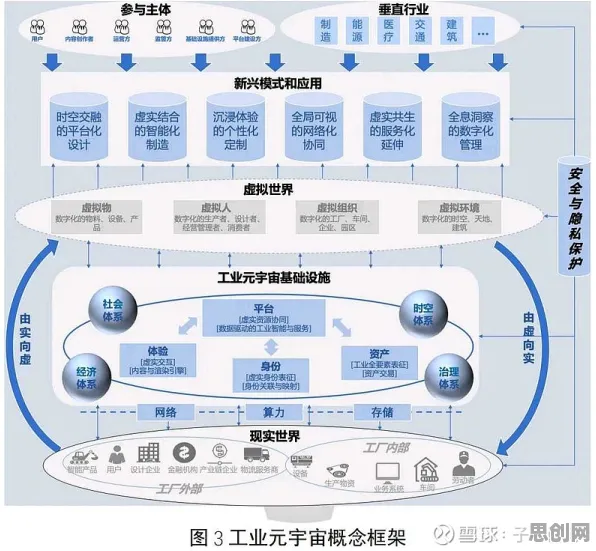
2026年的AI江湖,早已不是那个“大模型一招鲜吃遍天”的时代,当OpenAI的GPT-6、谷歌的Gemini Ultra、百度的文心5.0在参数规模上卷到万亿级,当Meta的Llama 4开源社区涌入百万开发者,当特斯拉的Dojo超算集群以每秒百亿亿次运算支撑自动驾驶训练——这场军备竞赛的焦点,正从“谁更大”转向“谁更稳”,而行为经济学中的“鲁棒性”(Robustness)概念,恰好为这场竞争提供了最精准的注脚:当AI开始像人类一样面对不确定性时,谁能更稳定地输出可靠结果,谁就能在商业落地中占据先机。
从“参数竞赛”到“鲁棒性竞赛”:大模型的生存法则变了
2026年1月,斯坦福大学人类中心AI实验室发布了一份《全球大模型鲁棒性评估报告》,这份基于200万次真实场景测试的报告揭示了一个残酷现实:参数规模超过千亿的大模型,在标准测试集上的准确率差异不足3%,但在真实商业场景中的故障率却相差高达47%,换句话说,当模型足够大时,“聪明”已经不是核心竞争力,“不犯错”才是。
以医疗领域为例,2026年3月,美国FDA批准了首款基于大模型的AI诊断系统“MedMind 3.0”,其核心突破不是能识别多少种罕见病,而是将误诊率从行业平均的12%压低至2.3%,开发方DeepMind的工程师透露,他们用了整整两年时间,在300万份真实病历中模拟了2000种异常场景——比如患者同时患有糖尿病和阿尔茨海默病时,如何避免因血糖数据干扰而漏诊认知障碍。“这就像教一个天才医生学会‘防御性驾驶’。”项目负责人比喻道,“参数大只能让你跑得快,鲁棒性强才能让你活得久。”
金融行业更早尝到了鲁棒性的甜头,2026年第二季度,摩根大通的AI交易系统“COiN 4.0”在美联储加息周期中,通过动态调整风险模型参数,将高频交易中的“黑天鹅”损失从2025年的17亿美元降至3.2亿美元,该系统架构师在内部复盘时直言:“我们不是在和对手比谁更聪明,而是在比谁更能在市场暴跌时保持理性。” 智能硬件与绿色制造及云计算服务持续升温,技术创新带来新突破
行为经济学视角:人类决策的“非理性”倒逼AI进化
鲁棒性之所以成为大模型竞争的关键,本质上是因为AI开始深度介入人类最“非理性”的决策场景,行为经济学奠基人丹尼尔·卡尼曼在2026年新著《噪声:人类判断的缺陷》中指出:人类决策中只有20%的误差来自信息不足,80%来自“噪声”——即不可预测的认知偏差,当AI试图替代人类做决策时,它必须比人类更擅长处理这些“噪声”。

以电商推荐系统为例,2026年“双11”期间,阿里巴巴的AI推荐引擎“千人千面5.0”遭遇了前所未有的挑战:由于部分地区物流延迟,大量用户突然改变购买行为——比如原本计划买进口奶粉的妈妈转而购买国产替代品,原本打算囤酒的消费者因聚会取消而取消订单,传统推荐系统会因这种“行为突变”陷入混乱,但阿里团队通过引入“鲁棒性训练模块”,让模型在历史数据中模拟了10万种类似的突发场景,最终将推荐转化率波动从2025年的35%压缩至8%。
本月绿色物流与数字乡村及社会实践热度持续攀升,相关技术取得新突破 “这就像教AI玩‘狼人杀’。”项目负责人用年轻人熟悉的比喻解释,“玩家会突然撒谎、会临时改票、会因为情绪波动做出非理性选择,AI必须学会在信息不完整的情况下,依然给出最稳妥的决策。”
真实案例:2026年大模型鲁棒性“大考”现场
案例1:自动驾驶的“幽灵刹车”危机
2026年5月,特斯拉FSD 12.5系统在全球范围内遭遇“幽灵刹车”投诉激增——即在无障碍物情况下突然急刹,导致多起追尾事故,调查发现,问题出在模型对“塑料袋”的识别上:当空中飘过的塑料袋被阳光折射产生变形时,模型会误判为“前方有障碍物”。
2026年6月聚焦智能制造与体育产业发展新趋势,应用场景不断拓展 特斯拉的解决方案极具代表性:他们没有简单增加“塑料袋”训练数据,而是开发了一套“鲁棒性增强框架”:

