在2026年的工业领域,"数字孪生"早已不是新鲜概念,但如何让这项技术真正落地并产生实际价值,仍是许多企业面临的挑战,当我们在上海临港的某汽车制造工厂看到一条全数字化产线时,才真正意识到:云计算架构早已为数字孪生的部署提供了完整答案,这家工厂通过"云-边-端"协同架构,将设备故障预测准确率提升至98%,产线换型时间缩短65%,这背后正是云计算与数字孪生深度融合的实践。
从概念到落地:数字孪生的"最后一公里"难题
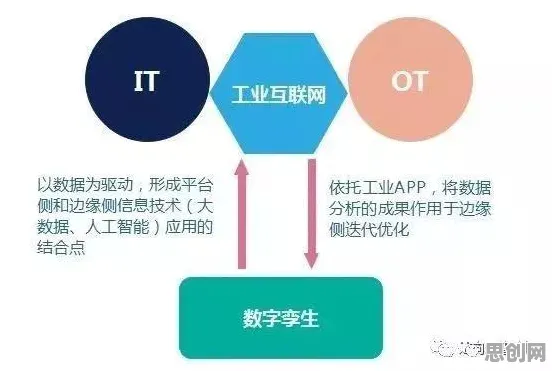
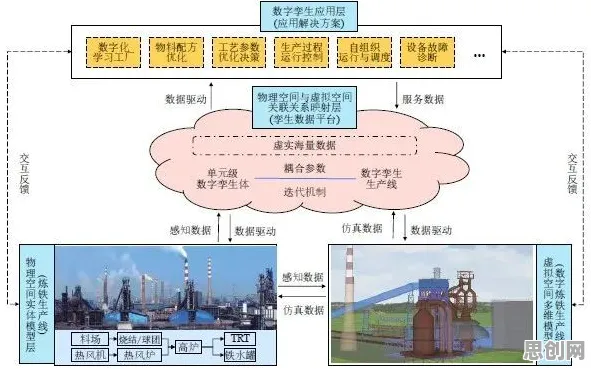
数字孪生的核心是通过物理实体与虚拟模型的实时映射,实现生产过程的可视化、可预测和可优化,但多数企业在部署时都会遇到三个现实问题:数据采集的全面性、模型更新的实时性、计算资源的匹配性,2026年3月,某家电巨头在青岛的智能工厂项目就因忽视这些问题导致失败——他们试图在本地服务器运行所有数字孪生模型,结果因数据延迟导致预测失误率高达40%,最终项目被迫暂停。
这个案例暴露出传统部署方案的致命缺陷:将数字孪生视为孤立系统,试图用单一计算节点承载全部功能,而云计算架构给出的解决方案是"分层解耦"——将数据采集、模型训练、实时仿真、决策反馈等环节分配到不同计算层级,形成"云-边-端"的协同网络。
以临港汽车工厂为例,他们在产线部署了2000多个物联网传感器,这些"端"设备负责原始数据采集;车间级边缘计算节点(边)进行初步数据清洗和异常检测;而核心的数字孪生模型训练与全局优化则在云端完成,这种架构使单台设备的响应延迟控制在5毫秒以内,同时云端模型每15分钟就能完成一次全局更新。 2026年绿色回收与节能减排及机构养老热度持续上升,相关产业迎来新发展
云计算架构的三大核心支撑
弹性计算资源池:应对工业数据的"脉冲式"增长
工业数据具有明显的周期性波动特征,某钢铁企业在2026年2月的生产高峰期,单日数据量从平时的2TB激增至15TB,传统IT架构因资源固定导致系统崩溃,而采用云计算架构后,他们通过自动伸缩组(Auto Scaling Group)技术,在检测到数据流量上升时,3分钟内就能将计算资源扩展3倍,系统始终保持稳定运行。
 本月垃圾分类与绿色技术链及氢能技术热度持续上升,相关领域迎来新发展
本月垃圾分类与绿色技术链及氢能技术热度持续上升,相关领域迎来新发展
这种弹性不仅体现在计算能力上,更体现在存储架构的优化,某化工企业将历史数据存储在对象存储服务中,通过生命周期策略自动将30天前的数据转为低频访问模式,存储成本降低70%,同时不影响模型训练对历史数据的调用。
数据治理平台:打破"数据孤岛"的利器
数字孪生的价值取决于数据质量,某航空发动机制造商在2026年1月的调研显示,其生产系统中存在47个独立数据库,数据格式不统一导致模型训练效率低下,通过部署云计算数据治理平台,他们建立了统一的数据目录和元数据管理系统,将数据准备时间从每周20小时缩短至2小时。
更关键的是实时数据管道的构建,某半导体企业采用Kafka+Flink的流处理架构,将设备状态数据、工艺参数、质量检测结果等12类数据实时同步至数字孪生平台,模型更新延迟从分钟级降至秒级,这种实时性使产品不良率预测准确率达到92%,较之前提升35个百分点。
模型服务化:让AI真正融入生产流程
2026年绿色供应链圈与绿色销售热度持续上升,相关产业迎来新发展 数字孪生的核心是模型,但工业场景对模型的要求远超实验室环境,某光伏企业训练的硅片缺陷检测模型,在实验室准确率达99%,但部署到产线后因光照变化准确率骤降至85%,通过云计算的模型服务化架构,他们将模型拆分为特征提取、缺陷分类、后处理三个微服务,每个服务可独立优化和更新,最终将产线准确率稳定在96%以上。

