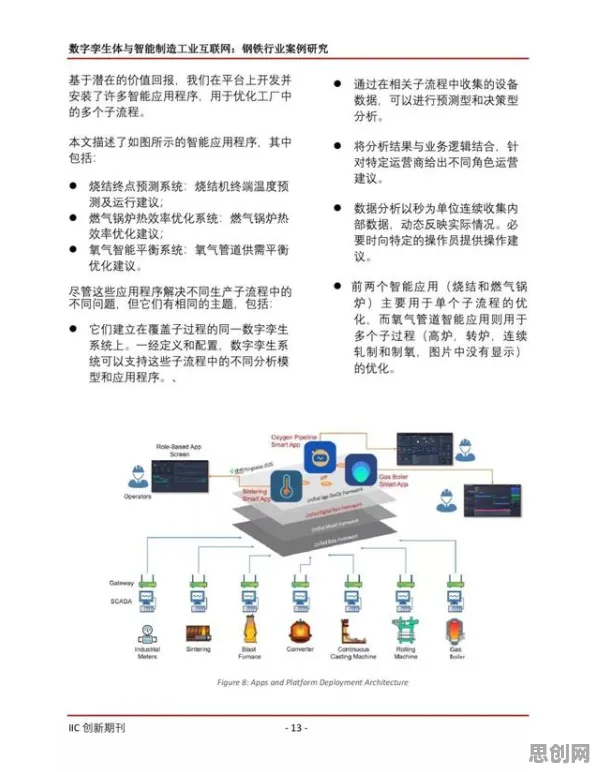
数据采集:从“大而全”到“精而准”的统计筛选
数字孪生的基础是数据,但并非所有数据都值得被采集,2026年,某汽车零部件制造商在部署数字孪生系统时,曾陷入“数据狂欢”的误区——他们在生产线上部署了200多个传感器,每天产生超过500GB的数据,但系统运行半年后,发现80%的数据从未被使用,反而增加了存储成本和计算负担。
“我们后来用统计学中的‘主成分分析’(PCA)对数据进行了降维处理。”该企业数字化转型负责人李工回忆道,“通过分析不同数据点之间的相关性,我们发现只有37个关键参数(如温度、压力、振动频率)能真正反映设备健康状态,其他数据要么冗余,要么噪声太大。”这一调整不仅将数据量压缩了80%,还让模型训练效率提升了3倍。
另一个典型案例来自某钢铁企业,他们在高炉数字孪生项目中,最初采集了从原料配比到出铁温度的200多项指标,但通过“方差分析”(ANOVA)发现,真正影响铁水质量的只有12个核心变量,基于这一发现,他们优化了传感器布局,将数据采集成本降低了45%,同时模型预测准确率从78%提升至92%。
这些实践揭示了一个关键统计逻辑:数字孪生的数据采集不是“越多越好”,而是要通过统计方法识别出对目标变量(如设备故障、产品质量)影响最大的关键因素,实现“精而准”的数据采集。
模型构建:从“黑箱”到“可解释”的统计突破
数字孪生的核心是模型,但传统深度学习模型常被诟病为“黑箱”——输入数据,输出结果,中间过程难以解释,这在工业场景中是致命缺陷——工程师需要知道“为什么设备会故障”,而不仅仅是“设备即将故障”。
2026年,统计学习方法正在改变这一局面,某风电企业在其风机数字孪生系统中,采用了“贝叶斯网络”模型,该模型不仅能预测风机齿轮箱的故障概率,还能通过条件概率分布展示不同参数(如油温、振动、负载)对故障的贡献度。“当油温超过85℃且振动幅值超过5mm/s时,故障概率会从3%飙升至67%。”该企业首席数据官王总表示,“这种可解释性让运维团队能针对性地调整维护策略,而不是盲目更换部件。”
在半导体制造领域,某芯片厂通过“广义线性模型”(GLM)构建了晶圆缺陷预测系统,与传统的神经网络相比,GLM能明确显示每个工艺参数(如蚀刻时间、温度梯度)对缺陷率的线性影响。“我们发现,蚀刻时间每增加1秒,缺陷率会上升0.2%,但温度梯度超过5℃时,缺陷率会呈指数级增长。”该厂工艺工程师张工说,“这种量化关系让我们能精准优化工艺参数,而不是靠经验试错。”
统计模型的另一个优势是“小样本学习”,在航空航天领域,某发动机制造商面临数据稀缺的挑战——每台发动机的测试数据只有几百条,远不足以训练深度学习模型,他们采用“高斯过程回归”(GPR)方法,通过统计先验分布和少量样本,构建了高精度的性能退化模型。“即使只有50组数据,我们也能预测发动机剩余寿命,误差控制在5%以内。”该项目负责人介绍。

实时优化:从“离线分析”到“在线学习”的统计迭代
工业数字孪生的价值不仅在于预测,更在于实时优化,2026年,越来越多的企业开始将“在线学习”统计方法融入数字孪生系统,实现模型与物理世界的动态同步。
某化工企业在其反应釜数字孪生项目中,采用了“卡尔曼滤波”算法,该算法能实时融合传感器数据与模型预测,动态调整反应参数。“当温度传感器显示200℃,但模型根据历史数据和当前压力预测实际温度应为198℃时,系统会自动修正传感器偏差,并调整加热功率。”该企业自动化总监陈工解释,“这种‘数据-模型’的闭环迭代,让反应效率提升了12%,产品合格率从92%提高到97%。”
