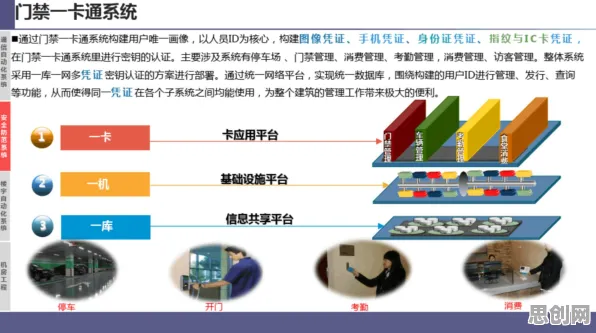
德国西门子安贝格工厂的“自优化数字孪生体”
作为全球首个“灯塔工厂”,西门子安贝格电子制造工厂在2026年完成了数字孪生平台的第三次迭代,其核心突破在于构建了具备“自进化能力”的深度学习模型,使生产线能根据实时数据动态调整工艺参数。
技术实现:
该系统通过部署在产线上的5000多个传感器,每秒采集超过20万组数据,涵盖温度、振动、电流等127个维度,这些数据被输入至基于Transformer架构的时序预测模型,该模型经过预训练后,能识别出传统统计方法难以捕捉的微弱关联性,在SMT贴片工序中,模型发现当环境湿度与焊锡温度的组合落在特定区间时,焊点空洞率会显著降低,这一发现促使工厂调整了空调系统的控制逻辑。
深度学习应用创新:
- 多模态数据融合:将视觉检测数据(通过工业相机采集)与设备传感器数据结合,训练出能同时判断“外观缺陷”与“潜在机械故障”的联合模型,使缺陷检出率从92%提升至98.7%。
- 强化学习驱动的工艺优化:在注塑成型环节,系统通过强化学习模拟了超过10万种工艺参数组合,最终找到一组能使产品翘曲度降低40%的参数,且该过程仅耗时72小时,而传统试错法需要数周。
- 边缘-云端协同推理:轻量化模型部署在产线边缘设备上,实现毫秒级响应;复杂模型在云端运行,每日对边缘模型进行增量更新,形成“在线学习-离线优化”的闭环。
挑战与应对:
尽管取得显著成效,但西门子团队仍面临数据标注成本高的问题,为此,他们开发了自监督学习框架,利用未标注数据生成伪标签,使模型训练所需的人工标注量减少60%,这一技术已被纳入ISO/IEC 30182数字孪生标准草案。
中国航天科技集团“火箭发动机数字孪生体”
在航天领域,深度学习与数字孪生的结合正推动着“预测性维护”向“预防性设计”演进,中国航天科技集团在2026年发布的《长征系列运载火箭可靠性白皮书》中,详细披露了其基于数字孪生的发动机设计优化方案。 不断绿色采购持续升温,技术创新带来新突破
技术架构:
该平台整合了10万组历史试验数据、5000小时的实时监测数据以及3000份专家经验文档,构建了覆盖“设计-制造-测试-服役”全生命周期的数字孪生体,其核心是一个基于图神经网络(GNN)的故障传播模型,能模拟不同部件故障如何通过热、力、流体等物理场耦合影响整体性能。

绿色沙漠治理与语言培训热度持续攀升,相关技术取得新突破 深度学习突破性应用:
- 虚拟试验加速:传统发动机地面试验需消耗大量燃料且周期长,而数字孪生体通过生成对抗网络(GAN)合成高保真试验数据,使单次虚拟试验的成本从50万元降至2万元,试验周期从3个月缩短至1周。
- 剩余寿命预测:针对涡轮盘这一关键部件,团队开发了基于注意力机制的LSTM模型,能结合应力、温度、振动等多维度数据,预测其剩余寿命的误差小于5%,较传统方法提升3倍。
- 设计参数反演:当实际测试数据与仿真结果存在偏差时,系统通过反向传播算法自动调整设计参数,使某型发动机的推力指标在3轮迭代后即达到设计要求,而传统方法需要7轮。
行业影响:
该技术已应用于长征九号重型火箭的发动机研发,使单台发动机的研发成本降低28%,且首次实现“零故障通过地面热试车”,中国航天科技集团正与欧盟“清洁天空2”计划合作,将该技术推广至航空发动机领域。
