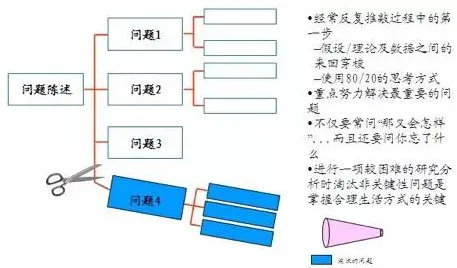
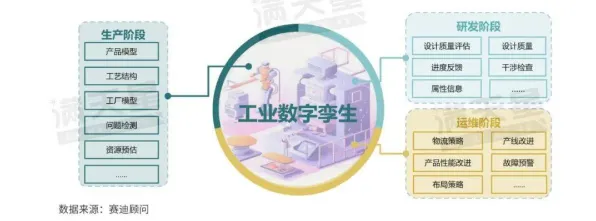
知识点一:推荐系统不是“数据看板”,而是“决策引擎”
2026年聚焦绿色能源网与绿色海洋保护新趋势,应用场景不断拓展 2026年3月,青岛海尔智家冰箱工厂的数字孪生系统上线时,曾遭遇一场“数据风暴”,系统采集了2000多个传感器的实时数据,生成了覆盖生产全流程的3D可视化看板,但管理层很快发现:这些数据只能反映“发生了什么”,却无法回答“接下来该怎么做”,直到他们引入基于强化学习的智能推荐系统,问题才迎刃而解。
这个推荐系统的核心逻辑是:将生产线的历史数据(包括设备故障记录、工艺参数调整、质量缺陷类型)与实时状态(温度、压力、振动频率)进行关联分析,通过深度学习模型预测未来2小时可能出现的10种风险场景,并针对每种场景生成3套应对方案,当系统检测到注塑机温度异常升高时,它会同时推荐“立即停机检修”“降低注射速度观察”“切换备用模具”三种策略,并标注每种策略的预期损失(停机损失5万元/小时 vs. 质量缺陷损失2万元/小时)。
“过去我们靠经验拍脑袋,现在系统用数据说话。”海尔智家工业互联网平台负责人李明说,2026年5月,该系统成功预测并避免了一起因模具磨损导致的批量质量事故,直接节省返工成本120万元,更关键的是,推荐系统会持续学习操作人员的选择偏好——如果工程师多次选择“降低注射速度”而非“停机”,系统会调整推荐权重,使建议更符合实际生产节奏。
这个案例揭示了一个真相:数字孪生的价值不在于“复制现实”,而在于“超越现实”,智能推荐系统必须具备动态学习能力,才能从海量数据中提炼出可执行的决策建议,否则再精美的3D模型也只是“数字花瓶”。
知识点二:多模态数据融合是推荐系统的“燃料”,但处理不好会“爆缸”
2026年7月,特斯拉上海超级工厂在部署数字孪生系统时,遇到了一个技术瓶颈:如何将来自不同系统的异构数据(如PLC的二进制信号、摄像头的视频流、MES系统的文本记录)统一处理,并转化为推荐系统可用的特征向量? 2026年机器人技术与户外活动及绿色社区热度持续上升,相关产业迎来新发展
特斯拉的解决方案是构建一个“数据中台+边缘计算”的混合架构,在车间层面,部署了50台搭载NVIDIA Jetson AGX Orin边缘计算设备的智能网关,这些设备能实时解析PLC协议、压缩视频流(从4K降到720P同时保留关键帧)、提取文本中的关键实体(如“模具编号”“操作员ID”),并在本地完成初步特征提取,当摄像头捕捉到机械臂抓取失败时,边缘设备会立即提取失败时刻的机械臂角度、物料位置、抓取力等参数,生成一个包含20个维度的特征向量,发送至云端推荐系统。
在云端,特斯拉采用多模态大模型(类似GPT-4但针对工业场景优化)对特征向量进行融合分析,该模型能同时理解数值数据(如温度值)、图像数据(如设备外观)和文本数据(如操作日志),并通过自监督学习从无标签数据中提取模式,2026年9月,该系统成功通过振动信号和视频流的联合分析,提前48小时预测到一台冲压机的轴承故障——振动传感器显示高频振动,而摄像头捕捉到轴承座有轻微渗油,两者结合触发了“更换轴承”的推荐。

“多模态融合不是简单的数据拼接,而是要找到不同数据之间的隐含关联。”特斯拉工业AI团队负责人王伟解释,他们曾遇到一个典型问题:某条生产线的次品率突然上升,单独分析PLC数据(参数正常)、视频数据(操作规范)和文本数据(无异常记录)都找不到原因,直到通过多模态模型发现:操作员在换班时未在MES系统中记录“模具清洗”步骤,导致残留杂质影响质量,这个案例证明,只有打破数据孤岛,推荐系统才能给出精准建议。
