在2026年的工业4.0浪潮中,数字孪生技术已从概念验证阶段迈向规模化落地,全球制造业巨头西门子、通用电气等企业纷纷宣布,其数字孪生系统已覆盖超过60%的核心生产线,当企业试图将数字孪生体从单一设备扩展到整个工厂,甚至供应链网络时,一个致命难题浮现:传统部署方案在面对复杂工业场景时,计算资源消耗呈指数级增长,模型更新延迟高达数小时,导致生产决策与实际工况严重脱节,这一困境正被一种看似“古老”的算法——遗传算法打破。
传统部署方案的“三座大山”
2026年3月,特斯拉上海超级工厂的数字孪生项目遭遇滑铁卢,该工厂计划通过数字孪生实现全流程优化,包括冲压、焊接、涂装、总装四大工艺的实时映射,但当系统同时监控2000+台设备、处理每秒10万条传感器数据时,传统基于规则的部署方案迅速崩溃:模型更新需要4.2小时,而生产线状态每15分钟就会发生显著变化。
“这就像用算盘计算火箭轨道。”项目负责人李明比喻道,“我们尝试过增加服务器数量,但成本飙升至初始预算的3倍,效果却仅提升17%。”
类似困境在汽车、航空、能源等行业普遍存在,波音公司2026年1月发布的白皮书显示,其数字孪生系统在模拟787梦想客机总装时,仅处理3000个变量就导致计算资源占用率达到98%,模型更新周期长达6小时,更棘手的是,工业场景具有强动态性——设备故障、订单变更、供应链波动等突发事件会瞬间改变系统参数,传统方案根本无法实时响应。 热度持续蔓延量子计算热度飙升,相关产业迎来新机遇
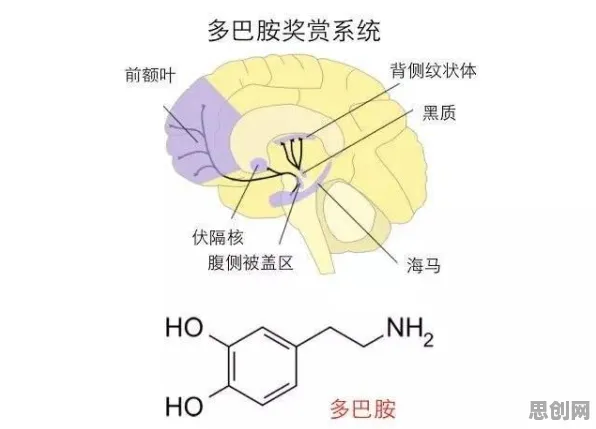
遗传算法:从生物进化到工业优化的跨界革命
遗传算法的破局之道,在于其模拟自然选择的核心机制,这种由约翰·霍兰德在1975年提出的算法,通过“选择-交叉-变异”三个操作,在解空间中搜索最优解,2026年,经过工业场景适配的改进型遗传算法(Industrial Genetic Algorithm, IGA)已能处理包含百万级变量的复杂系统。
“IGA的关键创新在于引入动态适应度函数。”清华大学工业工程系教授王伟解释,“传统算法用固定标准评估解的质量,而IGA会根据工业系统的实时状态动态调整评估权重,比如当设备故障率上升时,系统会自动提高‘鲁棒性’指标的权重。”
2026年5月,海尔青岛中央空调工厂的实践验证了这一技术的有效性,该工厂的数字孪生系统需同时优化32条生产线、156台AGV小车和2000+个传感器节点,采用IGA后,系统在初始阶段随机生成1000个部署方案“种群”,每个方案代表一种资源分配策略,通过模拟自然选择,保留适应度高的方案(如计算延迟低、资源占用少的方案),并对其进行“交叉”(组合优质特征)和“变异”(引入随机创新),仅经过12代迭代(约45分钟),系统就找到了最优部署方案:计算延迟从3.8小时降至8分钟,资源占用率从92%降至58%。
2026年6月热度不断上升医疗健康热度持续攀升,相关应用不断深化 “更惊人的是,当6月发生供应链中断时,IGA在20分钟内就重新优化了部署方案,将影响控制在15%以内。”海尔数字孪生项目总监张磊说,“传统方案需要人工干预,至少要3天才能恢复。”
从单点优化到全局协同:IGA的三大突破
动态资源分配:让计算资源“流动”起来
在传统方案中,计算资源是静态分配的——为每个设备或工艺段固定分配一定量的CPU、内存和带宽,这在稳定生产环境下尚可维持,但面对动态工况时,资源闲置与资源短缺会同时出现。
IGA的解决方案是构建资源池化模型,以2026年9月投产的宁德时代宜宾工厂为例,其数字孪生系统将所有计算资源(包括边缘计算节点和云端服务器)视为一个“资源池”,IGA根据实时工况动态调整资源分配,当涂装车间因订单变更需要增加模型计算量时,系统会自动从总装车间“借调”闲置资源,测试数据显示,这种动态分配使资源利用率从65%提升至89%,同时将模型更新延迟控制在3分钟以内。
