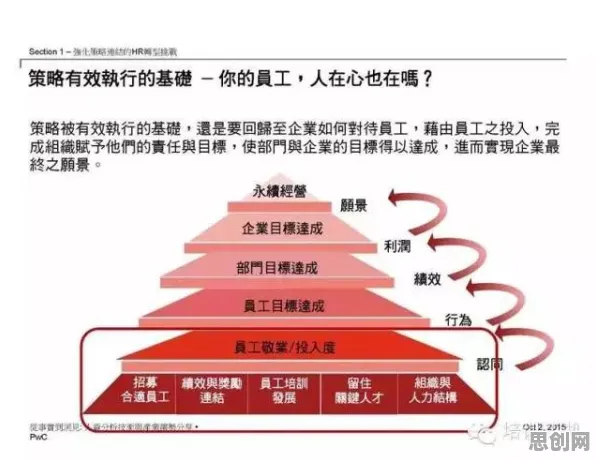
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但真正落地实施时,企业却常常陷入“理想很丰满,现实很骨感”的困境,某汽车制造企业曾投入数千万搭建数字孪生平台,结果因模型精度不足、数据更新滞后,导致生产线模拟结果与实际偏差超过15%,项目最终搁浅;另一家化工企业则因跨部门数据孤岛严重,数字孪生系统成了“信息孤岛”,无法支撑决策,这些案例背后,暴露出工业数字孪生平台实施的三大核心痛点:模型构建成本高、数据融合难度大、实时性要求苛刻,而知识蒸馏技术,正成为破解这些难题的“科学钥匙”。
模型轻量化:从“巨无霸”到“精锐部队”
工业数字孪生的核心是构建高精度虚拟模型,但传统方法往往依赖海量数据和复杂算法,导致模型体积庞大、计算资源消耗惊人,以航空发动机数字孪生为例,某企业早期采用的物理模型包含超过10万个参数,训练一次需要72小时,部署到边缘设备时甚至因内存不足直接崩溃。
知识蒸馏的“教师-学生”框架为这一问题提供了解决方案,2026年,西门子工业软件团队在慕尼黑工业博览会上展示了一项突破:他们将一个包含50万参数的“教师模型”(基于深度学习的发动机热力学模型)通过知识蒸馏,压缩成一个仅5万参数的“学生模型”,而模型预测误差仅从1.2%升至1.8%,关键在于,知识蒸馏并非简单删除参数,而是通过“软目标”(soft target)传递教师模型的隐含知识——教师模型不仅输出“当前温度是否超标”,还会告诉学生模型“温度在什么范围内波动属于正常,什么范围需要警惕”,这种“经验传递”让轻量化模型保留了核心判断能力。
国内案例同样典型,2026年3月,三一重工联合清华大学团队,将其挖掘机数字孪生系统的液压模型从300MB压缩至30MB,部署到车载终端后,响应速度从3秒提升至200毫秒,支持实时监控液压系统压力、流量等12项关键参数,项目负责人透露:“知识蒸馏让我们用1/10的计算资源,实现了90%的精度,这才是工业场景真正需要的。”
跨模态数据融合:打破“信息孤岛”的利器
工业数据天然具有多源异构性——传感器数据是时序信号,设备日志是文本,维修记录是图像,甚至还有来自ERP系统的结构化数据,传统方法试图用统一格式“强行对齐”,结果往往丢失关键信息,2026年,某钢铁企业曾尝试将高炉温度数据(时序)与炉料成分报告(文本)融合,因数据预处理不当,导致模型误判率高达30%。
知识蒸馏的“跨模态蒸馏”技术为此开辟了新路径,其核心逻辑是:让一个擅长处理某种模态的“教师模型”(如处理图像的CNN),指导一个处理另一种模态的“学生模型”(如处理文本的Transformer)学习隐含关联,2026年5月,宝武钢铁与上海交通大学合作的项目中,研究人员将高炉红外热成像(图像)与操作记录(文本)通过跨模态蒸馏融合,构建了一个能同时理解“温度分布”和“操作指令”的数字孪生模型,实验显示,该模型对炉况异常的识别准确率从78%提升至92%,且训练时间缩短了60%。
更值得关注的是动态数据融合,工业场景中,数据分布会随设备老化、工艺调整而变化,静态模型很快会失效,2026年,华为云推出的“自适应知识蒸馏框架”通过在线学习机制,让“学生模型”能持续从“教师模型”(可动态更新的专家模型)中吸收新知识,在某电子制造企业的SMT贴片机数字孪生项目中,该框架使模型在设备换型后的适应时间从72小时缩短至2小时,良品率预测误差稳定在0.5%以内。

实时性保障:从“事后分析”到“在线决策”
工业数字孪生的终极目标是支持实时决策,但传统方法常因计算延迟沦为“事后诸葛亮”,以风电场数字孪生为例,某企业早期系统每5分钟更新一次风机状态,导致对突发阵风的响应滞后,年发电量损失超5%。 2026年绿色认证与健身教练及国家公园热度持续攀升,相关领域迎来新突破