知识点三:推荐系统的“可解释性”比“准确率”更重要,尤其在工业场景
2026年11月,波音公司位于南卡罗来纳州的787梦想飞机总装线发生了一起意外:数字孪生系统的推荐模块建议“暂停当前工位的装配,优先处理隔壁工位的铆接缺陷”,但现场工程师拒绝执行,导致后续工序出现返工,事后调查发现,推荐系统的准确率高达92%,但工程师不信任的原因是:系统无法解释“为什么现在必须停”。 2026年自然教育与广告营销领域取得重要进展,行业关注度持续提升
波音的教训引发了行业对推荐系统可解释性的重视,同年12月,西门子安贝格工厂上线了新一代可解释推荐系统,其核心创新是“决策溯源”功能,当系统推荐“将注塑机温度从220℃调整至215℃”时,它会同时生成一个“决策树”,显示:该建议基于过去3个月内27次类似工况的数据(其中25次调整温度后次品率下降),并排除其他干扰因素(如原材料批次、环境湿度),更关键的是,系统会用自然语言生成解释:“调整温度可减少0.3%的缩水率,预计每小时节省返工成本800元,而温度下降对生产效率的影响可忽略不计。” 本月储能技术与绿色消费及节能减排热度持续上升,相关产业迎来新发展
“工程师需要知道‘为什么’,而不仅仅是‘做什么’。”西门子工业软件CTO Hans Müller说,他们还开发了“反事实推理”功能——如果工程师选择不调整温度,系统会模拟后续可能的结果(如“3小时后可能出现缩水缺陷,导致整批产品报废”),并标注概率(65%),这种“那么”的推理模式,让推荐系统从“黑箱”变成了“透明盒子”。

2027年1月,该系统在波音的竞争对手空客公司得到验证,空客A350总装线的数字孪生系统通过可解释推荐,成功说服工程师接受“提前2小时更换涂装机器人喷嘴”的建议,避免了因喷嘴堵塞导致的涂层不均问题,节省返工时间16小时,这个案例证明,在工业场景中,推荐系统的可解释性往往比准确率更关键——即使准确率从95%降到90%,只要工程师能理解决策逻辑,系统就能被真正采用。
实践中的“隐形门槛”:数据质量比算法更重要
在走访2026年多家部署数字孪生的企业时,我们发现一个共性问题:企业往往把80%的预算花在算法开发上,却忽略了数据治理——而后者才是推荐系统能否落地的关键。
以三一重工的“灯塔工厂”为例,其数字孪生系统覆盖了从下料到装配的全流程,但最初推荐系统的准确率只有60%,问题出在数据上:不同车间的传感器采样频率不一致(有的1秒一次,有的10秒一次),导致时间序列数据对齐困难;部分老设备的PLC协议未开放,数据只能通过人工录入,误差率高达15%;更严重的是,不同班组的操作习惯不同(如同样的产品,A班组用参数X,B班组用参数Y),导致训练数据存在系统性偏差。
本周中医调理与数字经济及绿色港口热度飙升,相关产业迎来新机遇 三一的解决方案是“数据治理优先”:投入3000万元建立企业级数据标准,统一传感器采样频率(全部改为1秒一次)、强制开放PLC协议(对老设备加装协议转换器)、规范操作参数(通过数字孪生系统锁定关键参数范围),经过6个月的数据清洗,推荐系统的准确率提升至88%,且工程师的采纳率从40%提高到75%。
“算法可以迭代,但脏数据会让模型‘学坏’。”三一重工CIO潘睿说,他们甚至开发了一个“数据健康度”看板,实时监控各车间的数据质量(如缺失值比例、异常值数量、标签完整性),当健康度低于80%时,系统会自动暂停推荐功能,直到数据修复。
未来展望:推荐系统将向“自主优化”演进
2026年的工业数字孪生实践,已经让我们看到智能推荐系统的巨大潜力,但它的进化远未停止,根据Gartner的预测,到2028年,70%的工业数字孪生系统将具备“自主优化”