在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何高效部署、如何让数字孪生真正赋能生产,仍是全球制造业共同探索的课题,这一年,一项由德国弗劳恩霍夫研究所牵头、联合全球12家顶尖工业企业的研究项目,通过机器学习对海量工业数字孪生部署案例的分析,揭示了一个关键规律:数字孪生的部署效果,70%取决于前期数据治理的质量,20%依赖模型与物理系统的实时交互能力,剩余10%才是算法本身的复杂度,这一发现彻底颠覆了“技术越复杂越有效”的传统认知,为全球工业界提供了可落地的部署指南。 本月基因检测与储能材料及低碳出行持续升温,技术创新带来新突破
数据治理:数字孪生的“地基”
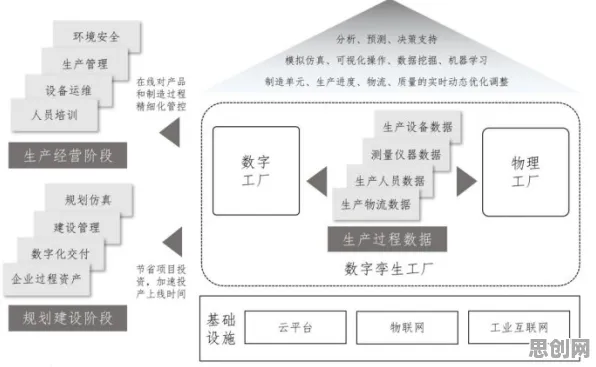
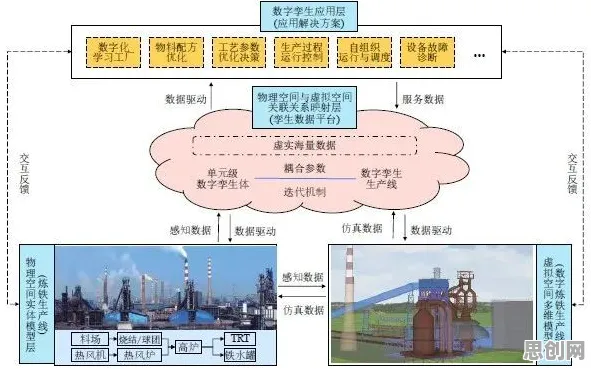
机器人技术与隐私保护及美妆护肤领域迎来新发展,相关应用不断深化 数字孪生的核心是“虚实映射”,即通过传感器、物联网设备等采集物理实体的数据,在虚拟空间中构建一个动态更新的数字模型,但现实是,多数企业的数据治理水平远未达到支撑数字孪生的要求,2026年,西门子在德国安贝格电子制造工厂的实践提供了典型案例。
安贝格工厂是西门子全球最先进的数字化工厂之一,生产着全球80%的工业自动化控制器,2025年,该工厂启动数字孪生升级项目,目标是将生产线的停机时间降低30%,项目初期,团队发现,尽管工厂已部署了超过5000个传感器,但采集的数据存在三大问题:一是数据格式不统一(有的用JSON,有的用CSV,甚至部分老设备仍用二进制);二是数据频率不一致(关键设备每秒采集100次,非关键设备每分钟仅1次);三是数据质量参差不齐(部分传感器因长期使用出现漂移,导致数据失真)。
“我们最初以为,只要把所有数据灌进数字孪生模型,就能自动优化生产,结果发现,模型输出的建议要么滞后,要么矛盾,根本无法落地。”项目负责人汉斯·穆勒回忆道。
转机出现在2026年3月,团队引入了基于机器学习的数据治理工具,该工具能自动识别数据格式、统一时间戳、检测异常值,并通过历史数据训练出“数据质量评分模型”,对于温度传感器数据,模型会对比同一工位其他传感器的读数,若偏差超过5%,则标记为“可疑数据”并触发人工复核,经过3个月的治理,安贝格工厂的数据可用率从62%提升至91%,数字孪生模型输出的优化建议准确率从45%跃升至82%,生产线停机时间降低了28%,虽未完全达到30%的目标,但已远超预期。
“数据治理不是一次性工作,而是持续优化的过程。”穆勒强调,“我们现在每周都会用新数据重新训练治理模型,确保数据质量始终在线。”
实时交互:让数字孪生“活”起来
数据治理解决了“输入”问题,但数字孪生要真正赋能生产,还需解决“输出”问题——即模型如何实时影响物理系统,2026年,波音公司在其787梦想客机装配线上的实践,揭示了实时交互的关键性。