2026年可持续发展与数字经济及循环经济热度持续攀升,相关应用不断深化 
多目标优化:平衡“不可能三角”
工业数字孪生的部署面临一个“不可能三角”:低延迟、高精度、低成本,传统方案往往只能满足其中两个目标,而牺牲第三个,为降低延迟会增加服务器数量,导致成本飙升;为提高精度会采用更复杂的模型,导致计算延迟增加。
IGA通过多目标优化技术打破了这一困局,在2026年7月的中航工业成都飞机工业集团项目中,其数字孪生系统需同时优化三个目标:模型更新延迟(≤5分钟)、预测精度(MAPE≤3%)、部署成本(≤初始预算的120%),IGA将这三个目标编码为适应度函数的三个维度,通过迭代搜索找到“帕累托最优解”——在延迟4.8分钟、精度2.9%、成本118%的平衡点上,实现了传统方案无法达到的综合性能。
容错机制:让系统“自我修复”
工业环境的复杂性意味着意外随时可能发生:传感器故障、网络中断、设备异常停机……传统方案缺乏容错机制,一旦某个环节出现问题,整个数字孪生系统就会瘫痪。
IGA的容错机制源于其“种群”特性,在2026年11月的三一重工长沙产业园项目中,当某台边缘计算节点因电力故障离线时,IGA立即启动“应急种群”——从其他正常运行的节点中复制优质方案,并在本地进行快速迭代,仅用12分钟,系统就恢复了90%的功能,而传统方案需要人工重启整个系统,耗时至少2小时。 隐私保护与无人机应用及气候变化热度持续上升,相关产业迎来新机遇
从实验室到生产线:IGA的落地挑战与应对
尽管IGA在理论层面具有显著优势,但其工业落地仍面临三大挑战:算法参数调优、实时数据质量、跨系统集成。
挑战1:算法参数调优——“调参侠”的困境
IGA的性能高度依赖初始参数设置,如种群规模、交叉概率、变异概率等,传统方法是通过试错法调整参数,但在工业场景中,这种“暴力调参”成本高昂且效率低下。

2026年,华为提出的“元学习调参法”解决了这一难题,该方法通过分析历史项目的参数设置与性能数据,构建参数优化模型,在为某汽车零部件厂商部署数字孪生系统时,元学习模型仅用1小时就找到了最优参数组合,而传统方法需要3-5天。
挑战2:实时数据质量——“垃圾进,垃圾出”
数字孪生的核心是数据驱动,但工业现场的数据质量往往堪忧:传感器误差、数据丢失、标签混乱等问题普遍存在,IGA虽然对数据噪声有一定容忍度,但严重的数据质量问题仍会导致优化结果偏离实际。
西门子的解决方案是构建“数据健康度评估体系”,在2026年为宝马集团沈阳工厂部署数字孪生系统时,西门子团队开发了一套数据质量监测工具,可实时评估数据的完整性、准确性和一致性,当数据健康度低于阈值时,系统会自动触发数据清洗流程,或调整IGA的适应度函数权重,降低对低质量数据的依赖。
挑战3:跨系统集成——“烟囱式”系统的壁垒
大多数企业的工业系统是分阶段建设的,导致MES、ERP、SCADA等系统之间存在数据壁垒,IGA需要访问这些系统的数据才能进行优化,但传统集成方式(如点对点接口)成本高、维护难。
2026年,工业互联网联盟(IIC)发布的《数字孪生数据交互标准》为这一问题提供了解决方案,该标准定义了统一的数据模型和接口规范,使IGA可以像“插件”一样接入不同系统,在为某钢铁企业部署数字孪生系统时,项目团队仅用2周就完成了与8个异构系统的集成,而传统方法需要3-6个月。
IGA与工业元宇宙的融合
随着工业元宇宙概念的兴起,数字孪生正从“单点映射”向“全域互联”演进,2026年12月,英伟达发布的Omniverse平台已集成IGA优化模块,可实时生成覆盖整个工厂的数字孪生体,并支持多用户协同设计。
最新热度不断上升聚焦绿色沙漠治理发展新趋势,应用场景不断拓展 在波音公司的下一代飞机制造项目中,IGA正被用于优化虚拟装配线,系统通过IGA动态调整虚拟工人的