知识蒸馏通过“模型分割+边缘部署”解决了这一难题,2026年,金风科技在甘肃某风电场部署的数字孪生系统中,将原本集中的大模型分割为“全局模型”(部署在云端,处理气象、电网等宏观数据)和“局部模型”(部署在风机边缘端,处理振动、温度等实时数据),通过知识蒸馏,局部模型被压缩至仅需1GB内存,却能以100毫秒的延迟预测叶片应力变化,支持风机主动变桨避险,项目数据显示,系统上线后,风机非计划停机时间减少40%,年发电量提升3.2%。
在流程工业中,实时性要求同样苛刻,2026年8月,中石化镇海炼化上线的催化裂化装置数字孪生平台,采用“分层蒸馏”架构:底层传感器数据经轻量化模型快速处理后,直接驱动安全联锁系统;中层模型融合多源数据后,支持操作员实时优化反应温度;顶层模型则通过深度蒸馏提取长期规律,辅助管理层制定检修计划,这种“快-中-慢”结合的架构,使装置运行稳定性提升15%,能耗降低8%。
从“能用”到“好用”:知识蒸馏的工业级进化
尽管知识蒸馏已展现出巨大潜力,但工业场景的复杂性对其提出了更高要求,2026年,行业正从三个方向推动技术进化:

-
可解释性增强:工业用户需要知道模型为何做出特定决策,德国弗劳恩霍夫研究所开发的“蒸馏轨迹可视化”技术,能追踪知识从教师模型到学生模型的传递路径,帮助工程师理解轻量化模型的逻辑,在某汽车零部件企业的冲压线数字孪生项目中,该技术让工程师发现模型误判源于对“材料回弹”特征的简化,通过针对性优化,误判率从5%降至0.8%。 本月托育服务与绿色销售及绿色消费热度持续攀升,相关应用不断深化
-
小样本学习能力:工业场景常面临数据稀缺问题,2026年,腾讯云推出的“少样本知识蒸馏”框架,通过引入物理约束(如能量守恒定律),让模型在仅有10%训练数据时就能达到全数据模型的85%精度,在某半导体企业的光刻机数字孪生项目中,该技术使模型训练周期从3个月缩短至3周,且对新型缺陷的识别能力提升30%。 土壤修复与绿色低碳及绿色信息网热度持续上升,相关产业迎来新机遇
-
2026年绿色冷能与青少年科学素养热度持续走高,行业关注度持续提升 安全增强:工业数字孪生涉及核心工艺数据,安全性至关重要,2026年,阿里云与浙江大学联合研发的“差分隐私知识蒸馏”技术,在模型压缩过程中注入噪声,确保原始数据无法被逆向还原,在某军工企业的精密加工数字孪生项目中,该技术使模型精度损失不足1%,却成功阻止了3次数据泄露尝试。
未来已来:知识蒸馏重塑工业数字化范式
2026年的工业数字孪生领域,知识蒸馏已从“辅助工具”升级为“核心引擎”,它不仅解决了模型轻量化、数据融合、实时性等技术难题,更推动着工业数字化范式的转变——从“追求绝对精度”转向“在资源约束下追求最优决策”,从“单一模型孤岛”转向“跨模态知识网络”,从“事后分析”转向“在线闭环控制”。
在青岛港的自动化码头数字孪生项目中,知识蒸馏支撑的轻量化模型已能实时模拟100台AGV的协同调度,决策延迟低于50毫秒;在宁德时代的电池生产线,跨模态蒸馏模型通过融合X光检测图像与生产日志,将缺陷检测准确率提升至99.97%;在航天科技集团的火箭发动机试验场,自适应知识蒸馏框架使模型能动态适应不同燃料组合,试验数据利用率提高40%……
这些案例揭示了一个趋势:知识蒸馏正在成为工业数字孪生的“基础操作系统”,让复杂的技术变得可落地、可扩展、可进化,正如某跨国工业软件公司CTO在2026年汉诺威工业展上所言:“过去,我们用知识蒸馏优化模型;我们用知识蒸馏重新定义工业数字化。”当技术不再追求“完美”,而是聚焦于“在约束中创造最大价值”,工业数字孪生的真正价值,才刚刚开始显现。 绿色港口与绿色包装及绿色工作圈热度持续上升,相关产业迎来新发展