这种服务化架构还支持模型的A/B测试,某汽车零部件厂商在2026年4月同时部署了两个版本的产线平衡模型,通过云端流量分配功能,在不影响生产的情况下完成模型对比,最终选择优化效果更好的版本,使产线效率提升18%。
真实案例:从概念验证到规模化应用
案例1:某工程机械企业的全球协同制造
这家年产值超500亿元的企业,在2026年面临跨国生产协同的挑战,其德国工厂和长沙工厂的时差导致设计变更同步延迟,曾因图纸版本不一致造成300万元损失,通过部署基于云计算的数字孪生平台,他们实现了:
- 设计数据在云端实时同步,全球团队可同时编辑3D模型
- 产线数字孪生模型跨工厂共享,新产线部署时间从3个月缩短至6周
- 通过云端仿真验证工艺变更,减少物理样机制作80%
该企业CIO透露:"最关键的是云计算的全球节点部署,让我们在慕尼黑、长沙、休斯顿的团队都能以低于20毫秒的延迟访问同一套数字孪生系统。"
案例2:某食品企业的柔性生产转型
这家拥有20条产线的食品企业,在2026年面临小批量、多品种的生产需求,传统产线换型需要48小时,而市场要求这个时间缩短至8小时以内,他们的解决方案是:

- 在云端构建产线数字孪生库,包含所有设备的3D模型和工艺参数
- 通过边缘计算节点实时采集设备状态,为换型方案提供数据支撑
- 利用云计算的优化算法,自动生成最优换型路径和参数配置
实施后,单次换型时间缩短至6.5小时,同时因换型导致的设备故障率下降75%,更意外的是,通过数字孪生模拟,他们发现了3处产线设计缺陷,避免了潜在的200万元损失。
部署中的关键技术决策点
混合云还是公有云?
对于数据敏感型企业,混合云是更稳妥的选择,某军工企业在2026年部署数字孪生时,将核心工艺模型放在私有云,将设备状态监测等非敏感功能放在公有云,这种架构既满足了数据安全要求,又利用了公有云的弹性资源,使整体TCO降低40%。
容器化还是虚拟机?
工业场景对实时性要求极高,某机器人企业在测试中发现,容器化部署的数字孪生服务启动时间比虚拟机快3倍,资源占用减少50%,他们最终选择Kubernetes容器编排平台,实现了模型的快速迭代和自动扩缩容。
时序数据库的选择
绿色产品链与极限运动及绿色城市热度持续上升,相关产业迎来新机遇 工业数据以时序数据为主,某能源企业在对比了InfluxDB、TimescaleDB等方案后,选择了支持SQL查询的TimescaleDB,因为其与现有BI工具的兼容性更好,实施后,数据分析效率提升60%,同时降低了运维复杂度。
云计算与数字孪生的深度融合
在2026年的技术展会上,我们看到两个明显趋势:一是数字孪生与工业元宇宙的结合,某企业已实现通过VR设备直接操作云端数字孪生模型;二是AI大模型与数字孪生的融合,某芯片厂商利用千亿参数模型自动生成产线优化方案,将人工分析时间从周级缩短至小时级。
这些进展背后,始终是云计算架构在提供支撑,从弹性资源调度到全球数据同步,从模型服务化到实时流处理,云计算早已为数字孪生的规模化应用铺平了道路,对于正在探索数字孪生的企业来说,关键不是重新发明轮子,而是理解云计算架构的设计理念,将其与自身业务需求深度结合。
当我们在临港工厂看到那条"透明产线"时,最深刻的感受是:数字孪生不是一项孤立的技术,而是云计算、物联网、AI等多种技术融合的产物,那些真正实现价值的企业,无一不是将数字孪生作为云计算架构的自然延伸,而非额外的技术负担,这种认知差异,或许正是决定数字化转型成败的关键。