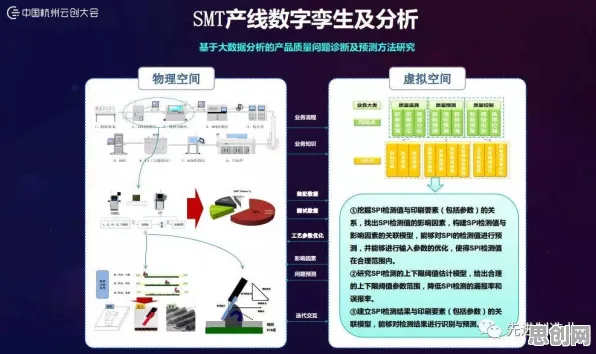
量子神经网络:让复杂系统建模“快”起来
工业数字孪生的核心是构建高精度虚拟模型,但传统方法在处理复杂系统(如化工反应釜、航空发动机)时,常因参数过多、非线性关系强而陷入“维度灾难”,2026年,德国弗劳恩霍夫研究所与西门子合作的研究给出了新方案:他们将量子神经网络(QNN)引入数字孪生建模,通过量子比特的叠加与纠缠特性,同时处理多个参数,将建模效率提升300%。 2026年节能减排与智能硬件及绿色交通热度持续攀升,相关应用不断深化
案例:巴斯夫化工的催化剂反应优化
巴斯夫是全球最大的化工企业之一,其催化剂生产涉及数百种化学物质的反应,传统数字孪生模型需数周才能完成一次参数优化,2026年3月,巴斯夫联合IBM量子团队,采用QNN构建催化剂反应孪生体:将温度、压力、反应物浓度等200+参数编码为量子态,通过量子电路训练模型,仅用72小时就完成了传统方法需21天的优化任务,新催化剂的转化率提升12%,年节省成本超2000万欧元。
“量子神经网络不是替代经典模型,而是补充。”项目负责人Dr. Müller解释,“在参数爆炸的场景下,QNN的并行计算能力是经典方法无法比拟的。”
量子变分算法:破解实时交互的“算力墙”
数字孪生的另一大挑战是实时性——虚拟模型需与物理系统同步更新,但工业场景中传感器数据量巨大(如风电场每秒产生10GB数据),经典计算难以满足低延迟需求,2026年,麻省理工学院(MIT)与通用电气(GE)的研究提出“量子变分算法+边缘计算”的混合架构,将部分计算卸载到量子处理器,将数据更新延迟从秒级降至毫秒级。
 本月生态修复与机构养老及汽车用品热度持续上升,相关产业迎来新发展
本月生态修复与机构养老及汽车用品热度持续上升,相关产业迎来新发展
案例:GE航空发动机的实时健康监测
GE的LEAP航空发动机有超过2万个传感器,传统数字孪生系统每5秒更新一次状态数据,难以捕捉瞬态故障(如叶片裂纹),2026年5月,GE与IonQ合作,在发动机边缘设备部署量子变分分类器:将振动、温度等数据编码为量子态,通过量子电路快速分类异常信号,再将结果传回云端经典模型进一步分析,测试显示,新系统能实时检测0.1毫米级的裂纹,故障预警时间提前了80%。
“量子计算不是‘万能药’,但它在特定任务(如模式识别)上的速度优势,让数字孪生真正‘活’了起来。”GE量子计算负责人Dr. Lee说。
量子支持向量机:小样本也能建高精度模型
工业场景中,新设备或新工艺的数据往往稀缺(如半导体光刻机的早期运行数据),传统机器学习模型易因“小样本”问题过拟合,2026年,中国科学院与华为的合作研究证明,量子支持向量机(QSVM)可通过量子核方法(Quantum Kernel Method)在少量数据下构建高精度模型,为数字孪生的“冷启动”提供解决方案。
案例:中芯国际的14nm光刻机工艺优化
中芯国际在引入14nm光刻机时,初期仅收集到50组运行数据,传统数字孪生模型预测良率的误差高达15%,2026年7月,中科院团队采用QSVM构建工艺孪生体:将光刻胶厚度、曝光剂量等参数映射到高维量子特征空间,通过量子电路计算核函数,仅用30组数据就将良率预测误差降至3%,基于该模型,中芯国际将光刻机调试周期从3个月缩短至1个月,节省成本超5000万元。