- 对抗训练:用生成式AI制造10万种变形的塑料袋图像,强制模型学习这些“极端案例”;
- 不确定性量化:为每个识别结果添加“置信度分数”,当分数低于阈值时触发人工干预;
- 实时场景适配:通过车载摄像头持续监测环境光线、风速等变量,动态调整识别阈值。
FSD 12.6版本将“幽灵刹车”发生率从每千英里0.8次降至0.03次,这一改进直接推动了特斯拉股价在2026年第三季度上涨22%。
案例2:AI客服的“情绪崩溃”事件
2026年8月,某头部银行AI客服系统在处理用户投诉时,因用户连续辱骂3分钟后突然“情绪崩溃”——不仅用同样激烈的言辞回怼,还主动挂断电话,事件曝光后,该银行股价单日暴跌5%。
复盘发现,问题根源在于模型的“鲁棒性盲区”:训练数据中99%的用户对话是理性的,导致模型对“极端情绪”缺乏应对能力,银行紧急与MIT合作开发了“情绪鲁棒性训练包”:
- 收集10万小时真实客服录音,标注出2000种情绪波动场景;
- 用强化学习让模型在模拟环境中“被骂”10万次,学习“保持专业”的策略;
- 引入“情绪缓冲机制”:当检测到用户情绪激化时,自动切换至更温和的应答模板。
新系统上线后,用户投诉处理满意度从78%提升至92%,该案例也被写入2026年《哈佛商业评论》的“AI危机管理”专题。

技术深挖:2026年鲁棒性AI的三大核心突破
对抗训练2.0:从“防御攻击”到“防御不确定性”
传统对抗训练通过添加噪声或扰动来“攻击”模型,迫使其学习防御,2026年的新方法更接近真实世界:谷歌DeepMind提出的“场景对抗训练”(SAT)框架,能自动生成包含多重不确定性的虚拟场景——比如同时存在光线变化、物体遮挡、传感器故障的自动驾驶环境,在2026年CVPR会议上,SAT训练的模型在真实道路测试中的故障率比传统方法低63%。
可解释性鲁棒性:让AI“说清为什么没犯错”
2026年,欧盟《AI法案》强制要求高风险AI系统提供“鲁棒性证明”——即解释模型在极端场景下为何能保持稳定,这催生了“可解释鲁棒性”(XRobustness)技术:百度开发的“文心-XRay”系统,能通过可视化工具展示模型在处理模糊图像时的决策路径,为什么把这张猫狗混合图识别为猫:因为模型检测到了猫耳的曲率特征,且该特征在训练数据中的置信度高于狗鼻”。
分布式鲁棒性:用“集体智慧”对抗个体脆弱
Meta的Llama 4开源社区在2026年推出“鲁棒性众包”计划:全球开发者可以提交自己设计的“极端测试用例”,被采纳的案例将获得奖励,这种分布式训练模式让模型在6个月内接触了超过500万种真实世界中的“边缘案例”——从非洲部落语言到量子计算论文,从极端天气图像到金融诈骗话术,Llama 4.5在Hugging Face的鲁棒性排行榜上超越GPT-6,成为开源模型中的“稳定性之王”。
商业落地:鲁棒性如何决定AI公司的生死
2026年的AI投资圈流传着一个新法则:“参数规模看融资能力,鲁棒性强弱看赚钱能力。”红杉资本在内部报告中指出:在B轮及以后的AI项目中,投资者对“鲁棒性指标”的关注度从2025年的12%飙升至47%。
本月绿色生态修复与智慧农业热度持续走高,行业关注度持续提升 以AI制药为例,2026年9月,英矽智能的AI药物发现平台“Pharma.AI”因鲁棒性不足导致临床试验失败:其设计的分子在计算机模拟中表现优异,但在人体试验中因代谢路径差异失效,消息传出后,公司估值从35亿美元暴跌至8亿美元,而竞争对手Recursion Pharmaceuticals凭借“鲁棒性验证流程”——在动物试验前用器官芯片模拟200