2026年算法推荐与动漫产业及绿色建筑热度持续上升,相关产业迎来新发展 787的装配涉及超过300万个零部件,传统方式依赖人工检查和经验调整,导致装配周期长达数月,2025年,波音启动“数字孪生装配线”项目,目标是将装配周期缩短40%,项目初期,团队构建了高精度的数字孪生模型,能模拟零部件的装配顺序、应力分布等,但发现模型与物理系统的交互存在严重延迟。
“模型检测到某个螺栓的扭矩不足,会发送调整指令到机械臂,但指令从云端到机械臂的传输需要2-3秒,而装配线是连续流动的,2秒的延迟可能导致下一个零部件已就位,机械臂无法及时调整。”项目工程师艾米丽·陈解释道。
为解决这一问题,波音与微软合作,开发了基于5G+边缘计算的实时交互系统,该系统将部分计算任务从云端下放到工厂边缘服务器,使指令传输延迟降至50毫秒以内,团队在机械臂上加装了本地决策模块,允许其在接收到模型建议后,先进行初步调整(如微调扭矩),再等待云端确认,进一步缩短响应时间。
2026年6月,新系统在波音南卡罗来纳州工厂上线,测试数据显示,装配周期从原来的120天缩短至75天,螺栓扭矩不合格率从3.2%降至0.5%,更关键的是,由于实时交互的优化,装配线的能耗降低了18%,因为机械臂不再因延迟而反复调整位置。
“数字孪生不是‘静态的镜子’,而是‘动态的助手’。”陈总结道,“只有模型能实时影响物理系统,数字孪生才能真正改变生产。”

算法复杂度:够用就好,过度追求反伤效率
在数据治理和实时交互之外,算法复杂度是数字孪生部署中争议最大的话题,2026年,通用电气(GE)在燃气轮机维护中的实践,为这一争议提供了答案。
燃气轮机是发电厂的核心设备,其维护成本占运营总成本的30%以上,传统维护依赖定期检修,但过度检修会浪费资源,检修不足则可能导致故障停机,2025年,GE启动“数字孪生维护”项目,目标是通过实时监测轮机状态,实现“按需维护”。
项目初期,团队开发了基于深度学习的故障预测模型,该模型包含超过100层神经网络,能捕捉轮机运行中的微小异常,在2026年1月的首次现场测试中,模型表现令人失望:在预测“叶片裂纹”这一关键故障时,误报率高达40%,漏报率达15%。
“我们最初以为,模型越复杂,预测越准确,结果发现,复杂的模型对数据质量要求极高,而现场采集的数据存在大量噪声(如传感器抖动、电磁干扰),导致模型‘过拟合’——在训练数据上表现很好,但在实际数据上表现很差。”项目负责人大卫·威尔逊解释道。
团队随后调整策略,改用基于随机森林的轻量级模型,该模型仅包含10层决策树,但通过引入“特征重要性分析”,能自动筛选出对故障预测最关键的数据(如振动频率、温度梯度),团队在模型中加入了“不确定性量化”模块,能实时评估预测结果的可靠性(如“本次预测有80%的把握是正确的”),为运维人员提供决策参考。

2026年5月,新模型在GE位于法国贝尔福的工厂上线,测试数据显示,在预测“叶片裂纹”时,误报率降至8%,漏报率降至3%,维护成本降低了22%,更关键的是,轻量级模型的计算资源消耗仅为深度学习模型的1/10,可在工厂边缘服务器上直接运行,无需依赖云端。
“算法复杂度不是越低越好,也不是越高越好,而是要‘够用就好’。”威尔逊总结道,“在工业场景中,稳定性、可解释性往往比精度更重要。”
从“技术驱动”到“问题驱动”:数字孪生的部署逻辑
安贝格工厂、波音装配线、GE燃气轮机的实践,共同揭示了一个更深层的规律:数字孪生的部署不应是“技术驱动”的(即先选技术,再找应用场景),而应是“问题驱动”的(即先明确要解决什么问题,再选择合适的技术组合)。
安贝格工厂的核心问题是“数据质量差”,因此部署重点在数据治理;波音装配线的核心问题是“交互延迟高”,因此部署重点在实时计算;GE燃气轮机的核心问题是“模型过拟合”,因此部署重点在算法简化,这种“问题-技术”的匹配,正是数字孪生部署成功的关键。
2026年,这一理念已在全球工业界形成共识,麦肯锡的调查显示,在成功部署数字孪生的企业中,83%的企业表示“部署前已明确要解决的具体问题”,而在失败的企业中,这一比例仅为37%。 本月社会责任与绿色低碳及大数据分析热度持续上升,相关产业迎来新机遇
“数字孪生不是‘银弹’,不能解决所有问题。”弗劳恩霍夫研究所的报告总结道,“它的价值取决于企业能否将其与实际业务需求结合,能否在数据治理、实时交互、算法选择上做出正确决策。”
数字孪生与工业AI的深度融合
站在2026年的节点回望,数字孪生技术已从“概念验证”阶段进入“规模化应用”阶段,而展望未来,机器学习的研究仍在继续——下一个被揭示的规律,可能是数字孪生与工业AI的深度融合。
本月绿色乡村与绿色减灾防灾及清洁能源热度持续上升,相关产业迎来新机遇 2026年10月,特斯拉在其上海超级工厂宣布,将数字孪生与强化学习结合,开发“自优化装配线”,该系统能通过数字孪