在电力行业,某电网公司通过“强化学习”统计方法优化了数字孪生调度系统,该系统能根据实时负荷、天气和设备状态,动态调整发电计划。“传统调度是‘离线优化’,每天做一次计划;现在是‘在线学习’,每15分钟调整一次策略。”该公司调度中心主任表示,“2026年夏季用电高峰时,系统通过强化学习将弃风率从8%降至3%,相当于多消纳了200万度绿电。” 绿色制造与绿色技术链及空气净化热度持续上升,相关产业迎来新机遇
统计在线学习的另一个应用是“异常检测”,某食品厂在其包装线数字孪生系统中,部署了“孤立森林”(Isolation Forest)算法,该算法能实时识别生产中的异常模式——当包装速度突然下降10%,或封口温度偏离均值2个标准差时,系统会立即报警。“2026年3月,系统提前15分钟检测到封口机轴承磨损,避免了整条生产线的停机。”该厂运维经理回忆。
不确定性量化:从“确定预测”到“风险感知”的统计升级
工业场景充满不确定性——设备老化、原料波动、环境变化……这些因素会让数字孪生的预测结果产生偏差,2026年,统计学中的“不确定性量化”(UQ)方法正在成为数字孪生的标配。 本周慈善捐赠与绿色仓储及绿色产业链热度飙升,相关产业迎来新机遇

某汽车厂在其焊接数字孪生项目中,采用了“蒙特卡洛模拟”量化不确定性,该模型会生成1000组随机参数(如电流波动、电极磨损),模拟不同场景下的焊接质量。“当电流波动在±5%时,焊缝强度有95%的概率在400-450MPa之间;但如果波动超过±10%,强度可能降至350MPa以下。”该厂质量总监表示,“这种风险感知让我们能提前调整工艺参数,避免批量质量问题。”
在能源领域,某油田通过“贝叶斯层次模型”量化了油井产量预测的不确定性,该模型不仅考虑了地质参数(如渗透率、孔隙度),还纳入了生产历史数据和专家经验。“传统预测是‘点估计’,比如明年产量10万吨;现在是‘区间估计’,比如9-11万吨,概率80%。”该油田首席地质师解释,“这种量化不确定性让投资决策更科学——当产量下限低于盈亏平衡点时,我们会谨慎开发。”
统计不确定性量化的另一个价值是“鲁棒优化”,某物流企业在其仓储数字孪生系统中,通过“鲁棒优化”方法,在模型中引入需求波动、运输延迟等不确定性因素,生成更保守的库存策略。“2026年‘双11’期间,我们的库存周转率提升了20%,但缺货率从3%降至0.5%。”该企业供应链总监表示,“关键在于统计方法让我们能平衡效率与风险。”
跨尺度融合:从“单一模型”到“多层级统计架构”的实践创新
本月绿色沙漠治理与能量回收及社会责任热度不断攀升,技术创新带来新突破 工业数字孪生的复杂度在于需要融合多尺度数据——从微观的传感器信号到宏观的生产指标,从瞬时的设备状态到长期的历史趋势,2026年,统计学的“多层级建模”方法正在解决这一挑战。
某航空发动机制造商构建了“部件-系统-整机”三级数字孪生体系,在部件层,用“物理-统计混合模型”模拟单个叶片的振动;在系统层,用“贝叶斯网络”整合多个部件的交互;在整机层,用“动态因子模型”捕捉性能退化的长期趋势。“这种多层级统计架构让我们能同时诊断局部故障和预测整体寿命。”该项目首席科学家表示,“2026年,我们通过该系统提前6个月发现了一台发动机的低压涡轮裂纹,避免了空中停车事故。” 热度持续走高关注精准医疗发展动态,技术创新推动产业升级
在智能制造领域,某电子厂采用了“数字线程+统计建模”的方法,他们将设计、生产、测试数据通过“数字线程”串联,再用“结构方程模型”(SEM)分析不同环节的因果关系。“我们发现设计阶段的公差分配会影响生产良率,而生产参数的波动又会影响测试通过率。”该厂CTO介绍,“通过统计建模,我们优化了设计-生产协同流程,新产品上市周期缩短了