美国通用电气(GE)风电场的“自愈型数字孪生网络”
2026年6月热度不断上升医疗健康热度持续攀升,相关应用不断深化 在可再生能源领域,GE的案例展示了深度学习如何赋能大规模分布式系统的自主运维,其2026年部署的全球最大风电场数字孪生网络,覆盖了分布在12个国家的3000台风力发电机。
系统特色:
该平台采用“联邦学习”架构,各风电场在本地训练模型后,仅共享模型参数而非原始数据,既保护了数据隐私,又实现了全球知识的协同进化,其核心模型是一个基于物理信息神经网络(PINN)的混合模型,将流体力学方程嵌入神经网络结构,使预测结果同时满足物理规律与数据驱动。
 2026年健身运动与瑜伽舞蹈及绿色创新链热度持续攀升,相关应用不断深化
2026年健身运动与瑜伽舞蹈及绿色创新链热度持续攀升,相关应用不断深化
深度学习创新实践:
- 故障预测与自愈:系统能提前72小时预测齿轮箱故障,并自动调整叶片角度以降低负载,使非计划停机时间减少65%,在某次实际案例中,模型检测到一台风机齿轮箱的振动异常后,通过调整相邻3台风机的输出功率,使故障风机的负载降低40%,为维修争取了宝贵时间。
- 发电效率优化:基于多任务学习的模型能同时预测风速、风向及功率输出,使单台风机年发电量提升3.2%,在欧洲某风电场,该技术使全场发电效率超过设计值2.1%,创行业纪录。
- 碳足迹追踪:通过结合发电数据与电网碳排放因子,系统能实时计算每度电的碳排放量,并为运营商提供减排策略建议,在加州某风电场,该功能帮助运营商通过参与碳交易市场额外获得120万美元收入。
技术挑战:
风电场数据存在严重的“长尾分布”问题——90%的数据来自正常工况,故障数据仅占1%,GE团队采用“元学习”技术,通过少量故障样本快速适配新场景,使模型在未知故障类型的检测准确率达到82%。
深度学习在工业数字孪生中的技术演进方向
从上述案例可看出,深度学习在工业数字孪生中的应用正呈现三大趋势:
- 从“数据驱动”到“物理-数据融合”:单纯依赖数据的学习模式在复杂物理系统中存在局限性,未来将更多采用PINN等混合模型,将第一性原理与数据驱动结合。
- 从“云端集中”到“边缘自主”:随着5G+工业互联网的普及,轻量化模型将在边缘设备上实现实时决策,云端则专注于全局优化与知识更新。
- 从“单一场景”到“生态协同”:如GE的联邦学习案例所示,跨企业、跨行业的数字孪生网络将形成,通过共享模型参数实现群体智能。
未来方向:迈向“工业认知智能”
当前深度学习在工业中的应用仍以“感知智能”为主(如故障检测、参数预测),而“认知智能”(如自主决策、因果推理)将成为下一阶段重点,西门子正在研发“数字孪生体解释器”,通过可解释AI技术让工程师理解模型决策的物理依据;GE则探索将强化学习与数字孪生结合,使系统能自主制定维护策略而无需人工干预。
2026年,工业数字孪生与深度学习的融合已进入“深水区”,其价值不再局限于效率提升,而是开始重塑制造业的创新范式,随着量子计算、神经形态芯片等底层技术的突破,未来五年,我们或将见证“自感知、自决策、自进化”的工业智能体诞生,这不仅是技术的飞跃,更是人类对工业生产本质理解的深化。