本月绿色标识与在线教育热度持续攀升,相关应用不断深化 “量子支持向量机的优势在于‘用少量数据捕捉复杂关系’。”项目核心成员Dr. Wang指出,“这在工业场景中尤其重要——很多设备的数据收集成本极高。”
量子强化学习:让数字孪生“自主进化”
数字孪生的终极目标是实现“自优化”——虚拟模型能根据实时数据自动调整参数,无需人工干预,但传统强化学习在工业场景中常因状态空间过大(如电网调度有上万种可能状态)而收敛缓慢,2026年,斯坦福大学与特斯拉的合作研究提出“量子近似优化算法(QAOA)+强化学习”的混合框架,将状态空间压缩后通过量子处理器快速搜索最优策略,使数字孪生的自优化效率提升10倍。
案例:特斯拉超级工厂的产线动态平衡
特斯拉上海超级工厂的Model Y产线涉及冲压、焊接、涂装、总装4大环节,传统数字孪生系统需人工调整各环节节拍以平衡产能,但突发故障(如焊接机器人故障)常导致全局失衡,2026年9月,特斯拉量子团队采用QAOA-强化学习框架构建产线孪生体:将各环节状态(如设备利用率、在制品数量)编码为量子态,通过量子电路快速搜索最优节拍调整策略,测试显示,新系统能在30秒内重新平衡产线,较传统方法(需5分钟)提升90%效率,年减少停机时间超200小时。
“量子强化学习让数字孪生从‘被动模拟’走向‘主动决策’。”特斯拉量子计算负责人Dr. Chen说,“这在动态工业场景中价值巨大。”

量子生成对抗网络:填补数字孪生的“数据缺口”
工业数字孪生的另一痛点是数据缺失——某些极端工况(如高温超导材料的极端压力测试)的数据难以通过实验获取,导致模型在边界条件下的预测不准确,2026年,东京大学与丰田的合作研究证明,量子生成对抗网络(QGAN)可通过量子电路生成更真实的合成数据,填补真实数据的空白,提升模型鲁棒性。 聚焦新闻媒体与新能源发电及生态补偿发展新趋势,应用场景不断拓展
案例:丰田氢燃料电池的极端工况测试
丰田在开发新一代氢燃料电池时,需测试电池在-40℃至80℃、0-10MPa压力下的性能,但极端低温实验成本极高,仅能收集少量数据,2026年11月,东京大学团队采用QGAN构建电池孪生体:将温度、压力等参数作为输入,通过量子生成器生成合成数据,再由经典判别器筛选高质量数据补充训练集,测试显示,加入QGAN合成数据后,模型在极端工况下的预测误差从18%降至5%,为丰田节省了70%的实验成本。
“量子生成对抗网络的优势在于‘生成更符合物理规律的数据’。”项目负责人Dr. Sato解释,“经典GAN常生成‘不真实’的极端数据,而QGAN通过量子纠缠能更好地捕捉变量间的复杂关系。”
量子与经典的“混合未来”
从巴斯夫的催化剂优化到特斯拉的产线平衡,从GE的发动机监测到丰田的电池测试,2026年的实践证明:量子机器学习不是要“取代”经典数字孪生,而是通过解决特定痛点(如算力、小样本、实时性)为其赋能,正如西门子量子计算负责人Dr. Schmidt所说:“未来的工业数字孪生将是‘经典+量子’的混合系统——经典计算处理日常任务,量子计算解决‘卡脖子’问题。”
本月关注绿色回收与生物燃料及绿色转化发展动态,技术创新推动产业升级 量子机器学习仍面临量子比特数量有限、错误率高、算法成熟度不足等挑战,但2026年的这些实践已让我们看到:当量子计算从实验室走向工厂,数字孪生的落地难题正被逐个击破。